Gérer ses backups avec Borg
Gérer ses backups

Bonjour à toutes et tous 😀
Aujourd'hui les bases de l'admin sys.
Pour ceux qui verront cet article dans un certain temps, un datacenter OVH a brûlé dans la nuit du 10 mars 2021.
J'ai été effaré de voir le nombre d'entreprises qui pleuraient sur twitter qu'ils avaient définitivement perdu leur données.
Lorsque j'apprenais les rudiments de l'informatique, mon mentor m'a posé une simple question qui a hanté mes nuits pendant un certain temps (oui mon sommeil est assez agité 😣)
Qu'est ce que tu fais si je fous un coup de masse dans le serveur de prod et qu'on passe dans 1h à Capital sur M6.
(oui c'est vieux 2016, peut-être 😂)
De cette simple phrase une multitude de choses en est ressorti.
J'ai appris à faire du Puppet, puis du Ansible pour remonter n'importe quel service automatiquement sur une machine neuve.
Mais un service sans données ça sert à rien. Sauf que le coup de masse, il a surement chatouillé les disques durs, et donc les données des services.
Alors que faire ?
La réponse est simple et connu depuis l'aube de l'informatique : faire des backups !!!
Je vous propose de vous montrer ma stratégie de backups que j'ai mis en place au cours des années et qui a bien entendu évoluée au fil du temps.
Et bien allons y 😎
Installer Borg
Il existe une quantité de projets permettant de réaliser des backups.
J'ai choisis arbitrairement le projet Borg, j'étais dans ma période vieux Startrek 😁, le projet est gratuit efficace et je n'ai jamais eu à m'en plaindre.
Si un jour je trouve mieux je referai surement un article dessus.
On vérifie que c'est bien installé
# borg -V
Créer notre premier backup
Il va nous falloir des données, je vous propose ce jeu d'images.
http://images.cocodataset.org/zips/val2017.zip
Ne vous inquiétez pas il est pas vérolé, j'ai vérifié 😋
Avant de pouvoir créer une backup il nous faut un repository. Son rôle va être d'indexer l'historique de backups et leur intégrité ( checksum ).
Il est possible de créer un repository à distance ou sur un disque externe, mais pour les besoins de simplicité de l'article, je vais créer mon backup en local.
Cette commande initialise un nouveau repository. Le paramètre --encryption=repokey défini l'algorithme utilisé pour chiffrer votre repository.
On dézippe notre archive pour avoir plein de fichiers à backuper :D
Puis on créé notre premier backup
--compression=lz4: algorithme de compression des données/opt/backups: chemin du repository::1: nom du backupval2017: dossier à backuper
On aurait pu mettre plus d'un dossier à backuper avec la même commande.
Borg va vous redemander le mot de passe que vous avez entré à la création du repository ( j'espère que vous l'avez toujours 😁 )
Pour visualiser notre backup on peut lancer la commande
# borg list /opt/backups
Enter passphrase for key /opt/backups:
1 Thu, 2021-03-11 20:12:23 [7c19bd1f9bc96c1b3aa8d2d0ef586883d8cf3ae127fb750ea02bde88c747ec59]
Et pour avoir les info d'un backup en particulier
# borg info /opt/backups::1
Enter passphrase for key /opt/backups:
Archive name: 1
Archive fingerprint: 7c19bd1f9bc96c1b3aa8d2d0ef586883d8cf3ae127fb750ea02bde88c747ec59
Comment:
Hostname: backup
Username: root
Time (start): Thu, 2021-03-11 20:12:23
Time (end): Thu, 2021-03-11 20:12:37
Duration: 13.54 seconds
Number of files: 5000
Command line: /usr/bin/borg create --compression=lz4 /opt/backups::1 val2017
Utilization of maximum supported archive size: 0%
------------------------------------------------------------------------------
Original size Compressed size Deduplicated size
This archive: 814.71 MB 813.18 MB 813.57 MB
All archives: 815.68 MB 813.57 MB 813.57 MB
Unique chunks Total chunks
Chunk index: 5011 5011
Grâce à cette commande on peut voir le poids des fichiers présents dans le backup.
On va maintenant rajouter du contenu à notre dossier val2017
On créé une nouvelle version de backup
borg create --compression=lz4 /opt/backups::2 val2017
On peut aller voir les fichiers contenu dans les backups.
Regardons notre premier backup et voyons si on peut récupérer le fichier test.
# borg list /opt/backups::1 | grep text
Enter passphrase for key /opt/backups:
Il n'y est pas pas et c'est bien normal, il n'existait pas quand on a réalisé notre premier backup.
Regardons dans la deuxième version du backup
# borg list /opt/backups::2 | grep text
Enter passphrase for key /opt/backups:
-rw-r--r-- root root 7 Thu, 2021-03-11 21:34:17 val2017/text
Cette fois ci c'est bon 😀
Essayons d'extraire ce fichier
Créons d'abord un dossier de travail et rendons-nous-y.
&&
Puis on extrait notre fichier
borg extract /opt/backups::2 val2017/text
On réalise un diff, pour vérifier la cohérence des données sauvegardées
Aucune différence, cela signifie que le backup c'est bien réalisé et que son extraction aussi. 😀
Rajoutons des nouvelles données
# echo "line 2" >> ../val2017/text
# diff val2017/text ../val2017/text
1a2
> line 2
Cette fois ci on a bien une différence
Revenons dans le dossier parent de work
Puis on créé une version de backup
# borg create --stats --compression=lz4 /opt/backups::3 val2017
)
)
En rajoutant le flag --stats on peut voir que la taille des fichiers modifié, ici 801 B. Ce qui explique la rapidité de backup. Seul les données modifiées sont prise en compte.
