YAGW : Yet another git workflow

A partir du moment où j'ai dû faire de la programmation à plusieurs ( mes personnalités multiples ça compte pas 🤪 ).
Un problème s'est toujours posé: comment ne pas se marcher sur les pieds.
Durant ma courte expérience de dev, j'ai déjà tester plusieurs principes tout fait. Je vais vous avouez que je n'ai été convaincu par aucun d'entre eux.
Avant de présenter YAGW. Je vais faire un tour d'horizon de ce que je connais pour les avoir essayés.
No Flow : YOLO ( -8000 av JC )
Tout le monde écrit dans la master et personne ne fait de branche, let's rock baby !

Il peut y avoir des tags mais c'est pas dit.
Avantages
- Pas de charge mentale
- Idéal lorsqu'on est seul
- Très automatisable
Désavantages
- C'est mort pour collaborer
- Tester c'est douter
Bon maintenant qu'on a évacué le troll, passons aux choses sérieuses. 😉
Gitflow : le premier arrivé (2010)
Quand le développement a commencé à se structurer autours de git. Une méthode appelée gitflow a vu le jour. Elle se voulait apte à résoudre toutes les problématiques ou presque.
Mais comme toujours la flexibilité vient souvent avec son lot de complexités. Et ça n'a pas raté. Gitflow est véritablement une usine à gaz, voyez plutôt:
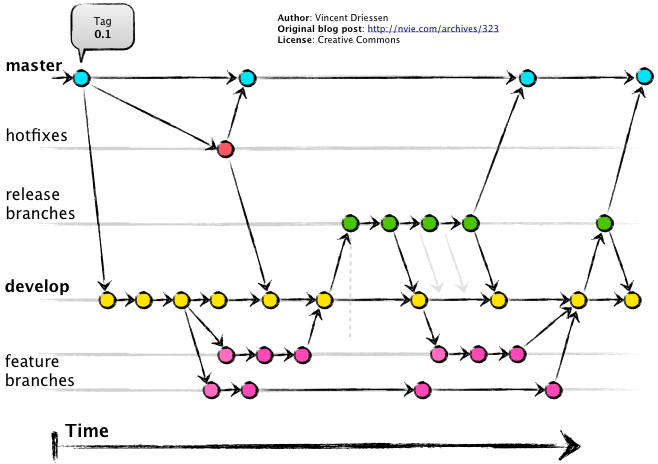
Oui c'est pas évident du tout.
Pour expliquer la philosophie: elle part du principe que la branche master ne sert qu'à tagger un historique.
Cette master est isolée du reste par des branches éphémères appelées releases.
Le coeur de la vie du projet est situé sur la branche develop, celle ci doit impérativement contenir tous les commits du projet.
De cette branche on va dériver tout une série de branches. Celles ci sont appelées des branches de features/X. Elles peuvent n'avoir que 2 fins. Mourrir ou être mergées dans la develop.
Lorsque l'on désire créer une release, on va dériver à partir d'un commit de la develop une branche release/X, ce X peut représenter un hash de commit un nom explicite ou une version. 3 destins attend cette branche: mourrir, être remergé dans la develop après modifications. Ou être mergé à la fois dans la master et dans la develop.
Dans la littérature ils appellent ça des back-merge. Je trouve personnellement cette solution très peu élégante. Et surtout difficilement intégrable dans un environnement comme gitlab/github.
Une dernière série de branches sont appelées hotfix, elles sont destinées à être mergées à la fois dans la master et dans la develop. Elle permette de corriger des bugs critiques qui seraient passés lors d'un merge d'une branche release dans la master. Il est impératif que la develop contiennent l'intégralité des hotfix qui ont été mergées dans la master.
Si ces processus de back-merge des hotfix vers la develop ou des commits ayant eu lieu sur les branches de release vers la develop sont oubliés ou qu'une automatisation échoue. La develop et la master vont finir par être disjointes. Ce qui pourrait causer plus tard des soucis de merge de branche release/.
