Les modèles de fondation des LLM et leur entraînement
Bonjour à toutes et à tous 🙂
Je ne sais pas si vous étiez sur les réseaux sociaux cette semaine, mais il y a une belle "shit-storm" sur la présentation de la toute nouvelle IA française qui doit aider nos chers enfants à se passer des professeurs qui deviennent de plus en plus rares.
Problème, les utilisateurs sont taquins. Ils ont commencé à lui poser des questions.
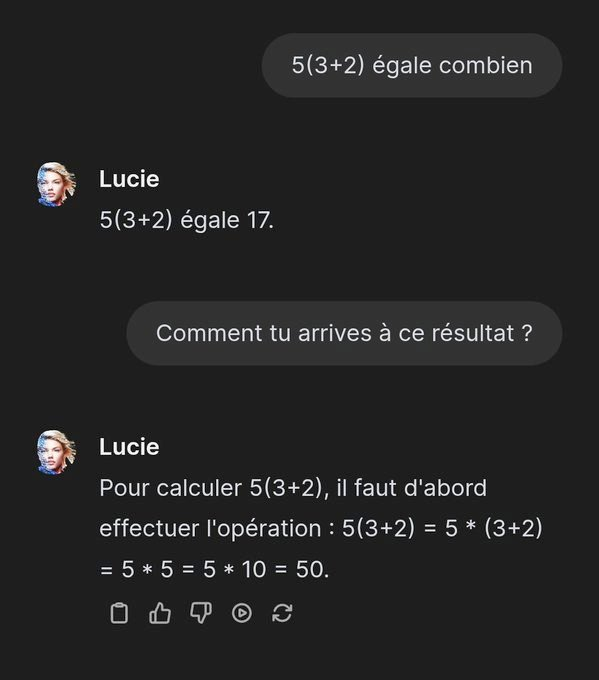
Et pour le moins que l'on puisse dire, ça ne casse pas trois pattes à un bigorneau ! 🤣
Et du coup, qu'est ce qui se passe ? On est nul en France et les US sont les plus beaux et les plus forts ?

Alors c'est un peu plus compliqué que ça. Et c'est cette complexité qui est le nœud du problème. Derrière le http://lucie.chat, il y a un iceberg de techniques et de connaissances maîtrisées qui montrent que non, en vrai, on n’est pas si nuls. 😇
Je vous propose aujourd'hui de manière très succincte et très vulgarisée de comprendre ce qu'est une IA de type LLM et pourquoi ce n'est pas si facile d'en fabriquer une. Je ne travaille pas dans les LLMs. Ceci est un article de vulgarisation, vulgarisée. Certains détails ont été omis pour conserver la fluidité du récit. Je ne vais parler que de la topologie transformer. N'hésitez pas dans les commentaires à rajouter toutes les précisions que vous désirez.Note à l'usage des spécialistes du domaine
Commençons par la base.
C'est quoi un LLM ?
LLM de son acronyme veut dire Large Language Model. Il s'agit d'une boîte qui prend du texte en entrée et qui répond par du texte en sortie.

Pour lui permettre de comprendre notre question, le LLM va s'appuyer sur un composant appelé un Transformer.

Nan pas celui des films. 😅
Celui des LLM ne se transforme pas en robot giga cool, mais par contre il est capable d'analyser du texte.
Il transforme quelque chose en autre chose. Et comme un seul ne suffit pas à saisir toute la richesse de notre belle langue de primates. On en met plein.

Le transformer lui-même a besoin d'aide pour fonctionner, plus particulièrement, il a besoin de réglages. Imaginez un four avec plein de curseurs dans tous les sens.
Chacun de ces curseurs est appelé un poids.