On va le faire plusieurs fois pour se simuler divers runs de backups
# echo "line 3" >> val2017/text
# borg create --compression=lz4 /opt/backups::4 val2017
# echo "line 4" >> val2017/text
# borg create --compression=lz4 /opt/backups::5 val2017
# echo "line 5" >> val2017/text
# borg create --compression=lz4 /opt/backups::6 val2017
Si on liste les backup présents vous devriez avoir quelque chose qui ressemble à cela.
# borg list /opt/backups
1 Fri, 2021-03-12 09:37:06 [bf2669e900d0f32bd058681a796882d0aef71e48f0f76487f43424400652cf61]
2 Fri, 2021-03-12 09:37:55 [622988ce6989ef681c59ca5a1dd3c446995bf44c1f6838f2a431277c7e411935]
3 Fri, 2021-03-12 09:38:45 [b1039973a9e7501670e4b15a30e0cbf20a3fc63bd34a20e35e723219a8ac3e68]
4 Fri, 2021-03-12 09:47:34 [5b13478ff317eca07e870a282864095e1c476a5459ec98c43fc9bfa1462e6067]
5 Fri, 2021-03-12 09:47:49 [d26a226f8b5374d4f3cbc1925ee2ef970e2ca05d81d7f5a2817bb06ec7f4a1e2]
6 Fri, 2021-03-12 09:48:15 [3762d2eebd9670a01d3f3334d6d9be985735973f52db3104b1e1eb7adb5cfc27]
Bien essayons d'extraire notre backup en revision 3 et 6.
# borg extract --stdout /opt/backups::3 val2017/text > text.3
# borg extract --stdout /opt/backups::6 val2017/text > text.6
Si on fait le diff
# diff text.3 text.6
2a3,5
> line 3
> line 4
> line 5
Et si je supprime le backup de la version 3, il se passe quoi pour la version 6 ?
# borg delete /opt/backups::3
# borg list /opt/backups
1 Fri, 2021-03-12 09:37:06 [bf2669e900d0f32bd058681a796882d0aef71e48f0f76487f43424400652cf61]
2 Fri, 2021-03-12 09:37:55 [622988ce6989ef681c59ca5a1dd3c446995bf44c1f6838f2a431277c7e411935]
4 Fri, 2021-03-12 09:47:34 [5b13478ff317eca07e870a282864095e1c476a5459ec98c43fc9bfa1462e6067]
5 Fri, 2021-03-12 09:47:49 [d26a226f8b5374d4f3cbc1925ee2ef970e2ca05d81d7f5a2817bb06ec7f4a1e2]
6 Fri, 2021-03-12 09:48:15 [3762d2eebd9670a01d3f3334d6d9be985735973f52db3104b1e1eb7adb5cfc27]
Notre version 3 est bien supprimé.
Quand est-il de la version 6. Est-elle corrompu ?
Essayons
# borg extract --stdout /opt/backups::6 val2017/text > text.6.2
Si on fait un diff:
# diff text.6 text.6.2
Aucune différence, ce qui signifie que l'on peut supprimer des vieilles versions de backups sans que cela n'influe sur les backups précédants.
On va tirer profit de cette particularité pour se débarasser des vieux backup qui polluent le disque.
borg prune --keep-last 3 /opt/backups
Si on liste les backups:
# borg list /opt/backups
4 Fri, 2021-03-12 09:47:34 [5b13478ff317eca07e870a282864095e1c476a5459ec98c43fc9bfa1462e6067]
5 Fri, 2021-03-12 09:47:49 [d26a226f8b5374d4f3cbc1925ee2ef970e2ca05d81d7f5a2817bb06ec7f4a1e2]
6 Fri, 2021-03-12 09:48:15 [3762d2eebd9670a01d3f3334d6d9be985735973f52db3104b1e1eb7adb5cfc27]
On a plus que nos 3 backups ( les plus récents ).
Exporter les backups
Il est possible d'exporter un backup sous la forme d'une archive.
borg export-tar --tar-filter="gzip -9" /opt/backups::6 backup.6.tar.gz
Puis on vérifie que l'archive contient bien ce qu'il faut
# tar -axf backup.6.tar.gz val2017/text -O
line 1
line 2
line 3
line 4
line 5
Notre archive contient bien ce que l'on veut. :D
Automatisation du process de backup
Borg est sympathique mais est un peu trop manuel à mon goût c'est la raison pour laquelle nous allons rajouter une couche d'automatisation sous la forme d'un projet python appelé borgmatic.
Son rôle est de gérer la configuration du backup et d'automatiser les tâches d'avant et après backup comme le montage de disque ou l'éxécution de borg prune pour nettoyer les anciens backups ou chaîner d'autres opérations.
En parlant de configuration borgmatic est fourni avec un générateur.
generate-borgmatic-config
Celle ci va créer le fichier /etc/borgmatic/config.yml
Il faut modifier quelques lignes:
location:
source_directories:
- /root/val2017
repositories:
- /opt/backups
storage:
encryption_passphrase: "test"
archive_name_format: '{hostname}-backups-{now:%Y-%m-%dT%H:%M}'
retention:
keep_daily: 7
prefix: '{hostname}-backups-'
consistency:
checks:
- repository
- archives
prefix: '{hostname}-backups-'
Le keep_daily permet de conserver 7 jours de backups sur la machine.
Pour plus d'informations concernant les diverses options, je vous laisse consulter la documentation de référence.
Pour exécuter un backup rien de plus simple:
borgmatic
Cette commande va effectuer plusieurs choses.
D'abord elle effectue un nettoyage des anciens backups
borg prune --keep-daily 7 --prefix {hostname}-backups /opt/backups
Puis effectue le backup à proprement parlé
borg create /opt/backups::{hostname}-backups-{now:%Y-%m-%dT%H:%M} /root/val2017
Avant de vérifier l'intégrité du dépôts d'archives ainsi que les archives elles même.
borg check --prefix {hostname}-backups /opt/backups
Automatisons l'automatisation
Ok, c'est bien beau tout ça mais je vais pas aller dans la console taper
borgmatictous les jours moi !
