Stack et Heap
Lors du précédent article, nous avons exploré les lois qui régissaient le Drop des éléments dans le code. Je vous avais également relevé la relative supercherie de ce que l'on avait réalisé.
On drop bien des choses mais, dans les faits, rien ne se passait réellement.
Aujourd'hui, nous allons voir ce qui se déroule concrètement lors d'un drop.
Mais avant un peu de culture G sur la mémoire dans un ordinateur.
Mémoire physique et mémoire virtuelle
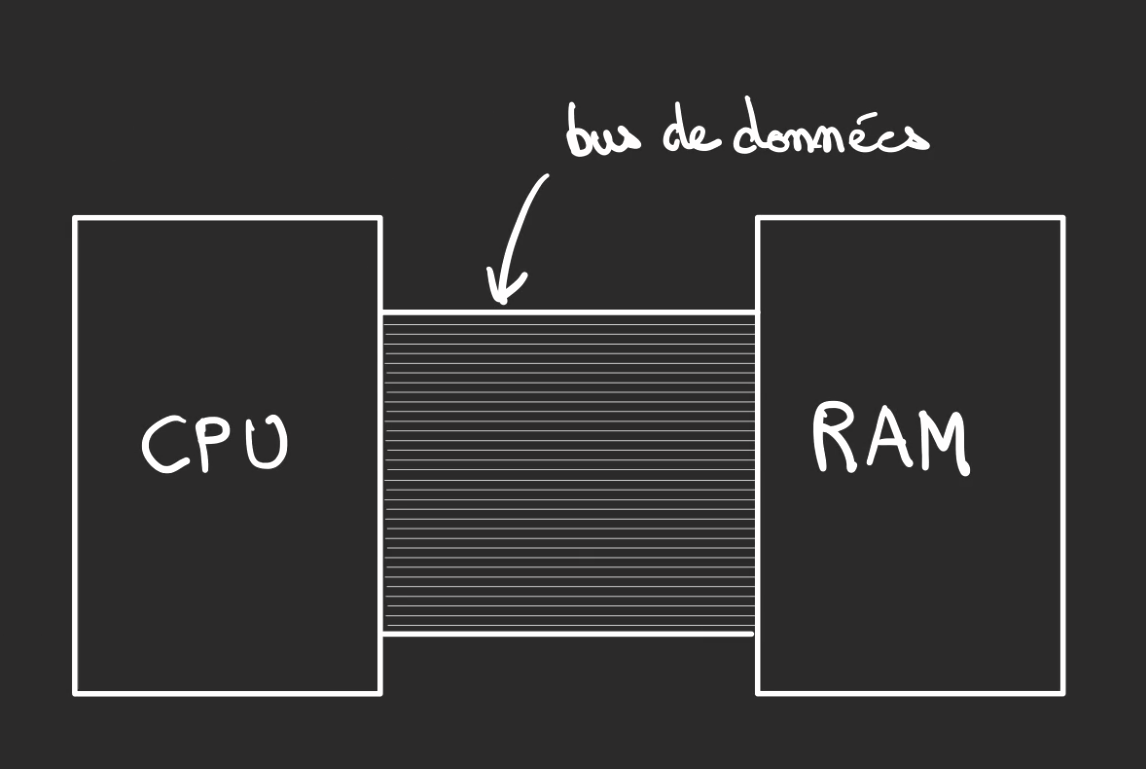
Un ordinateur marche dans son format actuel comme une usine avec un stock.
L'usine est le CPU, c'est lui qui effectue les tâches.
Le stockage est la mémoire et dans ce qui va nous intéresser par la suite la RAM ou mémoire vive.
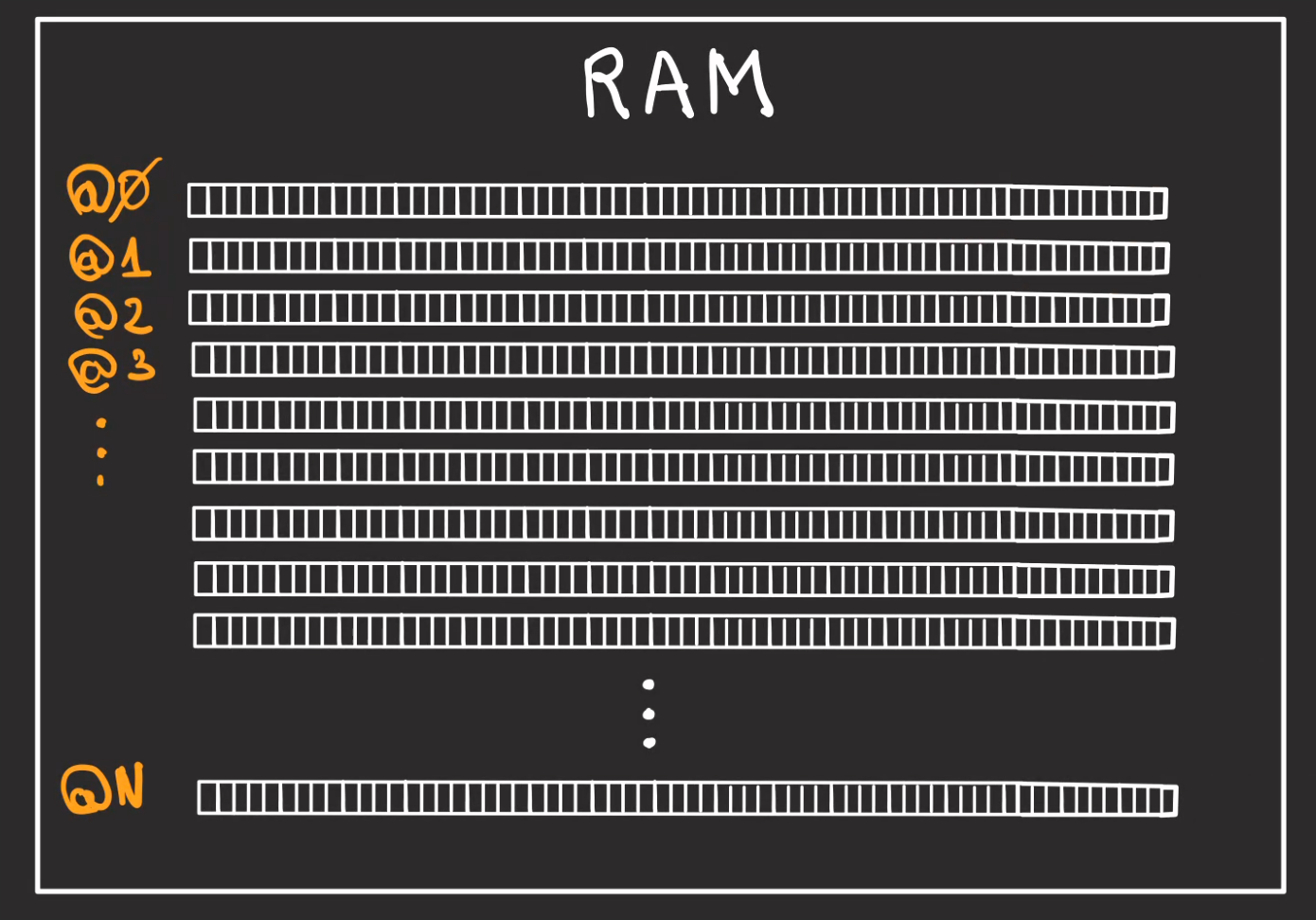
Si on rentre dans le détail de stockage, nous allons avoir des rayonnages, chaque rayonnage contient des emplacements.
Pour pouvoir identifier les rayonnages, on leur donne une adresse qui va de 0 à N.
Chaque emplacement est appelé un bit.
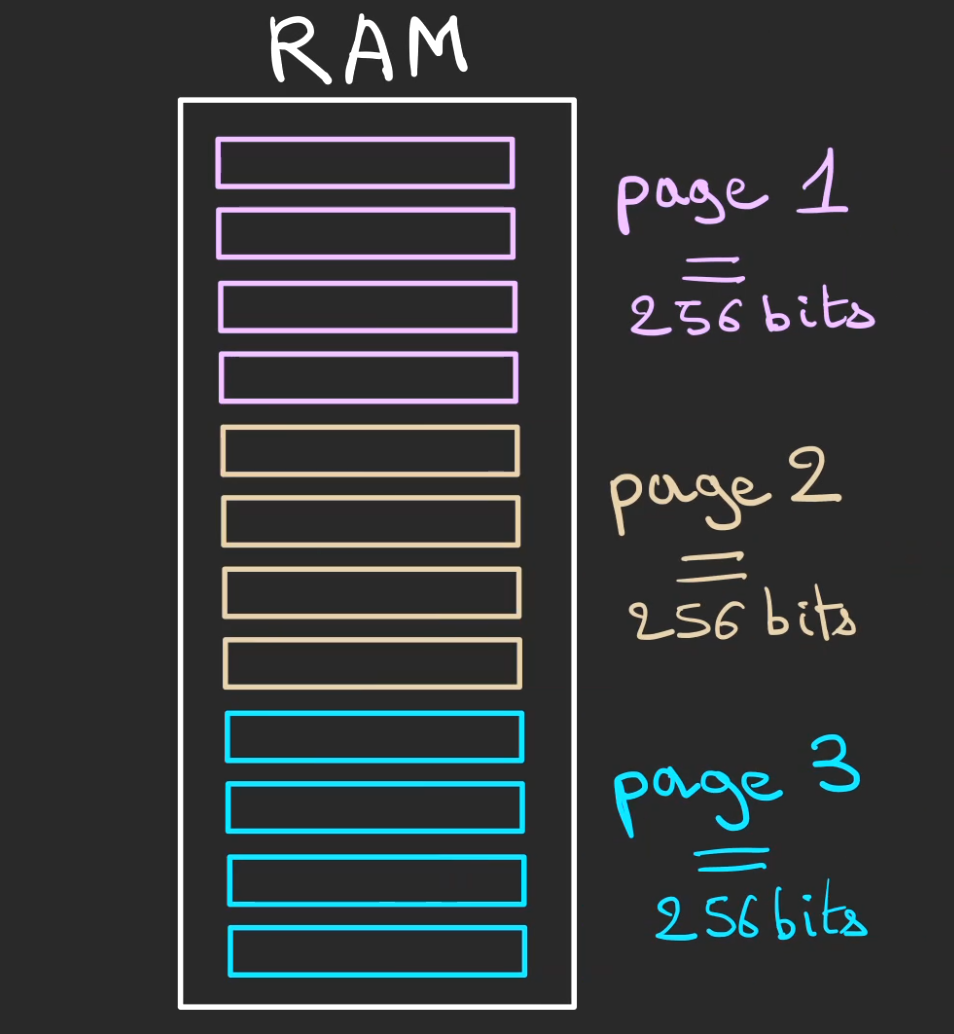
Pour plus facilement se repérer dans l'entrepôt, on regroupe les rayons en des parties que l'on nomme des pages.
Si chaque rayon possède 64 emplacements, 64 bits. Et qu'une page fait 256 bits, alors une page fera 4 rayons.
Si on essaie de continuer notre analogie avec l'usine, un ordinateur est constitué de chaînes de production distinctes qui ont un besoin d'isolation.
De fait, au lieu de laisser l'entrepôt en accès libre, on va subdiviser celui-ci en utilisant le groupement en pages.
Nous allons avoir N chaînes de productions qui vont avoir une zone de stockage dédiée.
Pour des raisons de facilité de communication, au lieu de dire à la chaîne de production 1 que ce qu'elle cherche est dans le rayon #12252525 emplacement #12. Nous allons simplement lui dire : rayon #10 emplacement #12.
De son point de vue, elle aura l'impression de pouvoir accéder à l'ensemble de l'entrepôt et d'être dans les premiers rayonnages alors que pas forcément.