Un autre point que je trouve vraiment dérangeant c'est le manque total d'élégance et de lisibilité d'un arbre ayant subit le principe gitflow. Je suis pas le seul
Voilà le résultat d'un arbre après quelques temps d'utilisation de gitflow.

Biensûr il est possible de rendre ça lisible avec git log --graph --oneline --first-parent develop. Mais je ne pense pas que ça soit un bon point de devoir changer de référentiel pour comprendre un problème.
Avantage
- Il permet de gérer plusieurs versions en production
Désavantages
- Beaucoup trop complexe
- Peu automatisable et intégrale dans une CI sans faire des concessions
- Un arbre de commit très peu lisible
Github Flow : Une simplification drastique (2011)
A l'époque déjà certaines personnes n'avait pas le besoin de la complexité de gitflow, dans cet article.
Oui à l'époque chez github ils étaient 30 😁.
Ce workflow se base sur 6 grands principes:
- Tout ce qui est sur la master est déployable et déployé.
- Tout ajout à la master doit préalablement passer par une branche lisiblement nommée dérivée de la
master - Le développeur travail jamais sur la
mastertoujours sur sa branche - Lorsqu'il doit collaborer avec une autre personne, une pull-request doit-être crée.
- Une fois la pull-request vérifiée, le reviewer merge la branche sur la
master - Si c'est mergé ça doit être déployé!
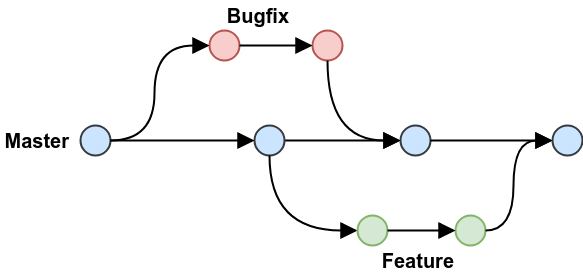
C'est déjà plus clean 🤩.
Par contre chaque merge de feature peu planter la master si le café du matin n'était pas assez fort. Il faut donc un code très automatisé en terme de vérification pour éviter de déployer des régressions.
J'appellerai ça le déploiement sans filet 🤪.
Avantages
- Très facile à automatiser dans une CI/CD
- On peut lire le graphe de commit !
Désavantages
- Dépendant du système externe des pull-requests
- La master peut être instable à tout merge
- Non adapté à des cycles de déployement ( sprint )
- Non adapté au maintient de plusieurs versions
GitLab Flow : Automatisation à tout prix (2014)
Dans un article paru en 2014. Les équipes de GitLab nous exposent leur manière de procéder.
Ce processus s'appuie sur 11 règles:
- Ne jamais faire de commit direct sur la master
- Tout commits doit bénéficier de tests automatisés, pas seulement sur la branche
master - On lance tous les tests, tout le temps. Pas seulement ceux de la feature que l'on développe
- On fait la code review avant le merge sur la
masterpas après. - Tout est automatisé
- Les tags doivent être apposés par un humain, pas un robot
- Une release = un tag
- Un commit partagé est considéré immutable, jamais de rebase!
- Le référentiel est la
master, tout le monde commence d'elle, et finit à elle - Les bugs sont fixés d'abord sur la
masterpuis sur les releases. - Soignez vos messages de commits !
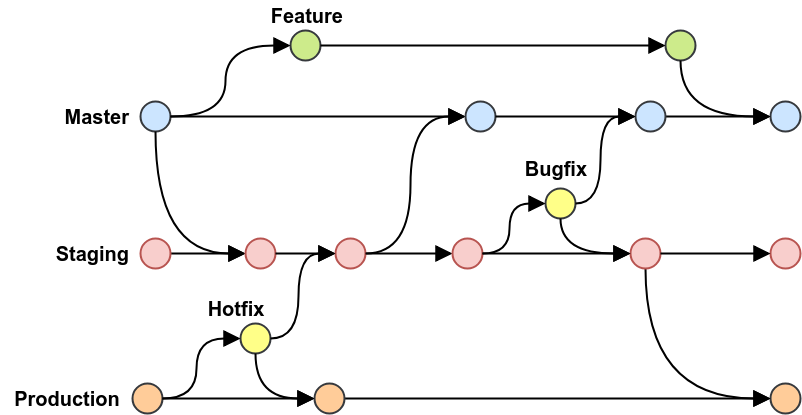
Si l'on ne prend que la partie haute du schéma, on retrouve le GithubFlow.