Effectivement tu ne va pas le faire. On va automatiser tout ça via l'utilisation de systemd, de services et de timers.
Tout d'abord le service borgmatic.service
[Unit]
borgmatic backup
network-online.target
network-online.target
true
[Service]
oneshot
true
no
yes
yes
yes
yes
yes
yes
yes
yes
yes
AF_UNIX AF_INET AF_INET6 AF_NETLINK
yes
yes
yes
native
@system-service
EPERM
full
CAP_DAC_READ_SEARCH CAP_NET_RAW
19
batch
best-effort
7
100
no
0
sleep 1m
systemd-inhibit --who="borgmatic" --why="Prevent interrupting scheduled backup" /root/.local/bin/borgmatic --syslog-verbosity 1
Puis le timer borgmatic.timer
[Unit]
Run borgmatic backup
[Timer]
daily
true
[Install]
timers.target
Et on installe tout ça
Si tous se passe bien vous devriez avoir ceci:
# service borgmatic status
; ; )
)
Maintenant chaque jour la commande borgmatic sera exécutée à votre place :D
Upload du backup
Fantastique et maintenant en quoi répond à la problématique de "mon serveur est détruit", les backups sont toujours sur la machine, non ?
Excellente remarque, on va justement dans cette partie adresser ce problème.
Pour cela je vous propose d'utiliser Amazon Glacier qui a pour principale intérêt d'être gratuit en transfert entrant.
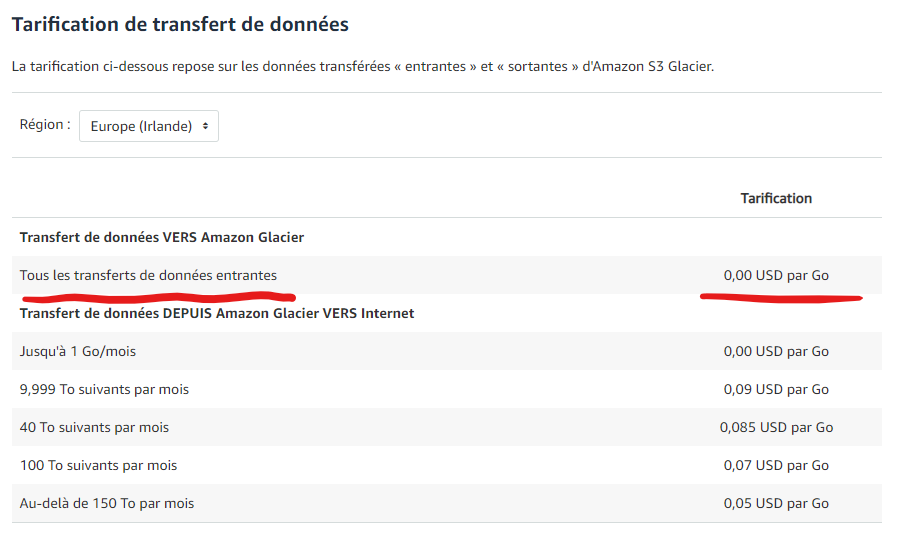
Le stockage lui est payant mais les sommes sont minimes.
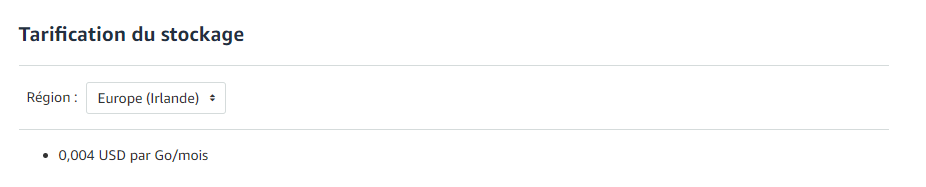
Ce qui est une chose plutôt intéressante. :D
Il est aussi possible d'utiliser un autre provider comme Scaleway par exemple. Ne connaissant pas du tout le produit, je vais me renseigner sur le sujet et on fera peut-être alors un nouvel article dessus :)
Pour utiliser Glacier il vous faut un compte AWS qui peut être créé gratuitement.
Création d'un utilisateur de backup
Une fois cela fais il faut que vous vous connectiez à la Console.