Ses rayonnages peuvent même être dispersés dans l'entrepôt et donc le rayon #12 peut être au milieu de l'entrepôt et le rayon #13 à côté de la porte d'entrée.
Cette manière de faire à plusieurs avantages :
- Chaque chaîne de production possède un stockage isolé des autres chaînes de production, donc pas de possibilité de piquer la marchandise d'un autre
- L'entrepôt peut être virtuellement bien plus grand ou petit que dans la réalité, mais ça la chaîne de production ne le sait pas
- Comme tout est virtuel, l'entrepôt virtuel peut-être réagencé et même composé de plusieurs entrepôts physiques différents
Dans notre analogie, une chaîne de production est un programme, ce qu'il voit comme entrepôt est appelé la mémoire virtuelle, l'entrepôt physique est la mémoire physque, elle est généralement composée de barrettes de RAM, mais cela peut aussi être du disque dur ou autre support de stockage.
Chaque rayon est appelé une adresse mémoire.
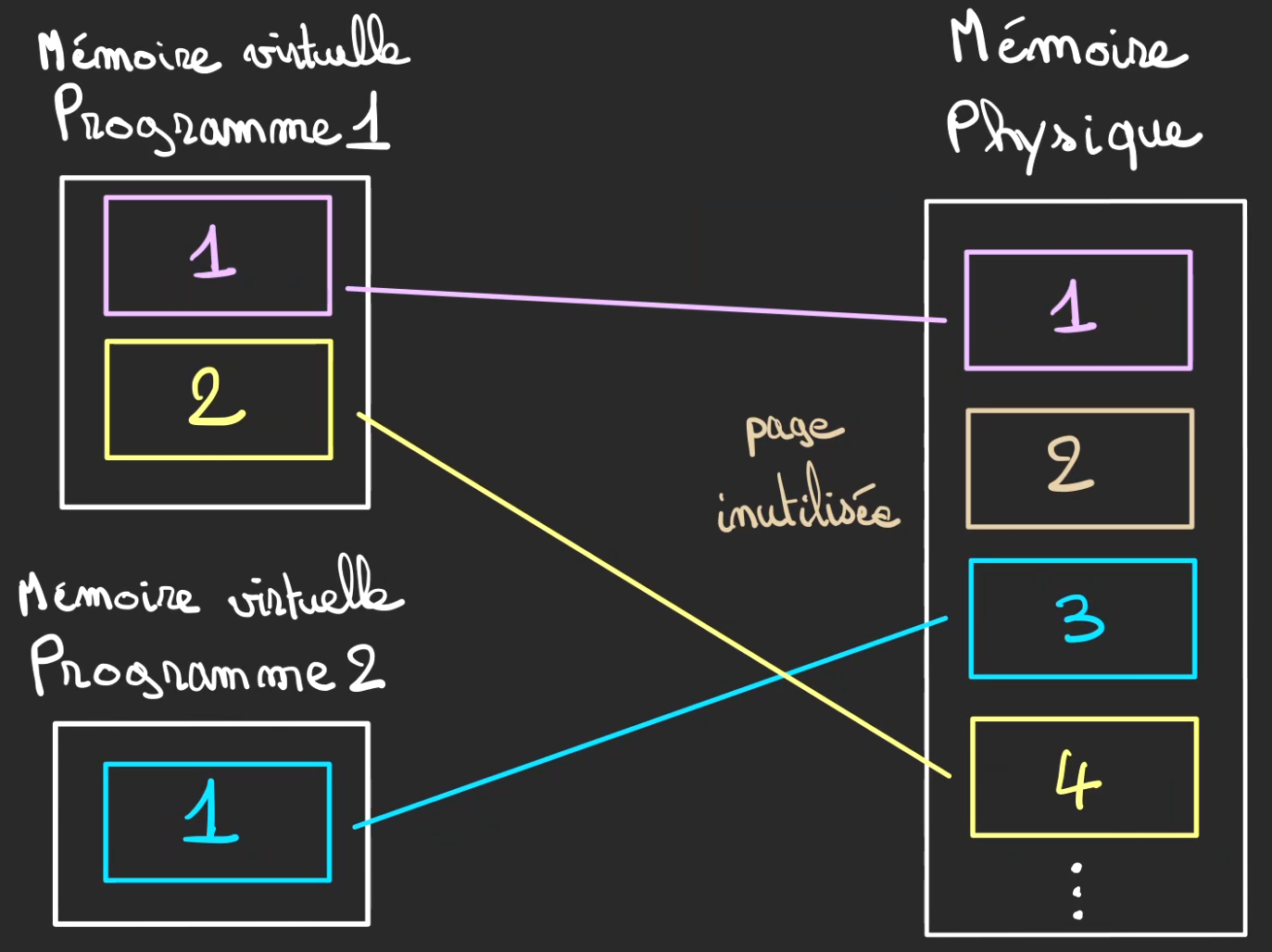
Les pages seront alors à la demande, attribuées aux différents programmes.
Des pages peuvent tout à fait, n'être attribuées à aucun programme.
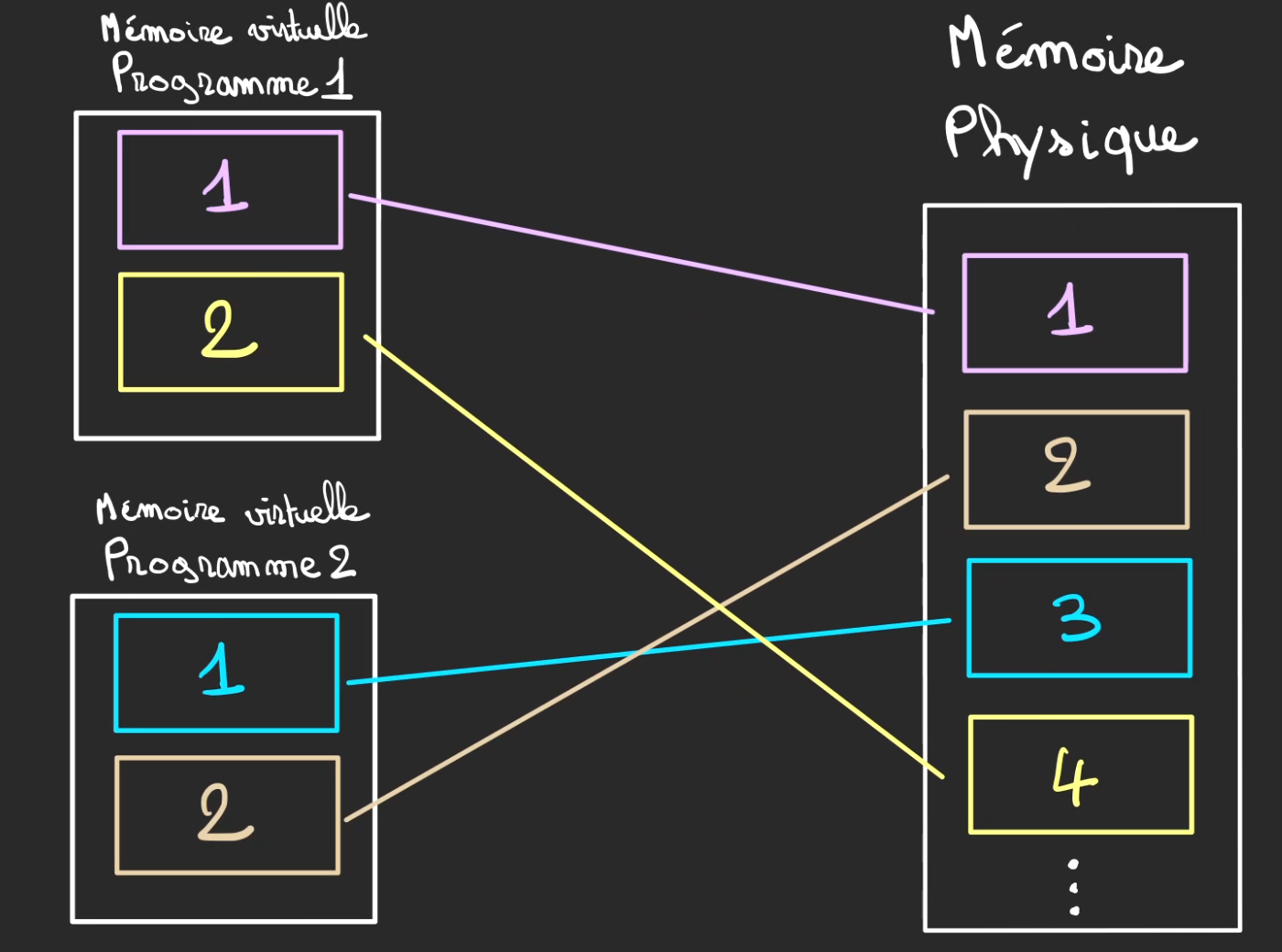
Ici le programme 1 possède les pages 1 et 4 qui sont vues respectivement de sa part comme étant les pages 1 et 2.
Le programme 2, ici n'a qu'une unique page 3 qui est vu de sa part comme la page 1.
La page 2 est inutilisée.
On peut faire la différence en les pages physiques et les pages virtuelles, les pages physiques sont appelées des frames et les pages virtuelles des pages.
Je ne ferai pas le distinguo ici, mais sachez que ça existe.
Si le programme 2 vient à venir en manque de place dans son entrepôt virtuel, il est tout à fait possible de lui allouer plus de place dans la mémoire physique.
La page 2 de la mémoire physique devient alors allouée au programme 2.
De son point de vue la mémoire a grandi.
Nous avons donc des programmes qui possèdent un certain nombre de pages.
Ces pages sont alors fusionnées pour former une zone une mémoire unifiée du point de vue de programme.