Ce qui diffère ce sont les deux branches staging et production. Celles ci, ne sont et doivent pas être modifiés par un humain. Elles servent à déployer des environnements différents avec des niveaux de criticité différents.
La master est destiné aux développeurs, le but ultime n'est pas de la flinguer. Mais si elle est sur le carreau cela n'impacte entre guillemets que les devs.
La staging est plus critique, ce qui est en staging est mis à disposition des équipes internes. Un down peu impacter le travail des équipes de QA et de produits. Elle ne devrait pas avoir de down mais l'erreur est humaine.
Les bugs post-release sont corrigés dans cette environnement, autrement dit les hotfix internes, dérivent de la staging et sont reportées dans la master puis dans la staging.
Le lourd pour finir, la production, jamais de down, tout ce qui est sur production a obligatoirement passé par le staging!
Comme d'habitude si un bug critique est découvert et qu'il faut absolument déployer en urgence. Il est possible de générer des branches de hotfix depuis la production et de les merger à la fois dans staging puis production.
Une fois le hotfix dans la staging, il faut encore la faire descendre dans la master.
Avantages
- Par construction, automatisable dans une CI
- Un arbre de commit très propre
- Donne un filet de sécurité avant de déployer des régressions
Désavantages
- Se base sur un code très automatisé à la base, TU, tests de régression, etc...
- N'est pas conçu pour gérer plusieurs versions en production en parallèle
- Les hotfix sont gérées d'une manière très peu élégante
YAGW : Mon approche du problème
Tout d'abord énonçons le contexte.
Je travaille sur un projet basé sur un sytème de release cadencé de 3 semaines.
La base de code est en début d'automatisation des tests ( il y a des TU mais très localisés ). Aucun tests e2e. Et l'automatisation de la CI est encore balbutiante.
Notre environnement de collaboration est GitLab et nous utilisons la version Core de celle ci. Nous utilisons déjà les issues et les merge-request.
L'idée est d'arriver à une séparation d'environnement de production et de développement, tout en s'assurant de gestion plus élégante des hotfix que ce que GitLab Flow peut proposer.
La CD devra être capable de déployer des environnement différents en fonctions des contextes d'utilisation.
Mon système se base sur 10 principes:
- Tout ce qui est sur la master est déployable en production
- Tout ce qui est sur la develop est testable par des équipes non techniques et non déployé publiquement
- Un humain ne peut pas faire de commit ni sur la
developni sur lamaster - Chaque release part de la master et se finit dans la develop
- Chaque sprint possède sa branche de release
- Chaque feature possède sa branche feature
- Toute feature avant d'être mergé dans la release passe par une merge-request