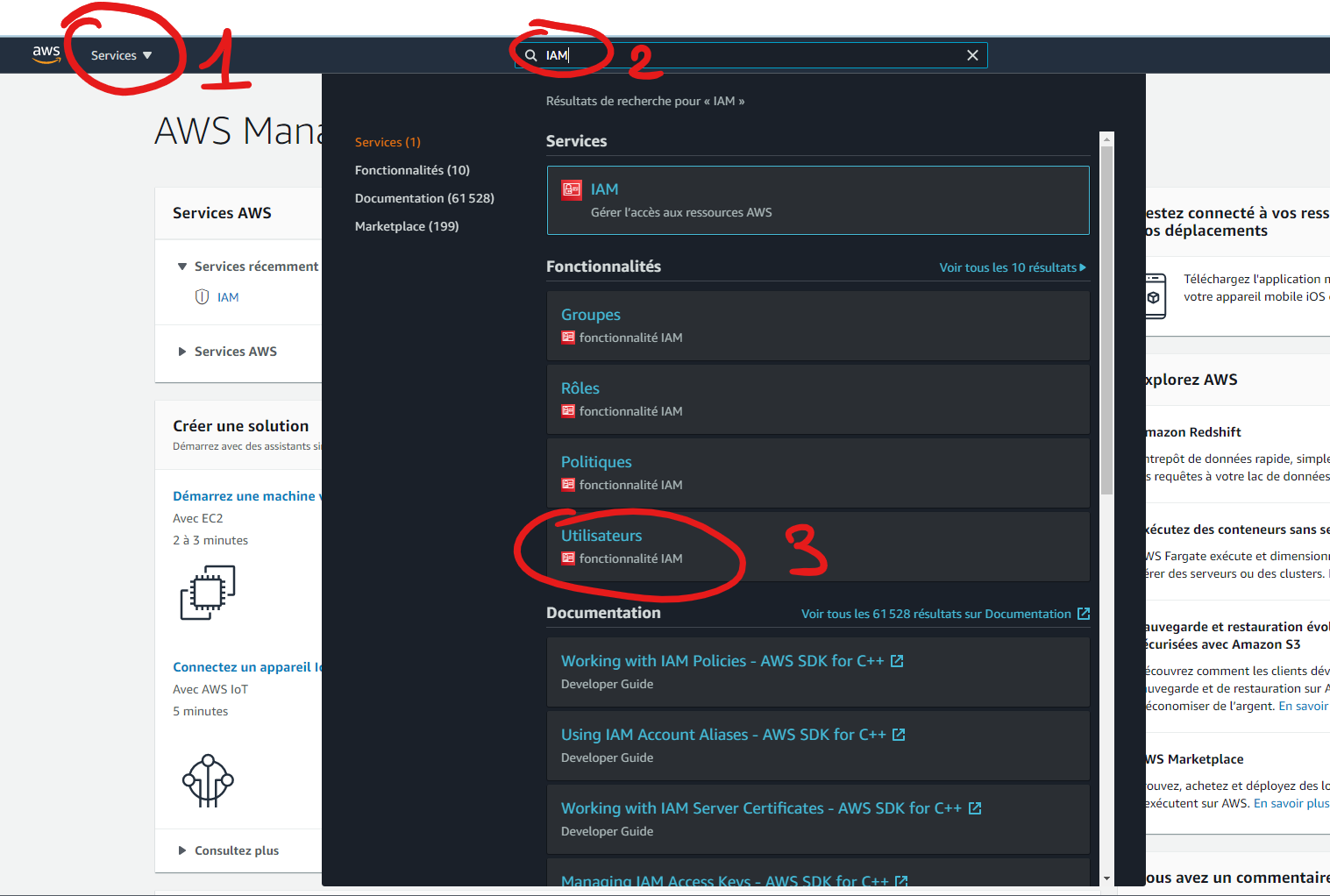
Puis taper dans le moteur de recherche IAM (2) et sélectionné "Utilisateurs" (3)

Appuyer sur le bouton de création d'un nouvel utilisateur.
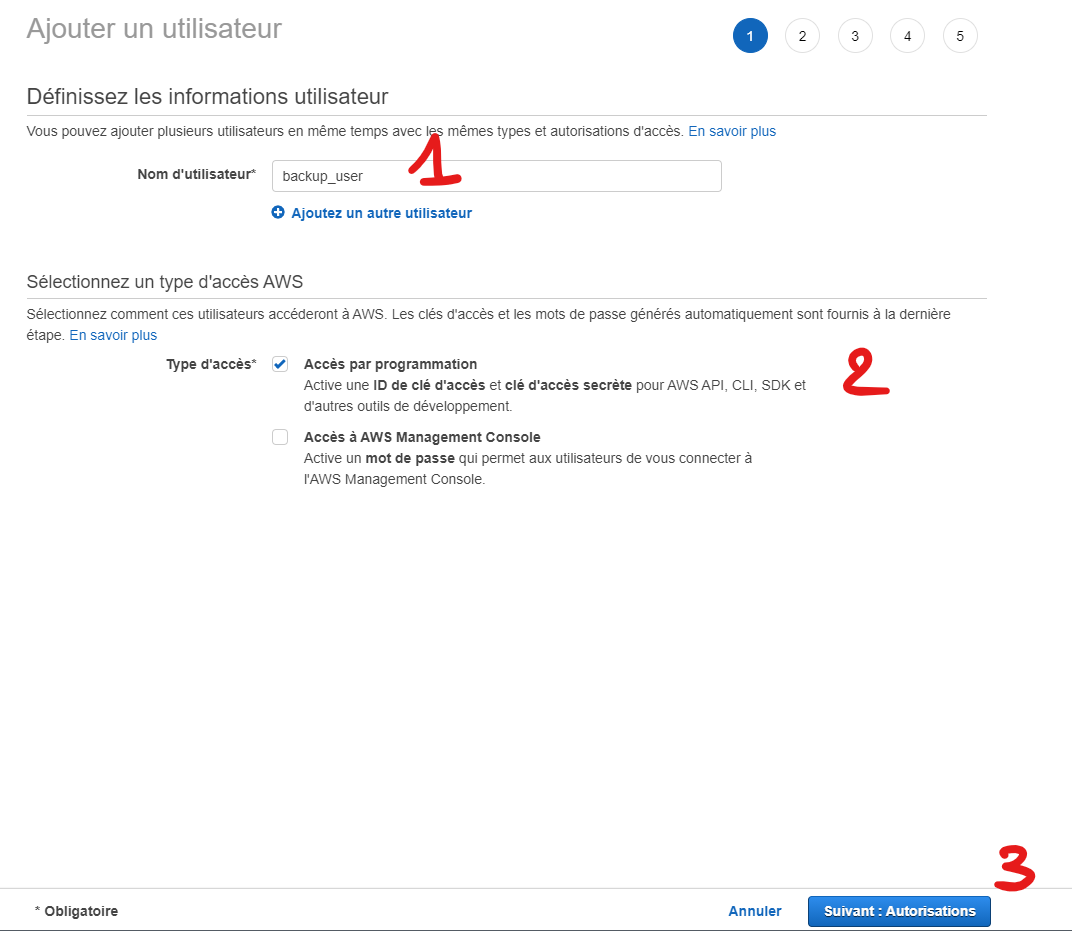
Donnez un nom à votre utilisateur (1) et un droit API (2) puis Suivant (3)
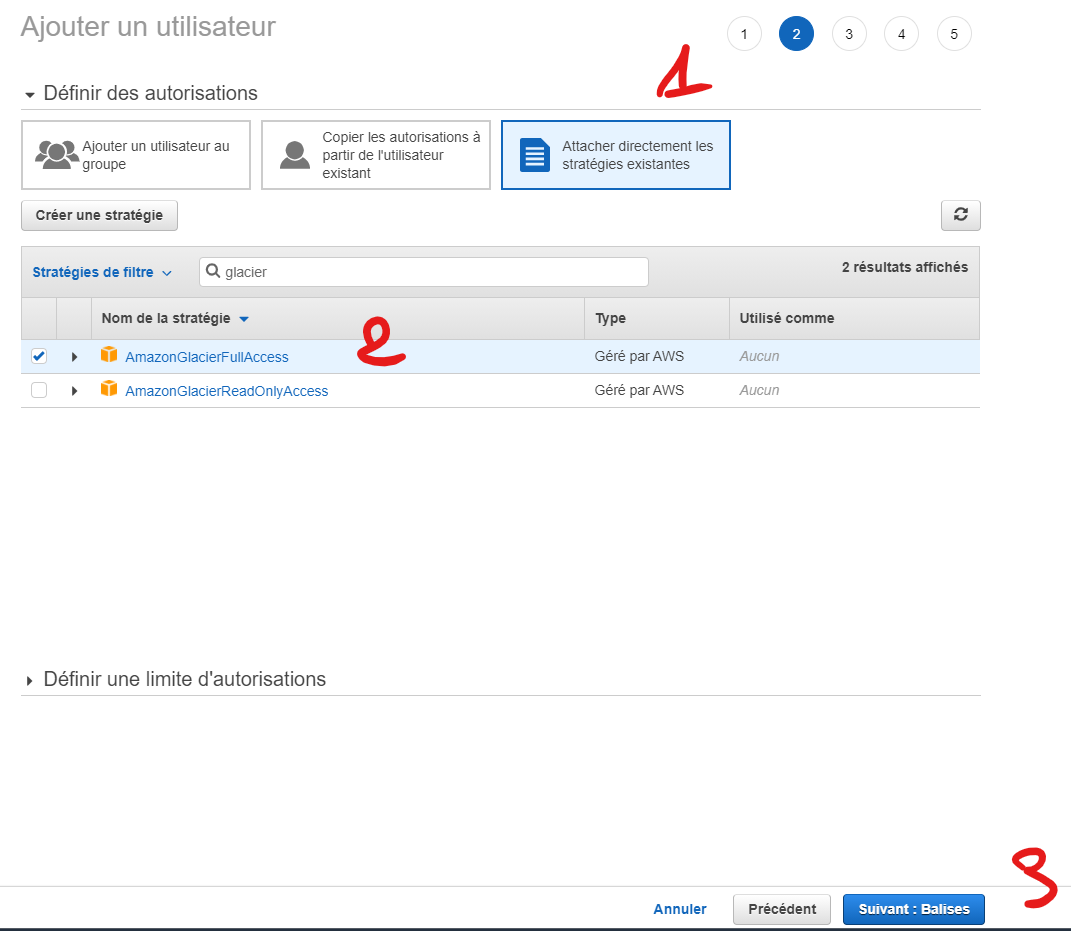