Segmentation de la mémoire virtuelle
Maintenant que chaque programme a sa propre zone mémoire où il peut y faire ce qu'il désire sans que cela gêne les autres programmes qui tournent à côté de lui, nous allons voir comment chaque programme organise sa mémoire de travail.
Si vous regardez des tutos sur le sujet, vous allez tomber sur ce genre de schémas.
Décortiquons un peu ce que l'on voit.
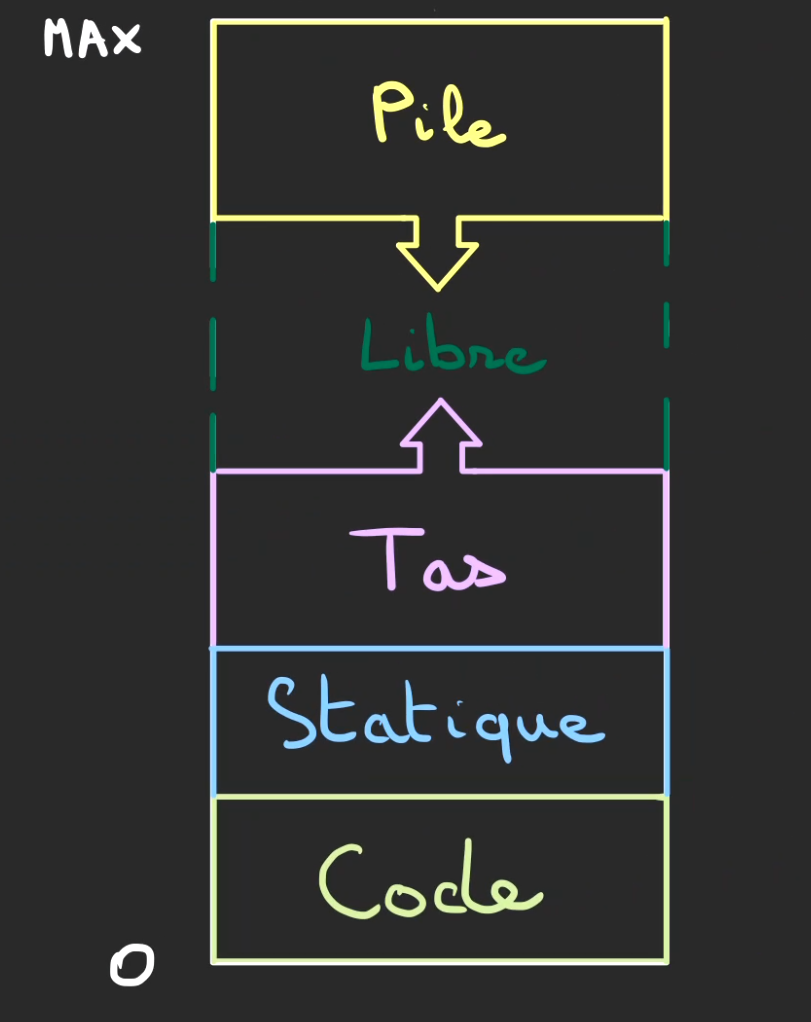
Tout d'abord, l'adresse la plus petite est la 0. Et le MAX diffère selon la plateforme, mais c'est un très très très grand nombre.
Ensuite en partant de bas en haut. On voit des sections, ces sections sont appelées des segments, et ces segments ont des petits noms :
- Code : Il s'agit du fameux code assembleur/machine, c'est comment le programme doit tourner
- Statique : Ce sont des informations qui sont stockées dès le début du programme et qui ne sont pas modifiables par la suite, on appelle ça de la mémoire read-only, on y retrouve les constantes, les variables statiques et un certain nombres d'autres choses.
- Tas : La mémoire dynamique, tout ce qui doit évoluer au cours du programme et qui ne sera pas dans la Pile sera stocké dans le Tas
- Libre : Une zone pas encore allouée, celle-ci peut correspondre à des pages virtuelles ou non.
- Pile : La mémoire de travail du programme, on va voir son fonctionnement en détail
Le Tas possède une flèche vers le haut ce qui signifie que l'on monte dans les adresses quand on parcourt ce segment de mémoire.
Contrairement à la Pile qui est parcourue de haut en bas.
Ce n'est pas vrai pour toutes les architectures mais généralement, c'est ainsi fait pour des raisons de sécurité. En effet, depuis le tas, la première adresse est supérieure à 0 et comme on croît dans les adresses, il est impossible de pouvoir modifier durant l'exécution du programme, le segment Code qui est plus bas.
Pareillement, même si la Pile descend en adresse, elle ne peut pas descendre dans le segment du Tas, vous aurez le fameux StackOverflow bien avant. 😀
De fait, cette manière de procéder assure deux choses :
- On ne peut pas modifier par inadvertance ou sciemment un programme qui tourne.
- On s'aménage un espace libre qui peut être utilisé au besoin
Il existe d'autres segments mémoires mais, je n'en parlerai pas ici.
Ils servent à diverses tâches, comme discuter avec l'extérieur, le système d'exploitation et d'autres choses.
Stack : Empile et dépile
Bien voyons comment marche le segment mémoire Pile.
On appelle ça une pile, car comme pour une pile d'assiettes, pour atteindre celle du dessous, il faut enlever celle du dessus avant.
Cette Pile est elle-même décomposée en frames. Je n'ai pas trouvé de désignation française du terme.
Les frames seront nos assiettes dans la pile d'assiettes.
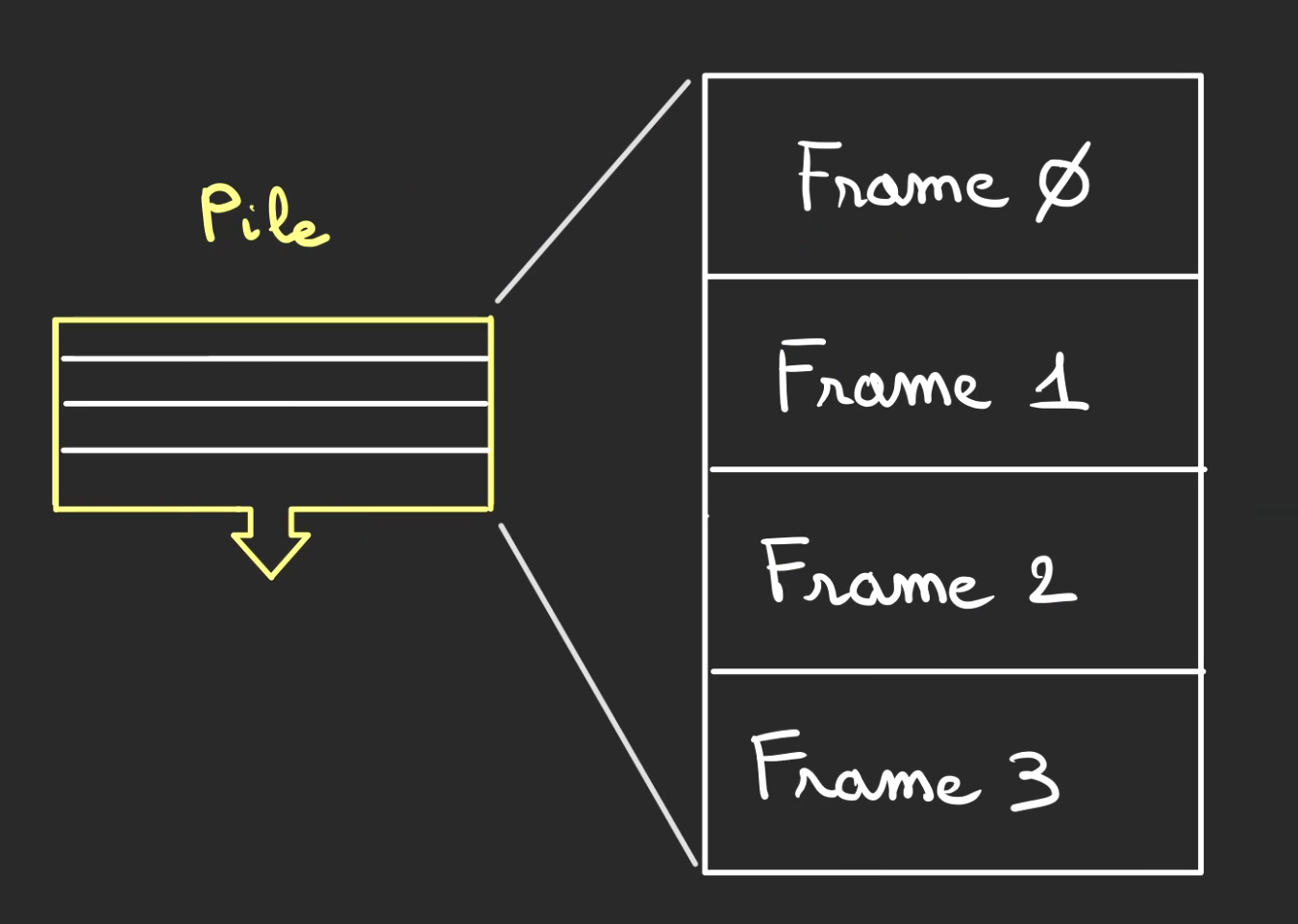
Frames
Prenons le bout de code suivant.
Le curseur rouge correspond au moment d'exécution du programme.
Ici, nous sommes avant tout, même l'appel de la méthode main.