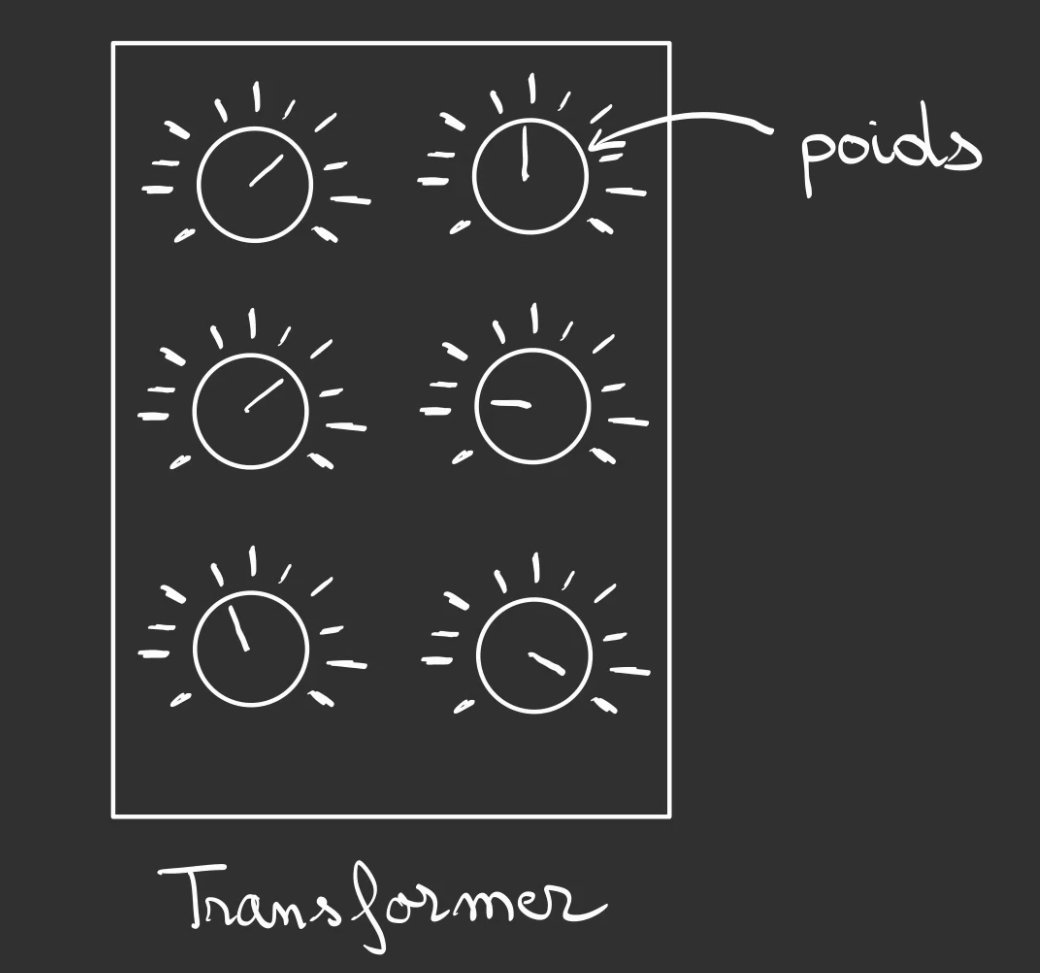
Vous obtenez alors ce que l'on peut nommer la topologie du modèle. Sa forme.
Le problème c'est le fond. Les curseurs sont mal réglés, un peu comme votre nouveau four, vous ne le connaissez pas encore et il chauffe trop.
Et bien ici, c'est pareil, le modèle n’est pas calé.
Il ne comprend rien à ce que vous dites et sa réponse risque fortement de ressembler à un dialecte qui n'a pas été encore inventé. 🤣
m?(G[yiYkFrfE@QD#(pc($oXU:xQtQ&i$sUP*HQyQn.[(a_IJlIIY)zuzAk%/OGRu$CaIxy}%K.ekCB'k'pN:vDc/slm"k.vt!-T
Avant que le LLM ne puisse dire avec assurance que le cheval d'Henri IV est bien blanc, il y a un très long chemin à parcourir.
L'étape fondamentale va être de lui apprendre à converser avec nous, il nous a peut-être dit la bonne réponse mais moi, en tout cas, je ne comprends rien à ce charabia.
On va donc devoir lui apprendre le français! Oui comme au CP.
Sauf que le modèle n'apprend pas de la même manière que nous.
Pour comprendre, il faut avoir en tête qu'un LLM est un modèle de prédiction statistique.
Si je vous dis
Le chat a mangé la ...
Il y a de forte chance que vous ayez instinctivement complété par le mot "souris".
Et bien, tout le but d'un LLM est de produire des prédictions sur le mot qui doit suivre en prenant en compte le contexte actuel.
Sauf que un LLM ne découpe pas par mots, car ce n'est pas adapté à toutes les langues. A la place il découpe en ce que l'on nomme des tokens.