Afin de permettre les droits en écritures sur le Vault Glacier, vous devez lui attacher la stratégie correspondante (1) , puis cocher le AmazonGlacierFullAccess (2).
Vous pouvez alors faire Suivant (3).
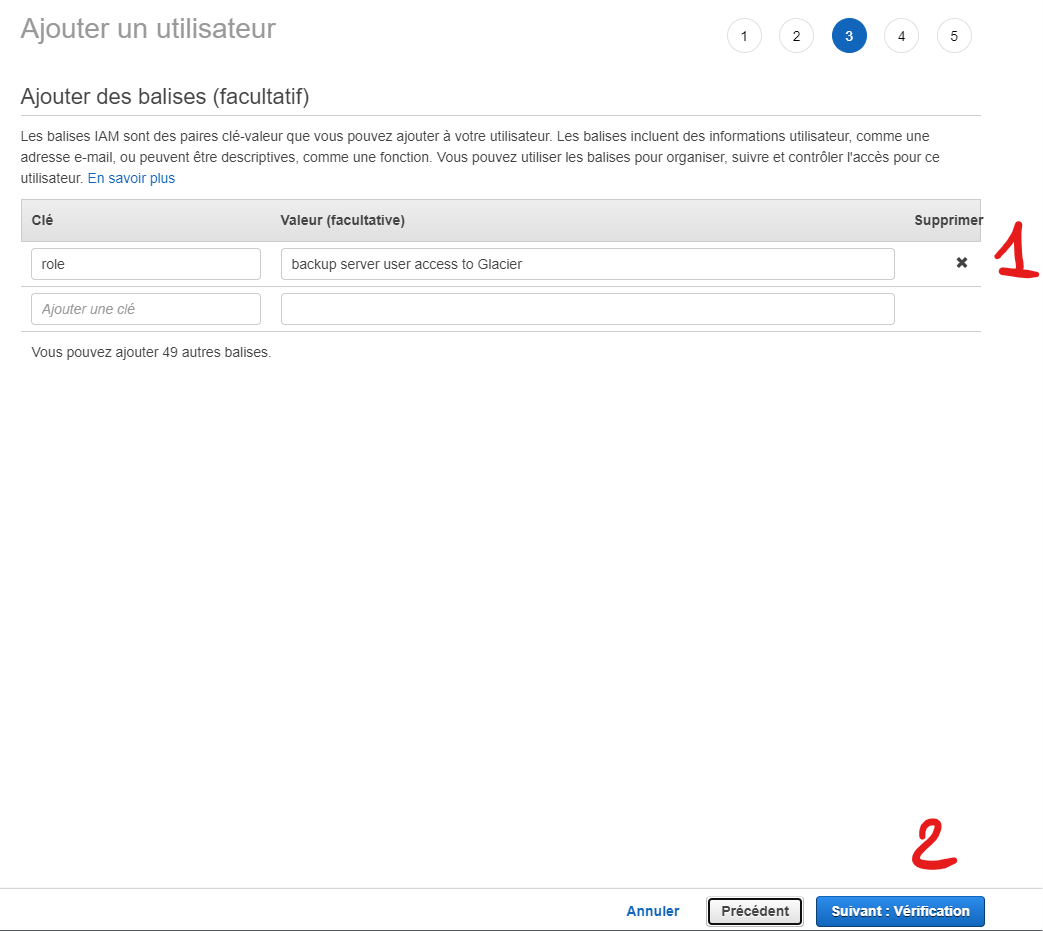
Vous pouvez optionnellement rajouter des labels appelés des balises (1), puis Suivant (2)
Suivant !