Le curseur se déplace d'un cran vers le bas.
On va push une frame 0 sur la pile.

On rentre dans la méthode main. On réalise ce que l'on appelle un switch de contexte.
On va alors marquer la position du curseur avant l'entré dans le main, ça nous permettra de revenir à cette position plus tard.
Sur le dessin, ceci est symbolisé par un curseur vert numéroté d'un 0.
Nous sommes désormais dans la méthode main.
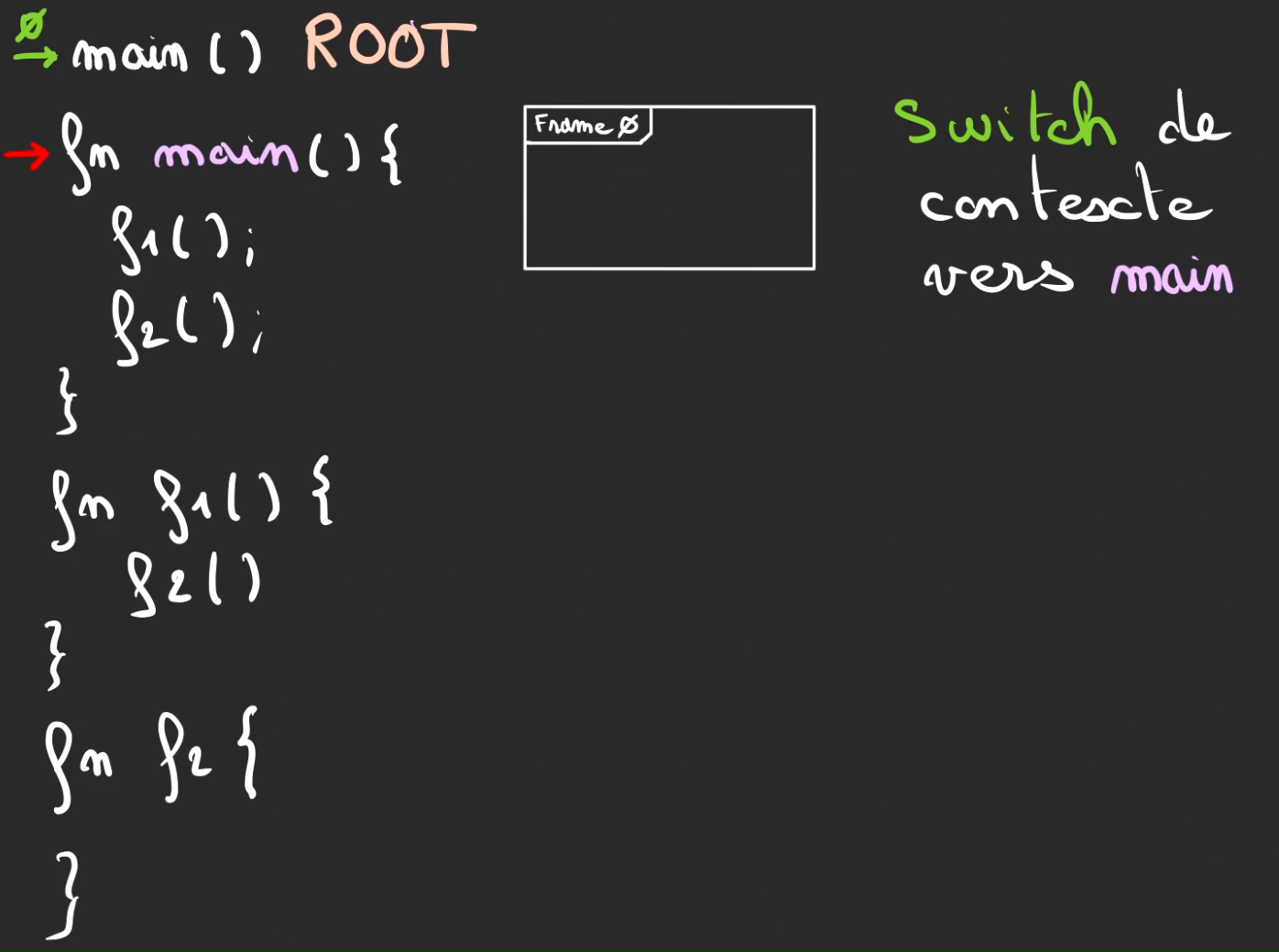
On continue l'exécution, nouvelle fonction f1, on push une nouvelle frame 1.
Nouveau switch de contexte cette fois-ci vers f1. On mémorise la position du curseur par le curseur vert numéroté d'un 1.