Vous pouvez vous amuser à visualiser les découpages grâce à l'outil de Guillaume Laforge.
Le but de l'entraînement va être de lui faire recomposer la phrase en enlevant des tokens à chaque fois.
Le chat a mangé la souris <= phrase originelle
Le chat a mangé la souri <= -1 tokens
Le chat a mangé la so <= -2 tokens
Le chat a mangé la
Le chat a mangé
Le chat a man
Le chat a
Le chat
Le chat
Le
Et donc, comment apprend-il ?
Et bien chaque token possède une valeur et cette valeur peut être comparée à une autre. On est capable de déterminer qu'un token est "proche" d'un autre ou pas.
Par exemple, en faisant semblant qu'un token est un mot, si on a le token "blanc" et le token "noir", le "gris clair" sera plus proche du "blanc" que du noir et inversement pour le "gris foncé".
La valeur de token est un vecteur. Et la notion de "proche" / "éloigné" se nomme une distance.
Donc si on prend la phrase incomplète
Le chat a mangé la souri
Si le modèle nous prédis un "s", on le récompense de 5 points pour Gryffondor !

Par contre s'il nous prédit autre chose, on va lui dire à quelle "distance" il est de la réponse, et par un jeu du "chaud / froid" on va l'amener à trouver la réponse.
Cette distance par rapport à la bonne réponse, va permettre au modèle d'ajuster les poids de ses transformers. Vous savez les composants qui servent à analyser du texte. Et bien là ils sont en train d'apprendre que "souris" prend un "s" à la fin.
Une fois la bonne réponse trouvée, on continue à corser la difficulté. Maintenant ce n'est plus un token qu'il doit trouver, mais deux.
Le chat a mangé la so
Même combat, s'il trouve le "uris", il gagne le droit de passer au niveau suivant, sinon c'est reparti pour un tour.
Jusqu'à ce que le modèle doive prédire la phrase complète.
S'il y arrive, bravo et félicitations, vous avez construit un système qui peut écrire à un utilisateur que le "Le chat a mangé la souris".
Intéressant, mais pas très passionnant et un peu limité comme discussion. Comme toute personne de la bonne société, il se doit d'avoir de la conversation.
Et bien rien empêche de lui faire apprendre d'autres phrases.
Le vent souffle fort ce soir.
Un oiseau chante dans l’arbre.
La lune éclaire le chemin.
Il court vite sous la pluie.
Un chat blanc dort paisiblement.
Le café est encore trop chaud.
Elle lit un livre passionnant.
Le train arrive à l’heure.
Une étoile brille dans le ciel.
Il ouvre la porte lentement.
Et on peut continuer comme ça à lui donner du vocabulaire et des construction de phrases, de la grammaire.
La brise matinale caresse doucement les feuilles des arbres.
Un vieux chat tigré observe attentivement les passants depuis le balcon.
Sous un ciel étoilé, les vagues viennent s’échouer lentement sur le rivage.
Il ajuste son écharpe avant de s’aventurer dans le froid glacial de l’hiver.
Un parfum de pain chaud s’échappe de la boulangerie au coin de la rue.
Elle referme son livre avec un sourire satisfait, savourant la dernière phrase.
Les éclairs illuminent le ciel tandis que la pluie tambourine sur les toits.
Le train démarre en douceur, laissant derrière lui une gare presque vide.
Un petit oiseau curieux picore les miettes tombées sur la table en bois.
Perdu dans ses pensées, il ne remarque pas le chat qui s’approche furtivement.
Petit à petit, il va se familiariser avec notre langue. Plus son corpus de connaissance sera massif, plus ses capacité de créativité de réponses seront élevée.
Le gros du travail lorsque l'on conçoit un LLM est alors de créer ce corpus de connaissance et le rendre digeste pour le modèle. Par exemple si les documents possèdent des numéros de pages, il faut les nettoyer car il pourrait être pris par le modèle comme des tokens à prédire. On se retrouverait alors avec des numéro de pages aléatoires dans les réponses.
Mais notre langue ce n'est pas que des phrases, c'est surtout des enchaînements de phrases qui forment des paragraphes.
La brise du soir agite doucement les branches, tandis qu’un chat observe la rue silencieuse. Une lumière dorée filtre à travers les fenêtres, révélant des silhouettes paisibles. Au loin, une horloge sonne, rompant brièvement le calme nocturne.