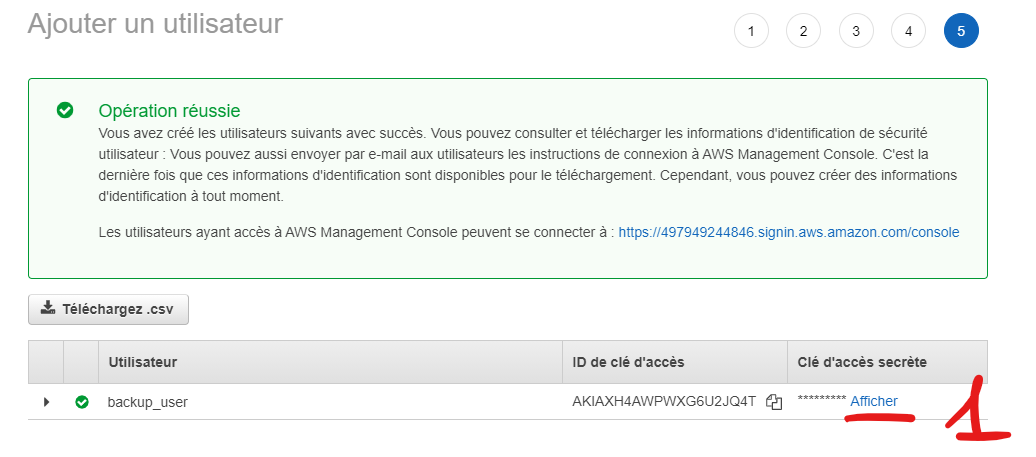
Important !
Téléchargez le CSV ou copier avec le mot de passe (1), il ne vous sera plus jamais remontré !!
Maintenant
Création d'un Vault Glacier
Nous allons maintenant créer le Vault à proprement parlé.
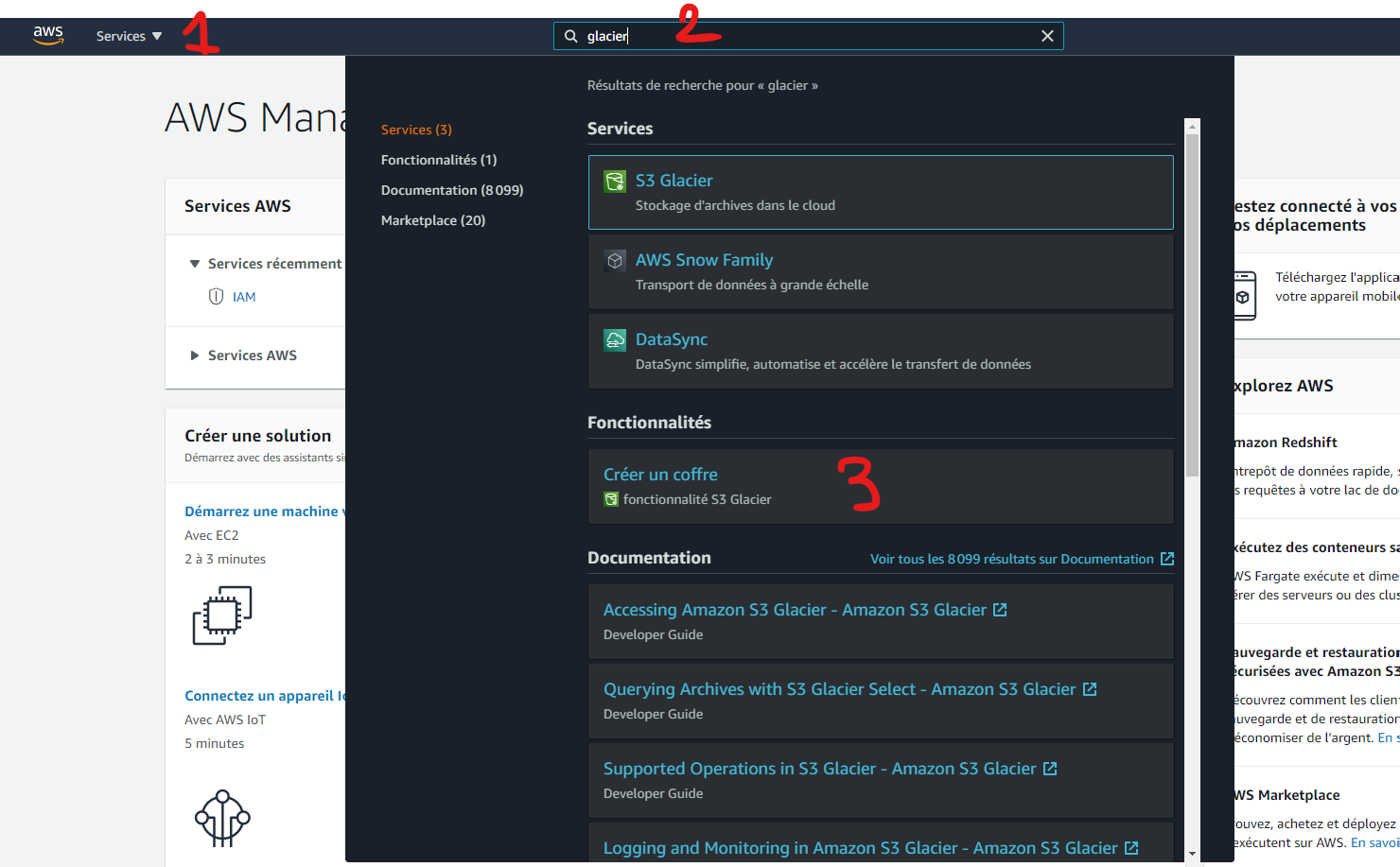
Puis taper dans le moteur de recherche Glacier (2) et sélectionné "Créer un coffre" (3).