Même principe.
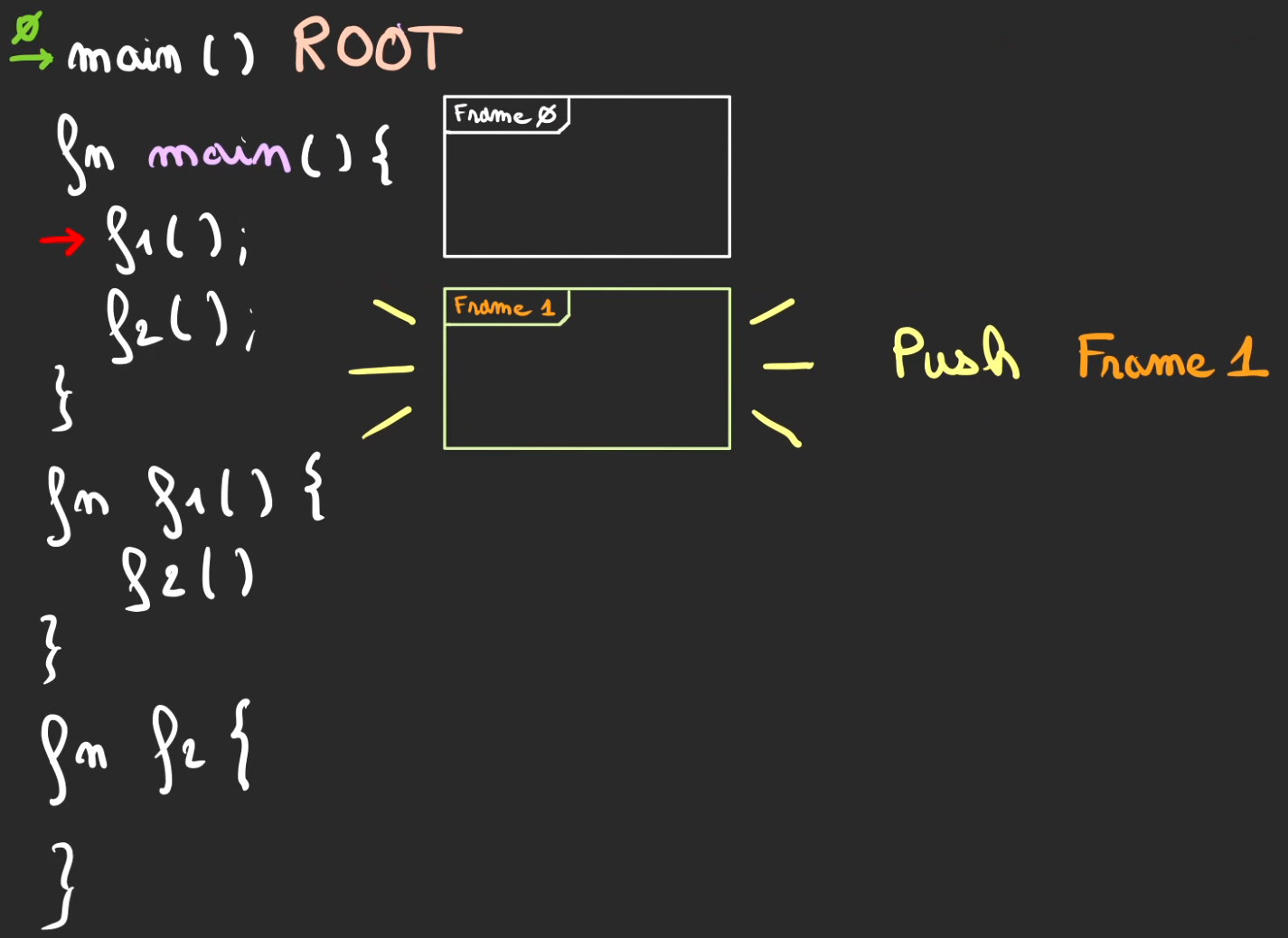
On continue l'exécution, nouvelle fonction f2, on push une nouvelle frame 2.
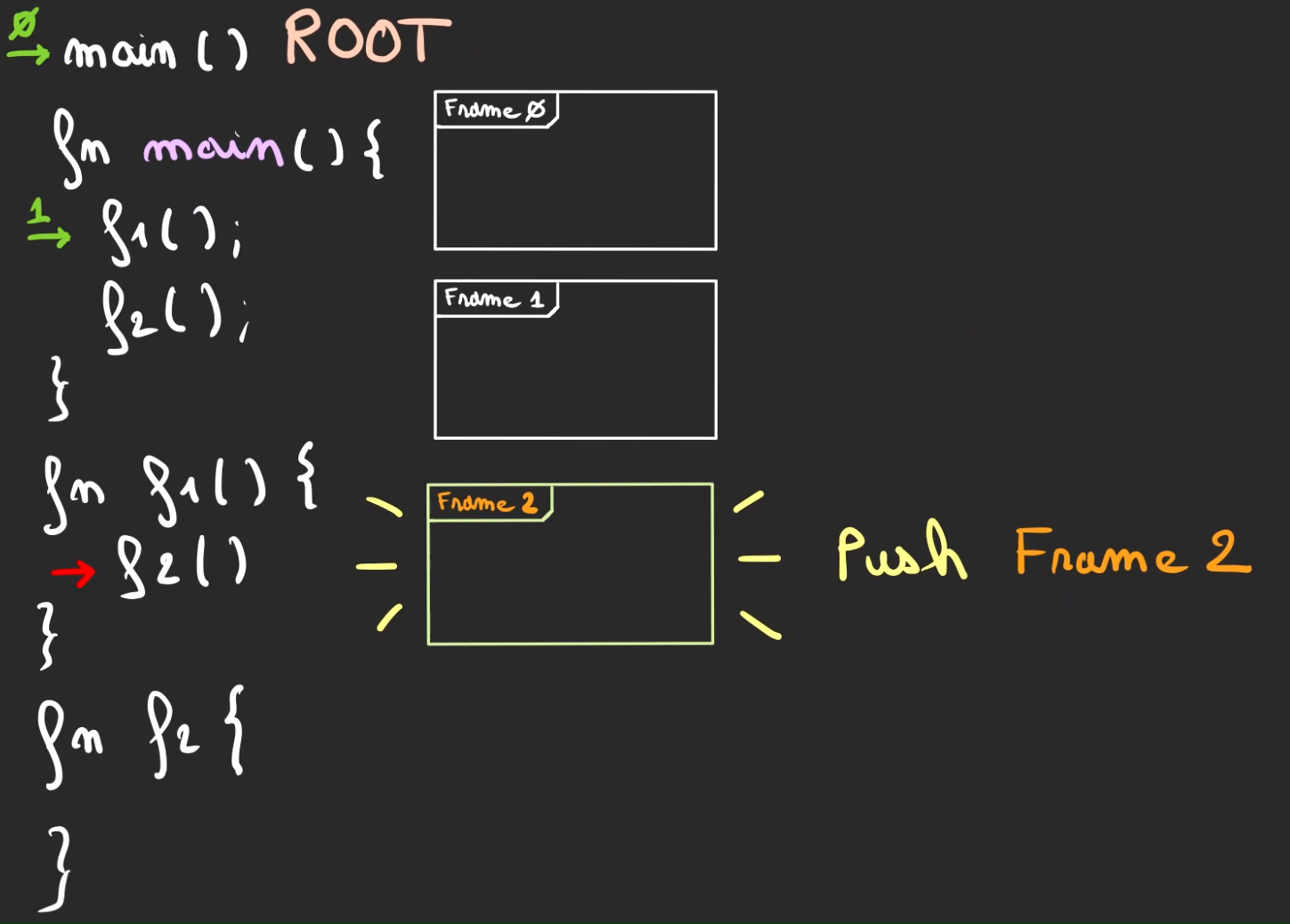
Nouveau switch de contexte cette fois-ci vers f2. On mémorise la position du curseur par le curseur vert numéroté d'un 2.
La fonction f2 fini, on effectue un retour de contexte.
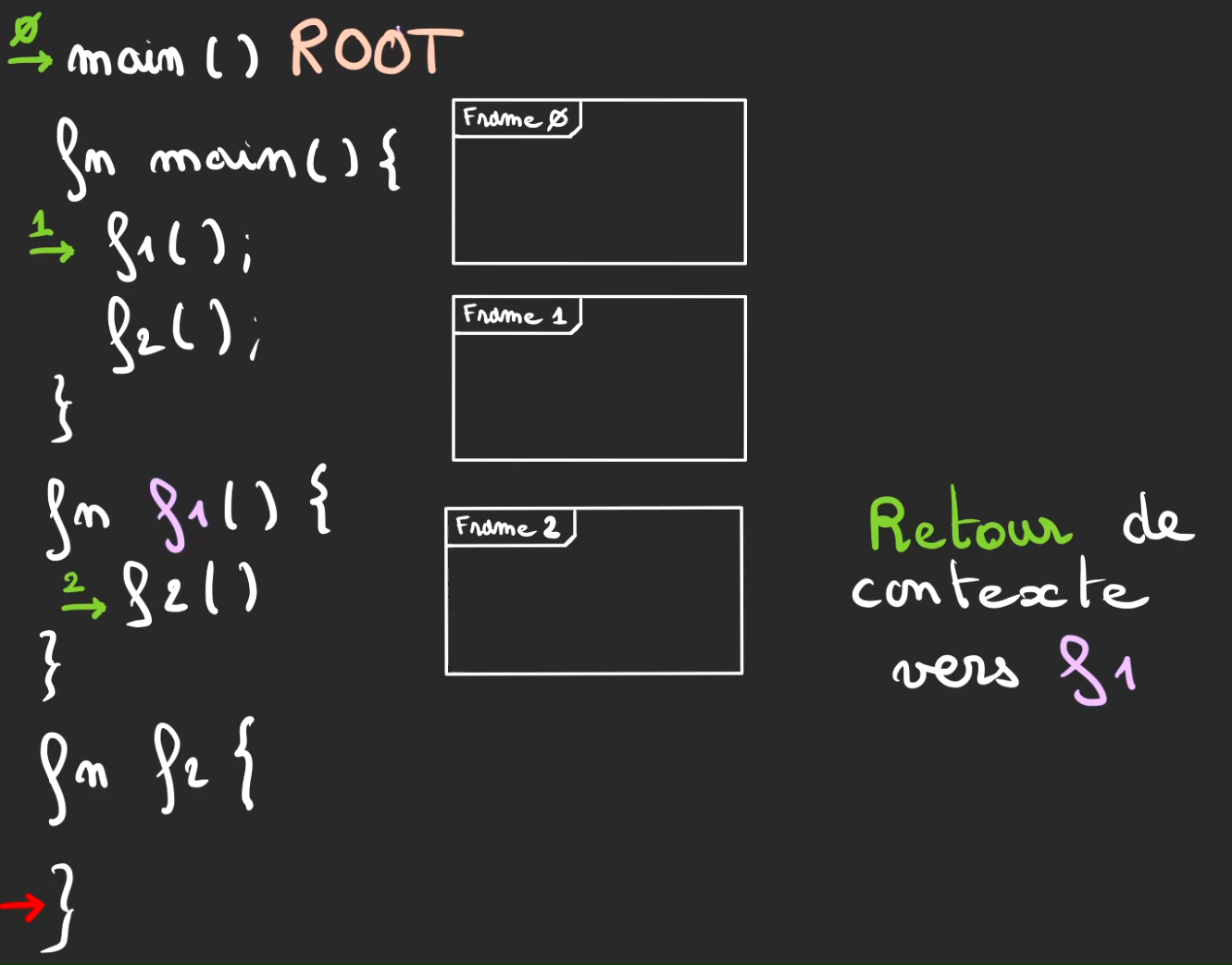
Et comme on a bien pris garde à baliser notre chemin qui a semé ses miettes de pain dans la forêt.
Il est facile de remonter à la position du curseur avant l'exécution de f2.
On remet alors le curseur rouge à son ancienne position. Et on dépile la frame 2, on nomme ça un pop.
À partir de ce moment, la frame et tout ce qu'elle contenait n'existe plus.
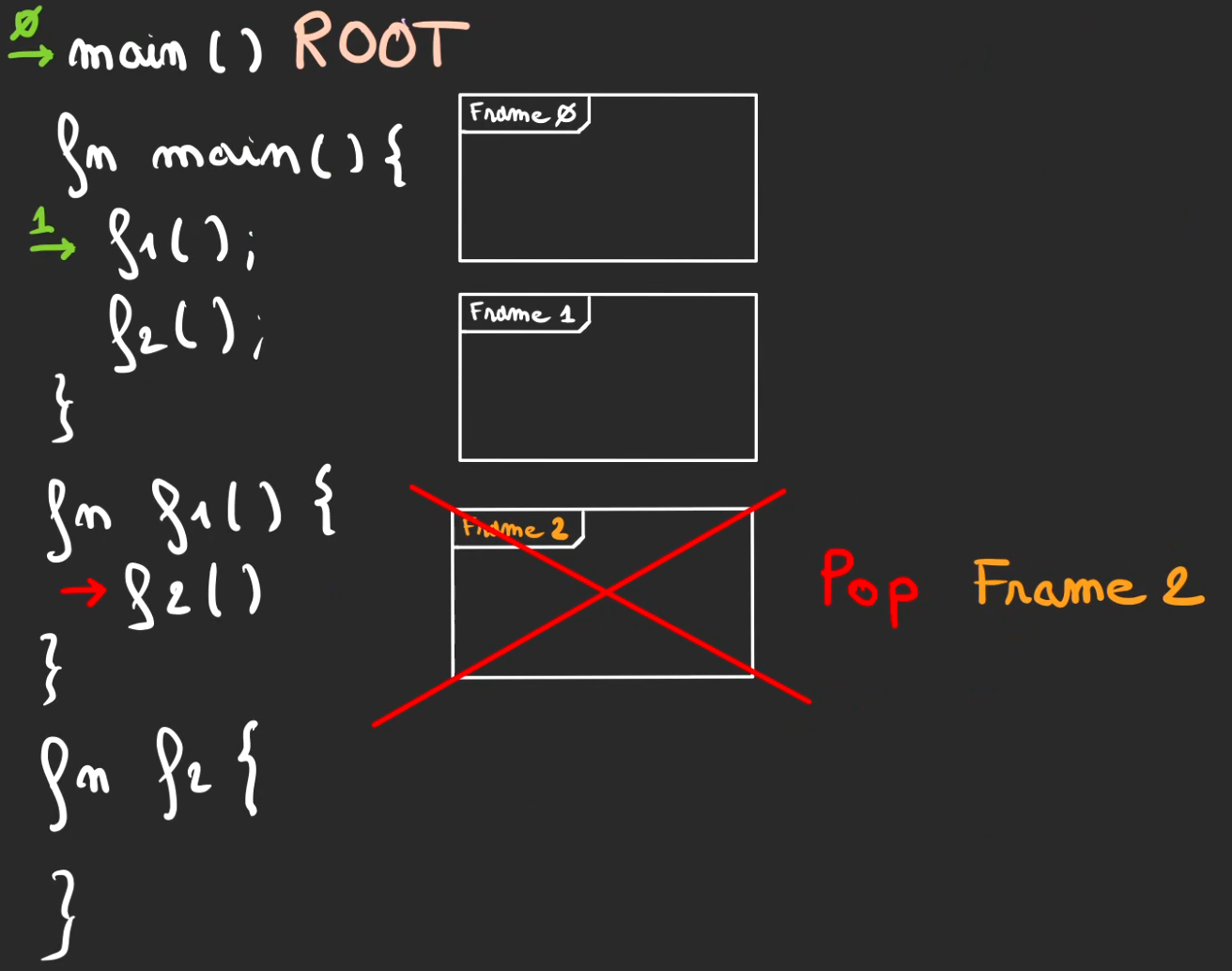
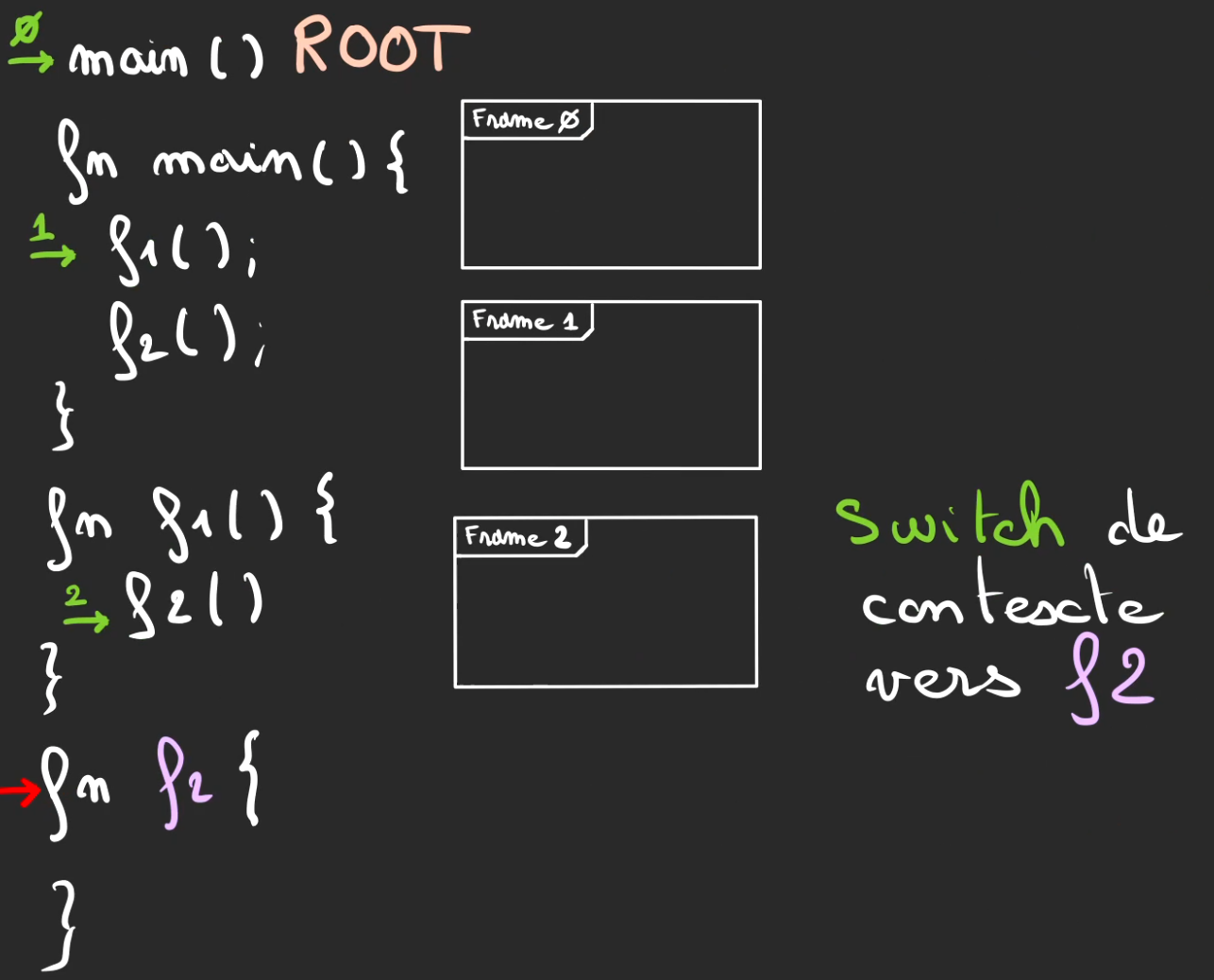
f1 fini son tour, retour de contexte vers main.