Ces paragraphes doivent avoir une logique et c'est cette logique qu'il faut réussir à faire comprendre à notre modèle.
Je vous avoue que cette phase, je ne l'ai pas suffisamment explorée, mais je suppose que l'on a également un système de récompense lorsque l'enchaînement des phrases est logiques.
Et on peut alors enchaîné les paragraphes pour former du texte.
La brise légère fait danser les feuilles sur le trottoir désert. Un chat, tapi dans l’ombre, scrute les passants tardifs d’un regard curieux. Au loin, une enseigne clignote doucement, dernier vestige d’une journée bien remplie.
Dans une ruelle étroite, une vieille lanterne diffuse une lumière tremblotante. Le silence est seulement troublé par le murmure d’une fontaine et le pas discret d’un promeneur solitaire. La nuit enveloppe la ville, tissant son voile de sérénité.
Cette étape se nomme le pré-train. Vous obtenez alors ce que l'on peut appeler un modèle de Fondation, il parle enfin un dialecte compréhensible.
Maintenant, est-ce que ce qu'il va vous raconter aura un sens par rapport à votre question, il y a vraiment peu de chance. le système a fonctionné en vase quasi clos.
Il est temps de l'ouvrir au monde.
Et là il y a plusieurs écoles. Soit on laisse des robots (d'autres LLM) vérifier le travail du modèle et le corriger s'il ne comprend pas ce qui est dit, c'est assez aléatoire le plus souvent et donne des qualités plus que discutables sur les réponses.
Soit l'Humain intervient. Un opérateur va créer une série de questions qu'il va poser à notre LLM maintenant capable de parler presque normalement.
On a également là deux manière de réagir, soit on lui dit, "oui tu as raison", "non tu as tort". Soit on lui demande de générer un paquet de réponses et l'opérateur choisit celle qui lui semble la plus intéressante, il peut également lui annoter sa réponse en corrigeant les mots ou phrases incorrectes.
Cette étape se nomme le Reinforcement Learning from Human Feedback ou RLHF, l'apprentissage par renforcement à partir de commentaires humains.
En multipliant les jeux de questions/réponses, le modèle va affiner sa compréhension de ce qui lui arrive en entrée et ainsi devenir de plus en précis dans ses réponses.
Félicitations, après des mois de RLHF, vous avez un ChatGPT !
Bon alors et Lucie dans ce cas, pourquoi elle est aussi nulle en maths ?
Et bien parce que Lucie n'est tout simplement pas finie. C'est un modèle de fondation qui a été entraîné à écrire en français, qui comprends grosso-modo ce qu'on lui dit mais qui n'a subit presqu'aucun RLHF. En gros elle parle français et point-barre.
Du coup qu'est-ce qu'ont fait les créateurs de Lucie dans cette histoire?
Ils ont fait plein de choses!
Ils se sont basés sur l'architecture transformer que je vous ai présenté plus haut et sont venus créer les outils nécessaires pour analyser toute sorte de source de données en français et dans d'autres langues pour venir créer un corpus massif et publique de données d'entraînement qui leur ont permis de créer un modèle de fondation totalement open source.
Il existe des modèles open source comme Mistral, mais seuls les poids sont libres d'accès, les données d'entraînement ne le sont généralement pas. Or ne posséder que les poids d'un modèle ne permet pas pouvoir créer quelque chose de nouveau avec. Si le créateur du modèle décide, ou son pays, décide de ne plus publier la mise à jour des poids de son modèle. Alors les personnes qui en dépendaient pour faire ses adaptations (on nomme ça le fine-tuning) se retrouve condamnés à utiliser de la technologie dépassée.
En bref, posséder son modèle de fondation permet d'être indépendant sur sa recherche et son développement de nouveaux modèles plus performants et à l'état de l'art de la Connaissance.
Le travail qui a été abattu par les équipes de Lucie est un travail sous-marin qui nous permet à nous, n'importe quel développeur(euse) de bénéficier de tous les outils nécessaire ainsi que le corpus de données pour créer du neuf.
Donc oui elle est nulle en maths. Mais franchement, c'est pas le plus important à retenir.
Quand le sage montre la lune du doigt.
Le sot regarde le doigt.
Bonne journée 😃
Ce travail est sous licence CC BY-NC-SA 4.0.