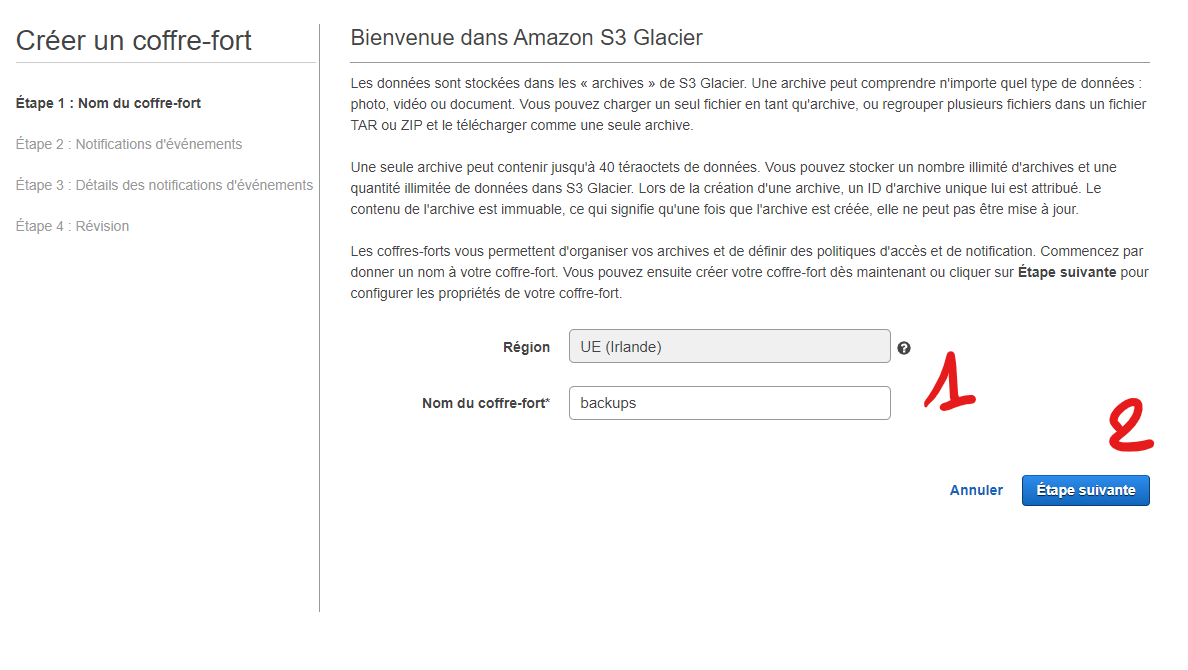
Donnez un nom à votre Vault (1) puis "Suivant" (2).
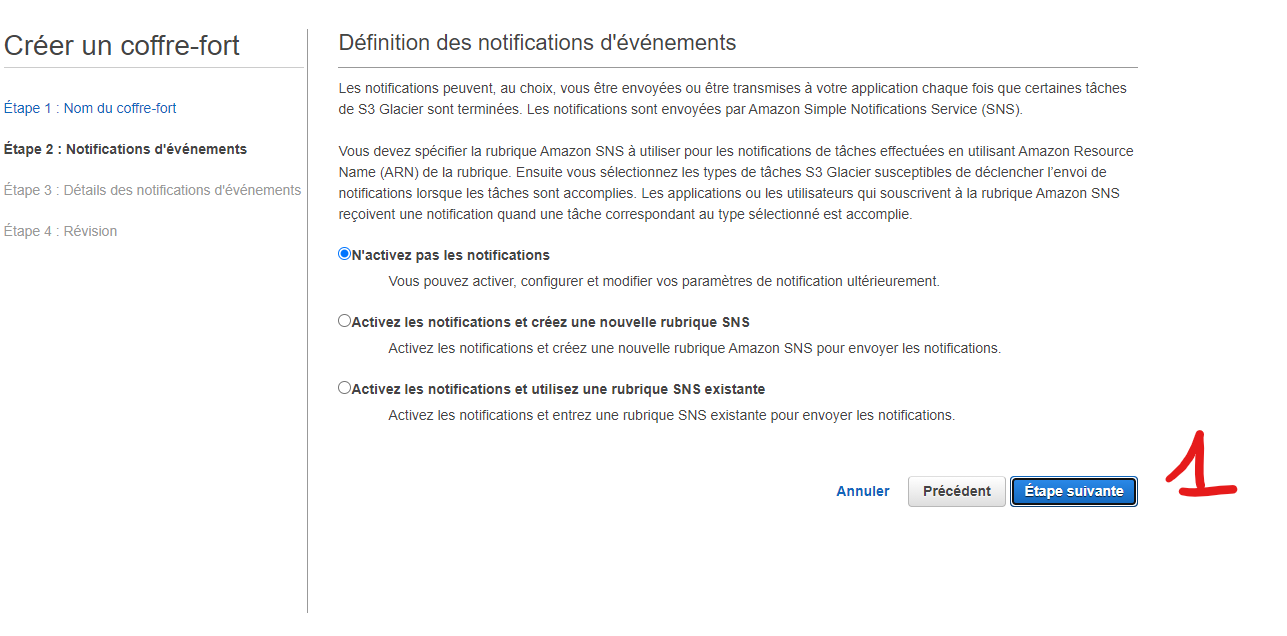
Pas de notification nécessaire.