Puis pop de la frame 1.
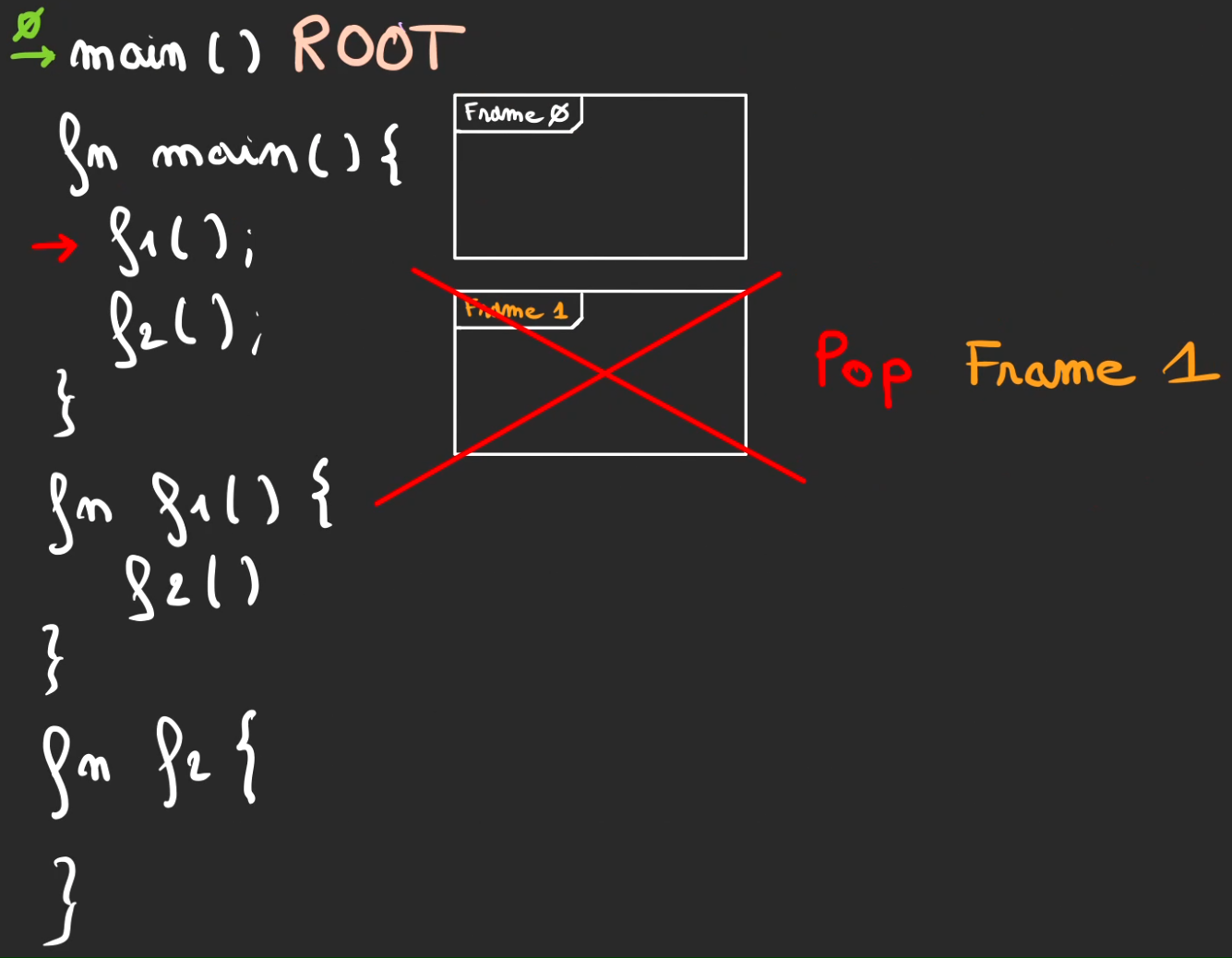
L'exécution continue, appel de la méthode f2, donc push de la frame 1.
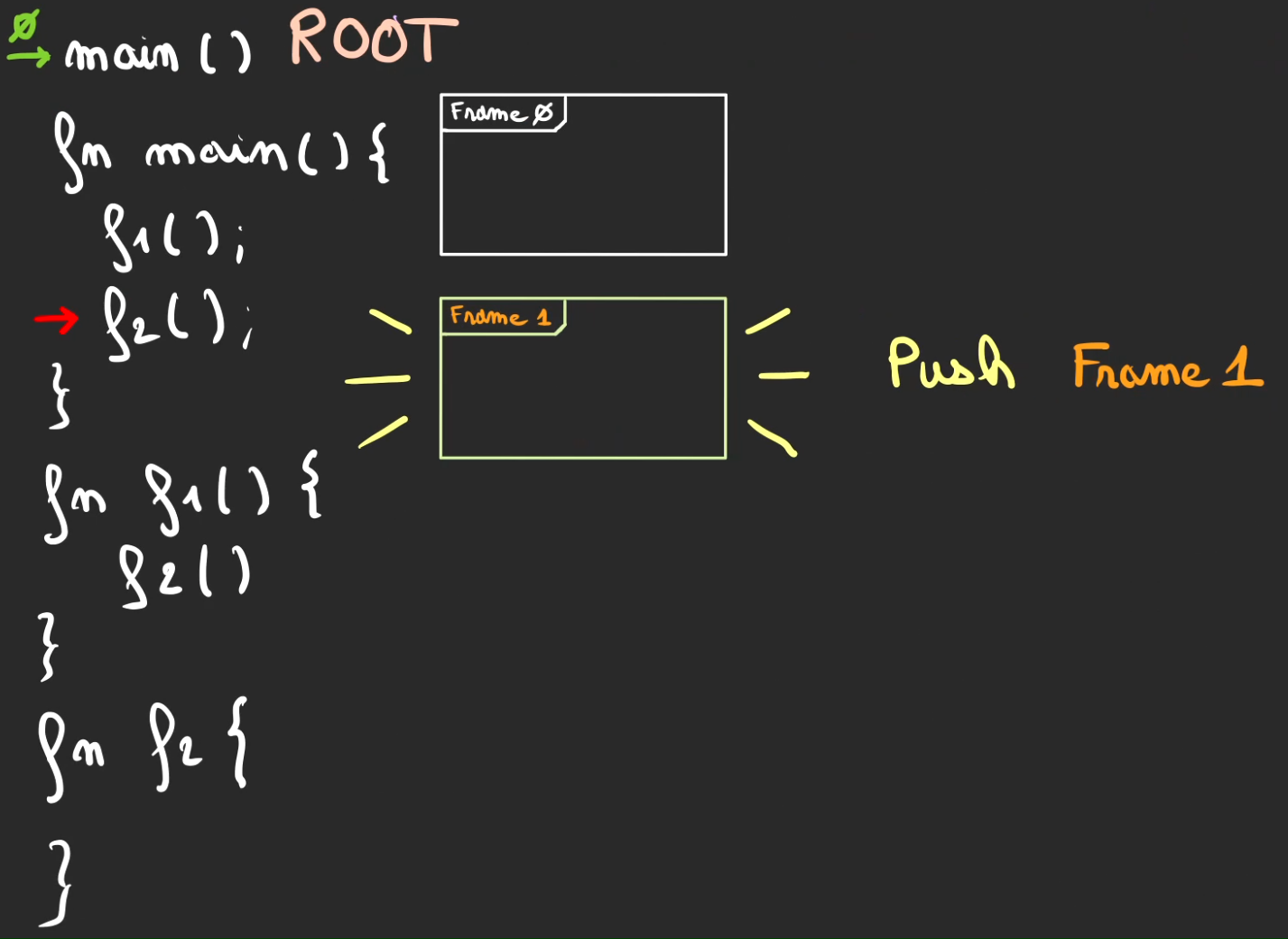
Switch de contexte vers f2.

Retour de contexte vers main à l'issue de l'exécution de f2

Pop de la frame 1.
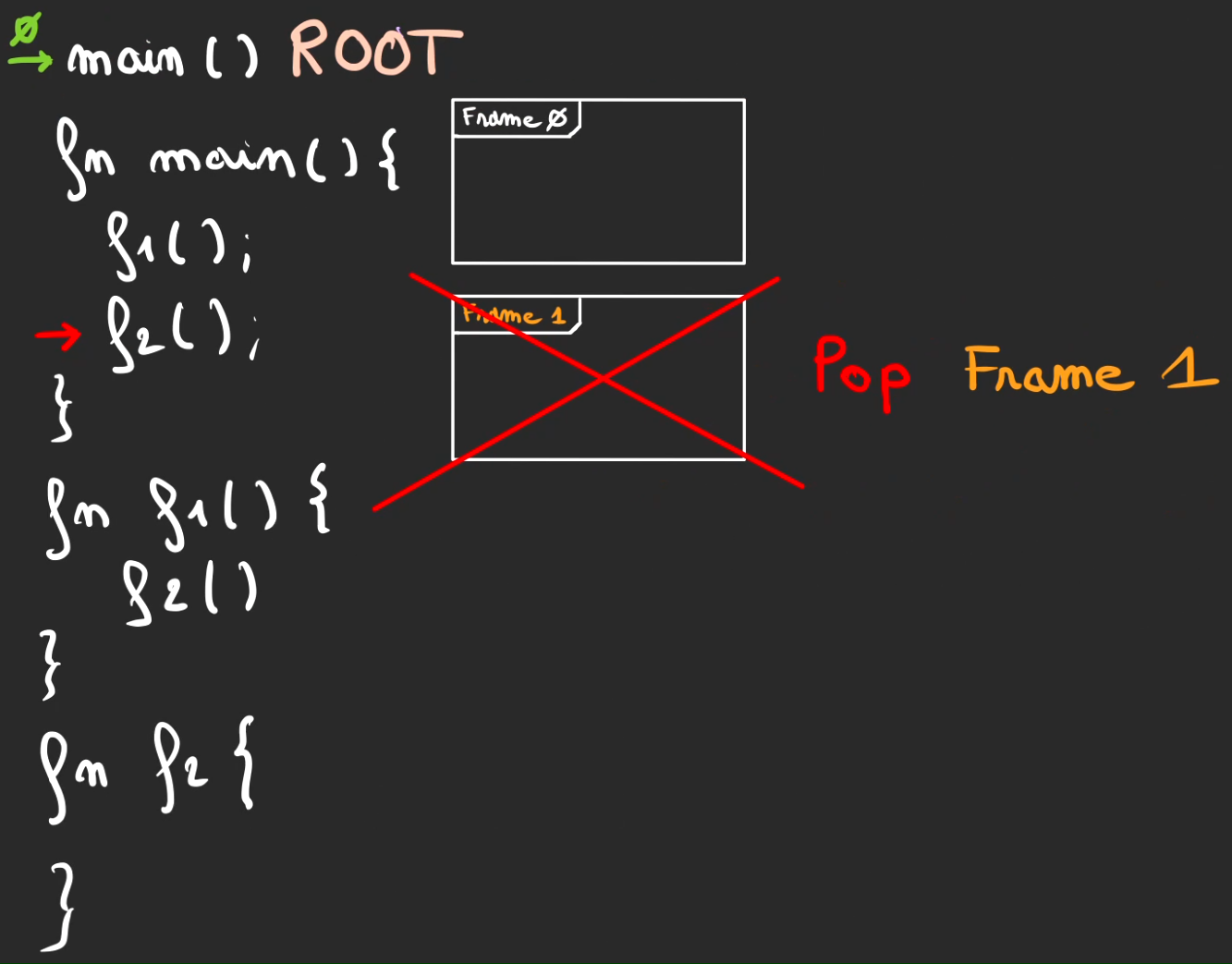
Fin d'exécution du main. Retour de contexte vers ROOT.