- Toute release avant d'être mergé dans la develop passe par une merge-request
- Tout merge de develop vers master se fait par merge-request
- Les hotfix dérive de develop et finissent dans develop
- Les branches master et develop sont immutables, un commit ajouté n'est jamais modifié encore mois supprimé
- Les branches de release peuvent être rebase sur la develop si besoin
- Les déploiements de production sont conditionnés par l'ajout d'un tag
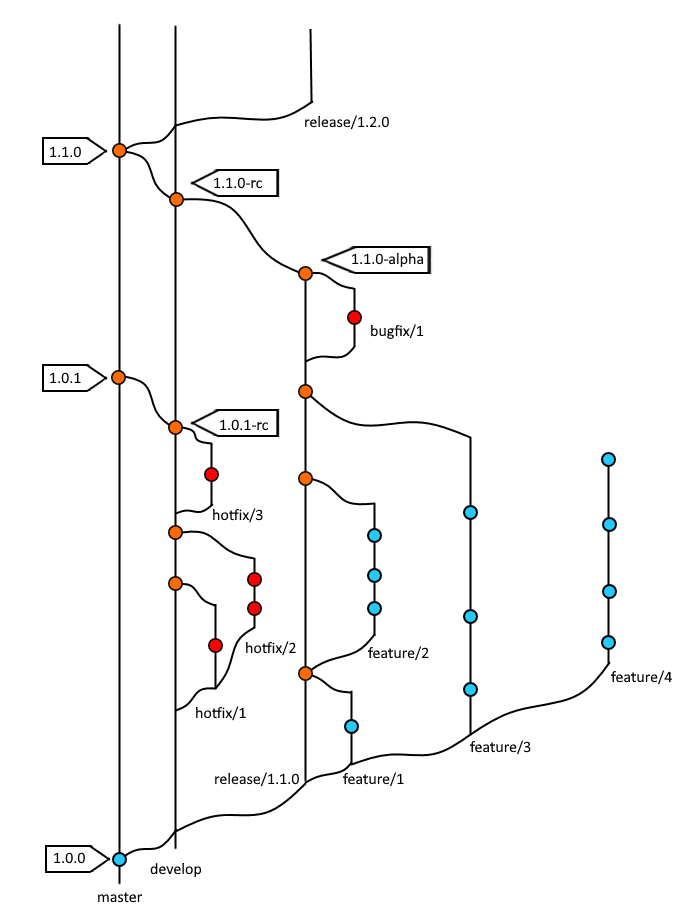
Quelques précisions concernants certains points:
Le tag 1.0-fix3 est nécessaire pour des cause de process lecacy qui ont besoin d'un tag pour fonctionner.
Il est donc autoriser de tagger les commits de la develop à des fins de pre-release internes.
La branche feature/4 est une sorte d'anomalie dans le processus. Elle peut soit être dû à un développeur qui fini ses tickets de la release courante et qui s'attaque en avance de phase à des fonctionnalité de la release suivante. Soit c'est une feature qui a pris plus de temps que le sprint et qui n'est donc pas terminée.
Que cela soit l'une ou l'autre l'idée sera de rebase feature/4 sur la release/1.2.0 lorsque celle existera.
On remarque que la feature/2 ne provient pas du tag 1.0.0 mais du commit de merge de la feature/1. Je considère que les tests de features peuvent s'étaler tout au long d'un sprint et ne sont pas obligatoirement à faire à la toute fin de celui-ci.
Les branches de release ne sont pas forcé de provenir du commit taggé sur la master mais je trouve plus clean ainsi.
Par contre je considère comme une anomalie d'avoir deux release actives.
L'intérêt du sytème qui on doit se l'avouer est très proche de Gitlab Flow est de ne pas considéré les hotfix comme des commits d'exception.
Le deuxième intérêt est de merger qu'une seul fois une branche et de pouvoir la détruire ensuite. Ce qui s'intègre très bien au processus de merge request de GitLab.
Enfin, les branches de release peuvent servir d'environnement de dev, la develop de staging et la master de production.
A la fois develop et master peuvent accueillir des processus de CD.
Avantages
- Peut-être automatisé mais ce n'est pas obligé
- Le code peut ne pas être automatisé en test, les vérification humaines sont présentes
- Permet une séparation en environnement
- Fix le problème de gestions d'hotfix en ne les considérant pas comme des cas particuliers
Désavantages
- Les merge request peuvent-être nombreuses
- Ne gère qu'une version en production à la fois
- Se base activement sur GitLab/Github et ses outils de merge/pull request
Conclusion
Je n'ai pas la prétention d'avoir révolutionné quoique ce soit.
Je vous présente un système que j'ai éprouvé et qui m'a semblé pertinent.
N'hésitez surtout pas à venir dans les commentaires.
Merci beaucoup de m'avoir lu et à la prochaine pour de nouvelles aventures. 😀
Ce travail est sous licence CC BY-NC-SA 4.0.