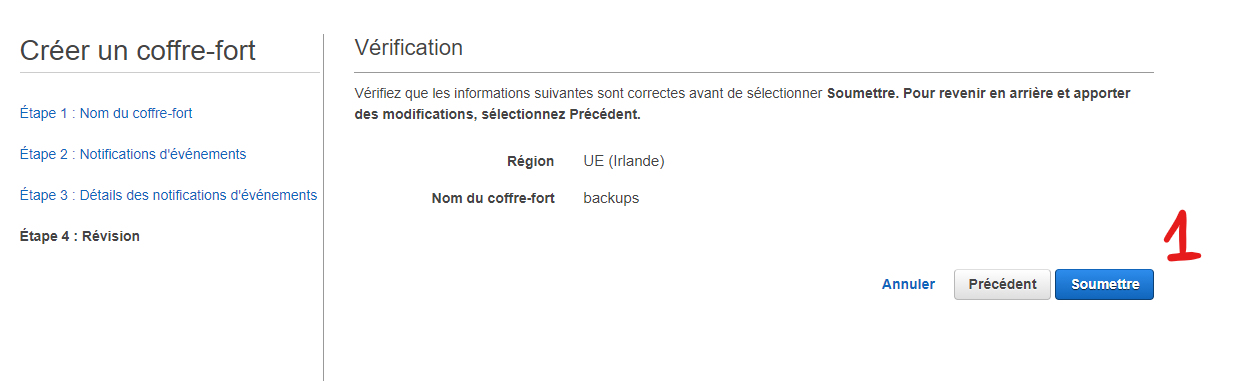
Puis terminé !
Félicitation vous avez créé votre premier Vault ! 🎉
Identification AWS
Nous allons stocker les identifiants dans un fichier qui se situera dans le home de l'utilsateur qui lancera la procédure de backup.
Ici /root/.aws/credentials
[default]
foo
bar
Modifiez foo et bar avec les identifiants de l'utilisateur que vous avez créé sur AWS.
On installe boto3, ici directement, mais vous pouvez parfaitement le faire dans un virtualenv.
Pour nous faciliter l'uplolad vers un vault, j'ai écris un script python utilisant boto3.
J'ai nommé ce script upload_to_glacier.py
#!/usr/bin/env python3
=
=
=
=
=
On créé aussi un script qui a pour rôle de créer une archive du dernier backup connu, de lancer le script python ci-dessus. Et enfin de nettoyer l'archive qui a été correctement uploadé.
On va appellé ce script python au travers de notre bash.
J'ai appelé ce script archive_and_run_glacier_upload.sh
#!/usr/bin/env bash
ARCHIVE=/tmp/-.tar.gz
On créé un dossier de travail
mkdir -p /opt/work
Puis on y déplace nos deux scripts
mv archive_and_run_glacier_upload.sh upload_to_glacier.py /opt/work/.
Puis on donne les droit d'éxécution à ces fichiers
chmod u+x /opt/work/upload_to_glacier.py
chmod u+x /opt/work/archive_and_run_glacier_upload.sh
On va ensuite déclencher un upload vers Glacier toutes les semaines
Tout d'abord le service glacier.service
[Unit]
Upload archive to glacier
network-online.target
borgmatic.target
network-online.target
true
[Service]
oneshot
true
no
yes
yes
yes
yes
yes
yes
yes
yes
yes
AF_UNIX AF_INET AF_INET6 AF_NETLINK
yes
yes
yes
native
@system-service
EPERM
full
CAP_DAC_READ_SEARCH CAP_NET_RAW
19
batch
best-effort
7
100
no
0
sleep 1m
/opt/work/archive_and_run_glacier_upload.sh
Puis le timer glacier.timer qui se déclenche hebdomadairement
[Unit]
Run glacier upload
[Timer]
weekly
true
[Install]
timers.target
On installe tout ça
Si tout se passe bien
# systemctl status glacier
● glacier.service - Upload archive to glacier
Loaded: loaded (/etc/systemd/system/glacier.service; static; vendor preset: enabled)
Active: inactive (dead)
TriggeredBy: ● glacier.timer
Vous pouvez même visualiser lorsque le prochain run se fera
# systemctl status glacier.timer
● glacier.timer - Run glacier upload
Loaded: loaded (/etc/systemd/system/glacier.timer; enabled; vendor preset: enabled)
Active: active (waiting) since Mon 2021-03-15 19:23:48 UTC; 15min ago
Trigger: Mon 2021-03-22 00:00:00 UTC; 6 days left
Triggers: ● glacier.service
Mar 15 19:23:48 backup systemd[1]: Started Run glacier upload.
Et bien on arrive au bout :D
Ne soyez pas surpris de ne rien voir sur l'interface de la Console AWS de Glacier. Toutes les actions sont asynchrones.
En clair AWS réalise les opérations d'upload quand il le désire, par exemple j'ai écris ces lignes à 14h, mes backups ont été visibles à 0h44. Ils s'appellent ça faire l'inventaire.
Conclusion
Beaucoup de choses aujourd'hui, ( comme d'habitudes on va me répondre 😁 ).
On a appris à réaliser des backups efficaces, à les automatiser au travers de systemd et à les exporter sur AWS.
Un sujet que l'on n'a pas abordé et qui pourrait faire l'objet d'un article à lui tout seul est la récupération des backups de AWS.
Si ça vous intéresse je pourrai l'écrire dans l'avenir. :)
Un autre sujet qui n'a pas été couvert c'est le test de vos backups, c'est très bien de savoir sauvegarder, mais si les données sont corrompus c'est un peu une perte de temps. Là aussi un article supplémentaire pourrait voir le jour tellement le sujet est vaste et intéressant. :D
Je vous remercie de m'avoir lu et je vous dit à la prochaine 😊
Ce travail est sous licence CC BY-NC-SA 4.0.