Pop de frame 0.
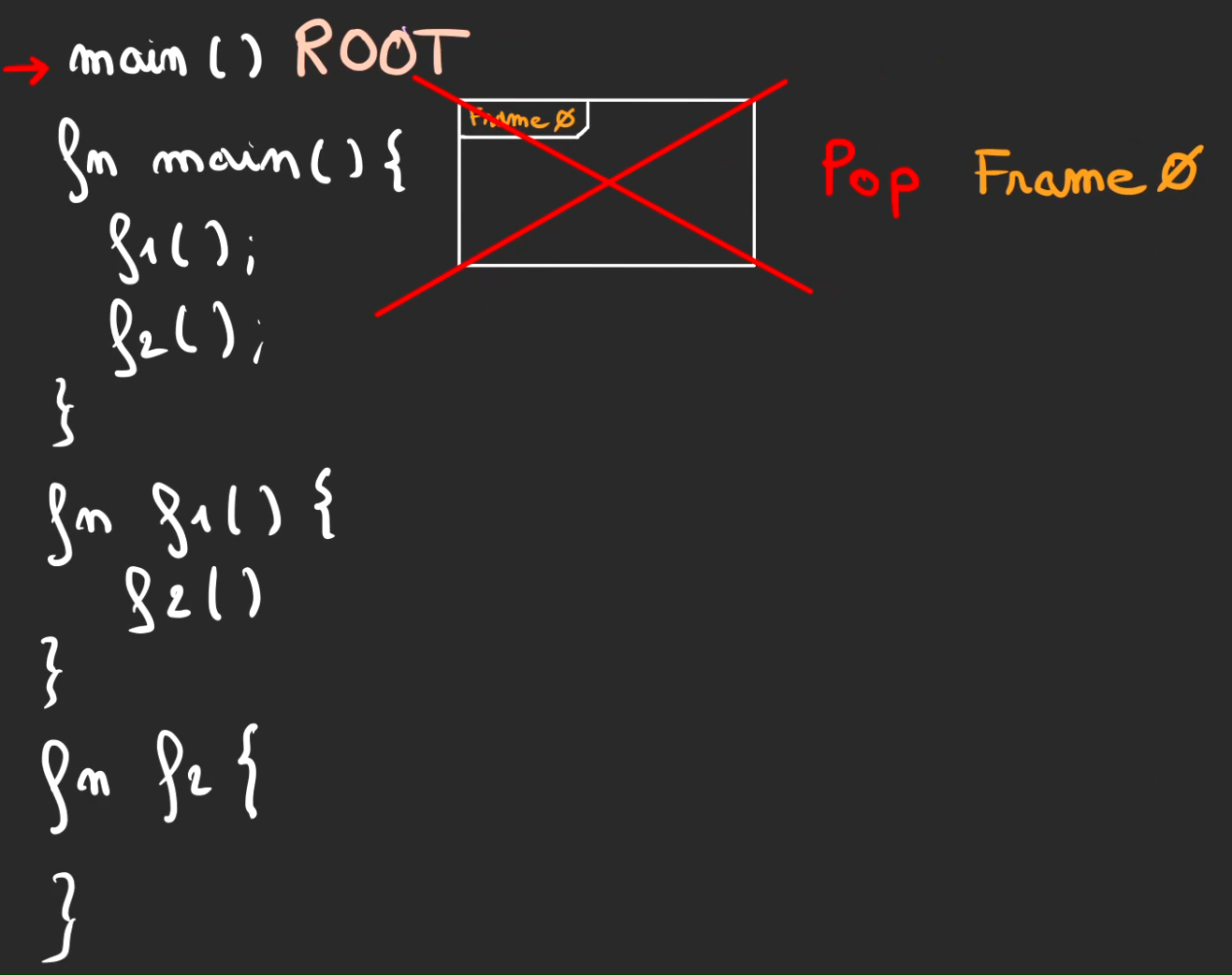
Et fin d'exécution du programme.

Durant ce petit ballet, nous avons empilé des frames et dépilé des frames mais nous n'avons rien mis dedans, il est temps de remédier à cela.
Affectation et libération
On est reparti !
Au début du programme, pas de frame.

On rentre dans le main, on push la frame 0.

On effectue le switch de contexte vers main

Le curseur d'exécution atteint l'affection de a = 1.
On vient alors stocker dans la frame 0, la valeur de a.

Pareil pour b = 3.

On appel f1.
Push de la frame 1.
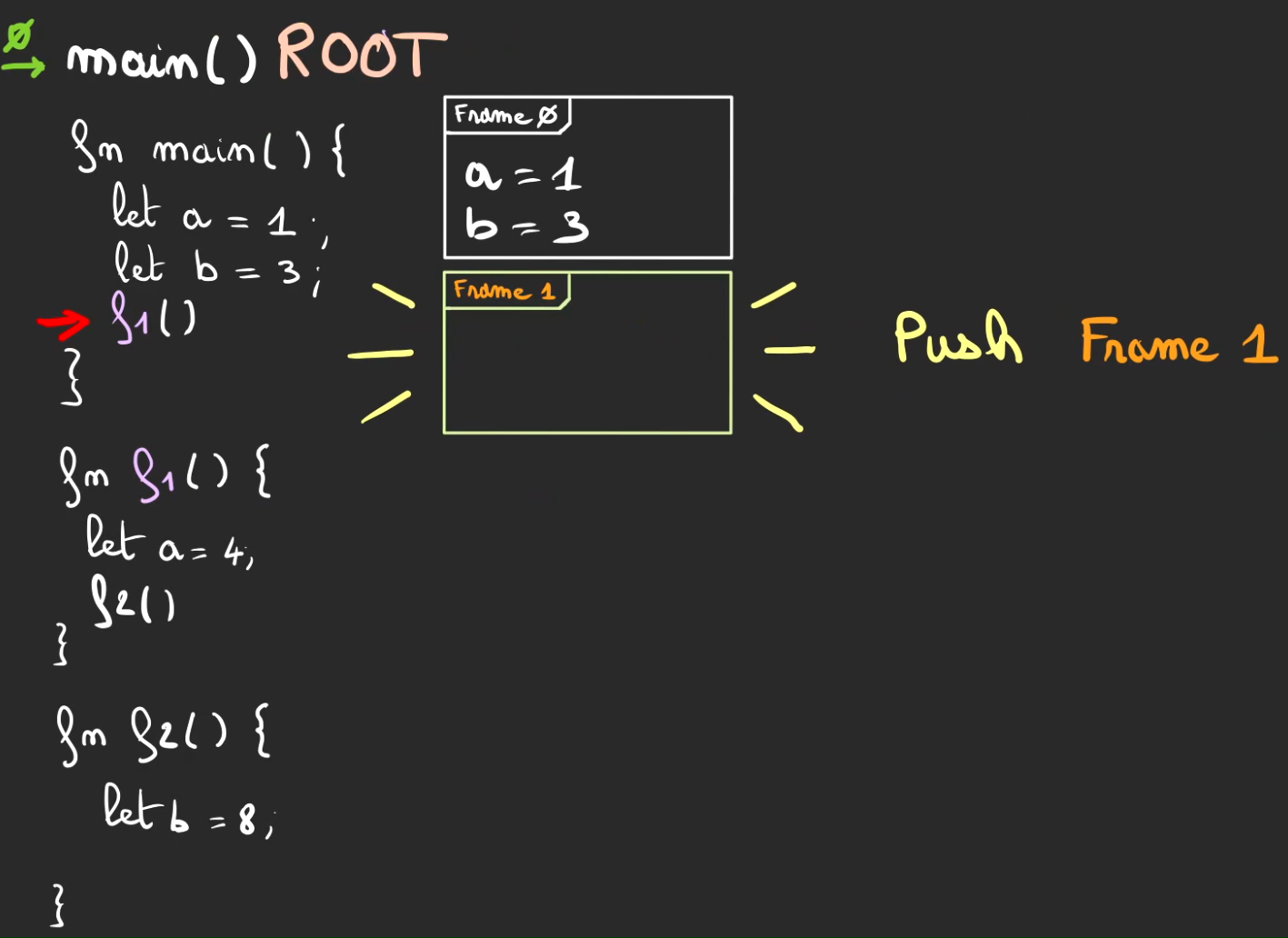
Switch de contexte vers f1. Les valeurs de a et b de la méthode main restent stockées dans la frame 0.

Ici aussi, on a également une affectation de a = 4. Mais ce n'est pas le même a, il ne s'agit pas du même contexte et par conséquent on peut avoir deux a dans deux contextes différents qui sont stockés dans deux frames différentes.

On appel f2, push de la frame 2.
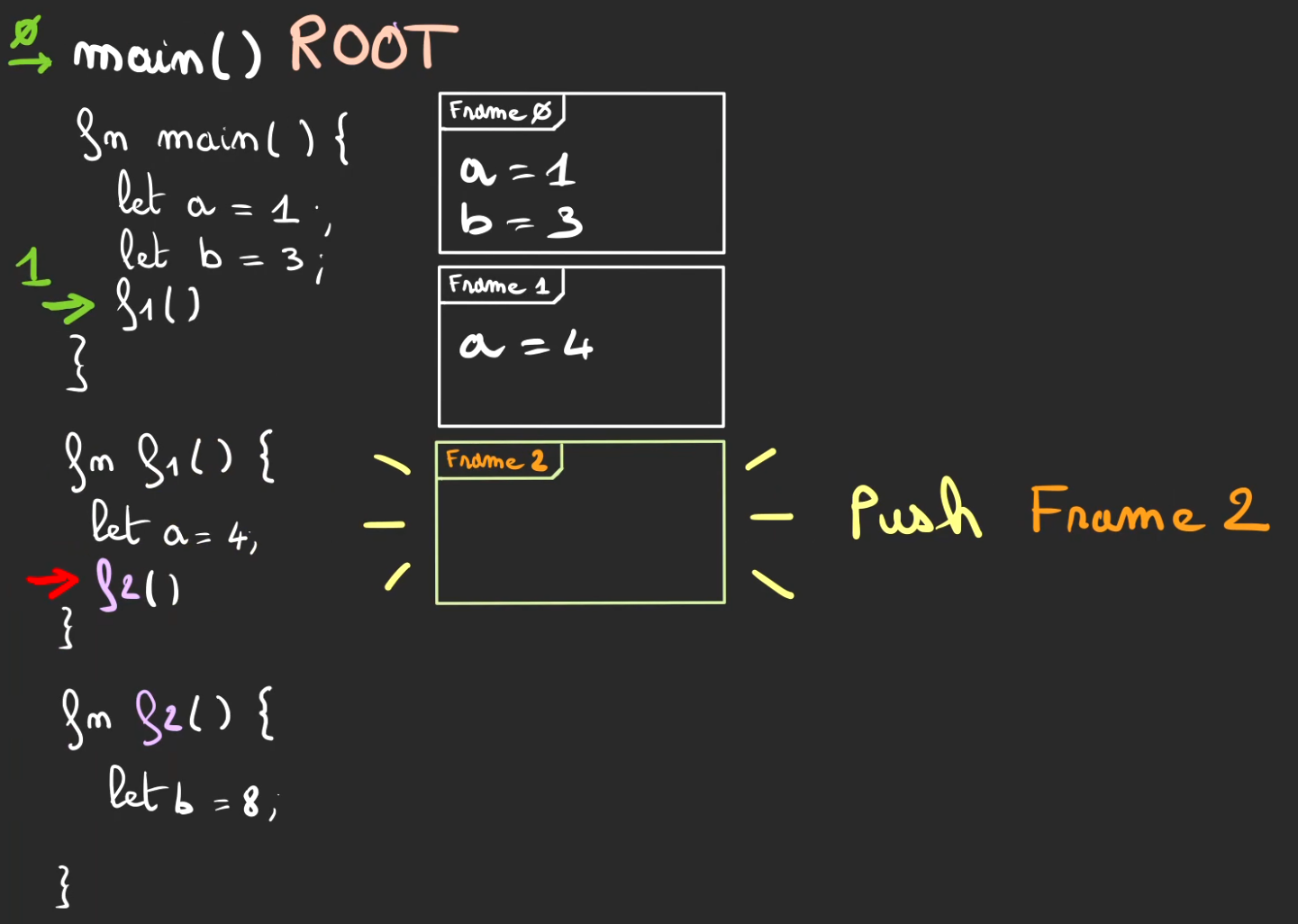
Switch de contexte vers f2.
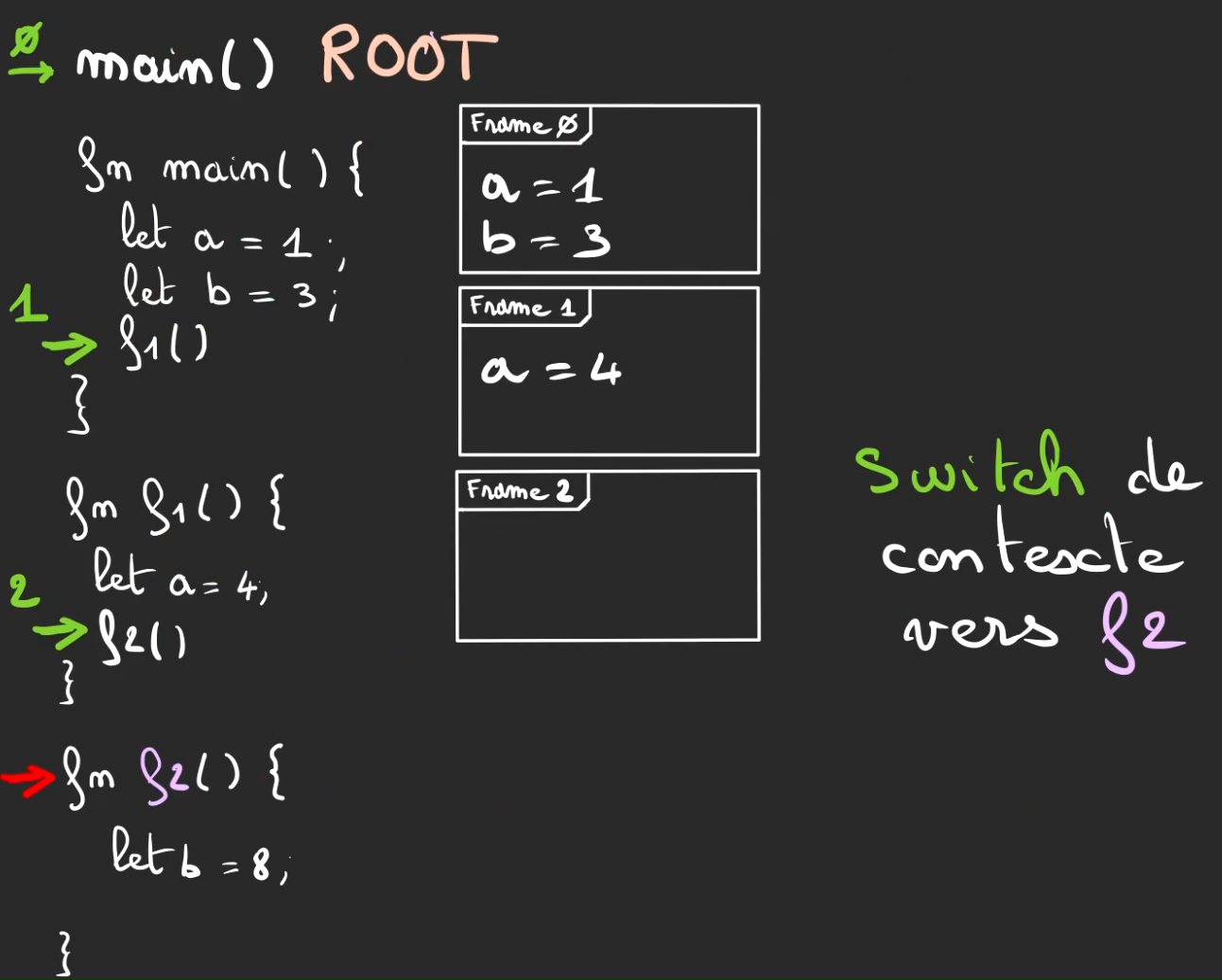
On affecte b = 8 qui est stocké dans la frame 2.

On arrive alors à la fin d'exécution de f2.
On effectue le retour de contexte vers f1.
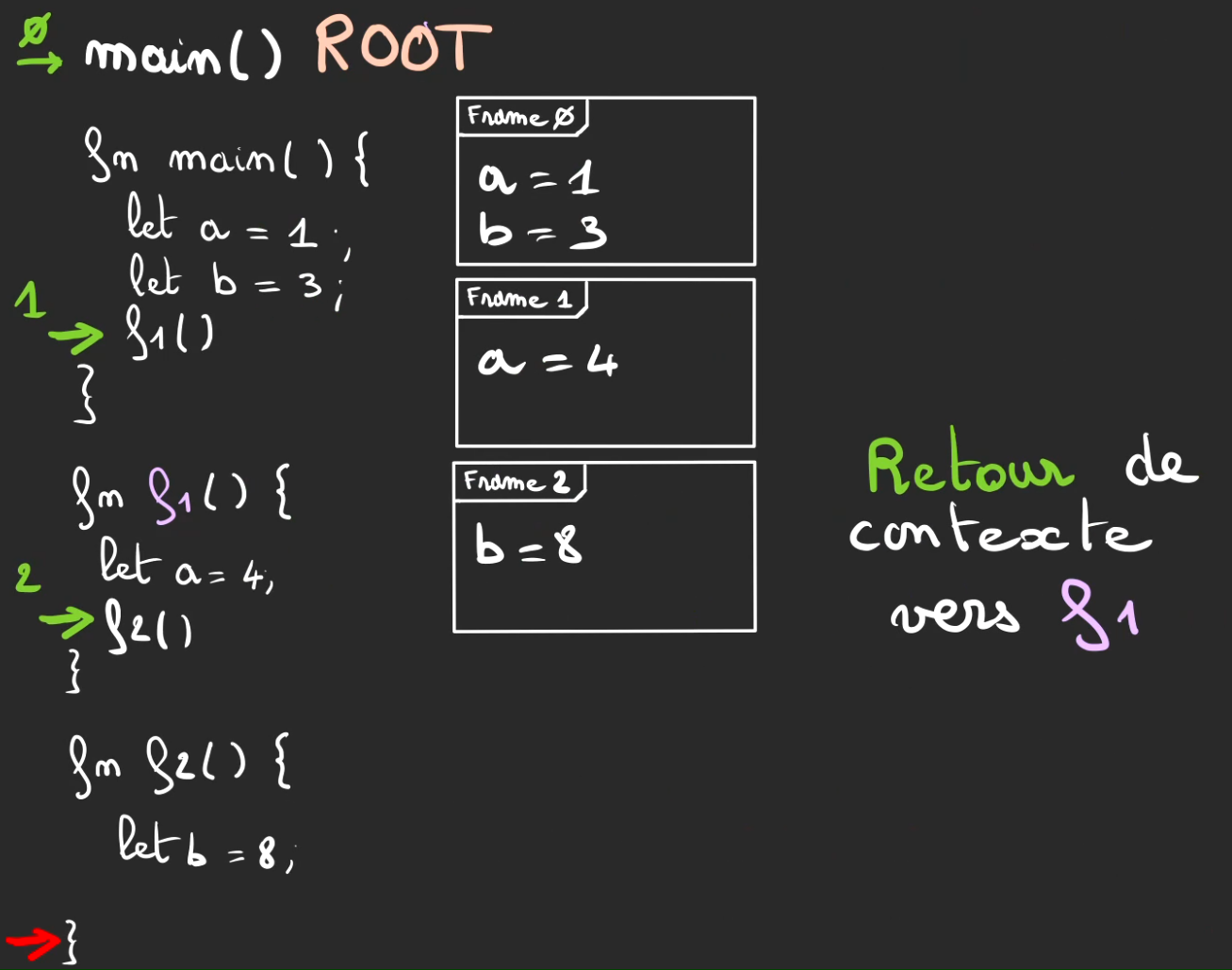
Puis le pop de la frame 2 avec tout ce qu'elle contient, et donc également b = 8.
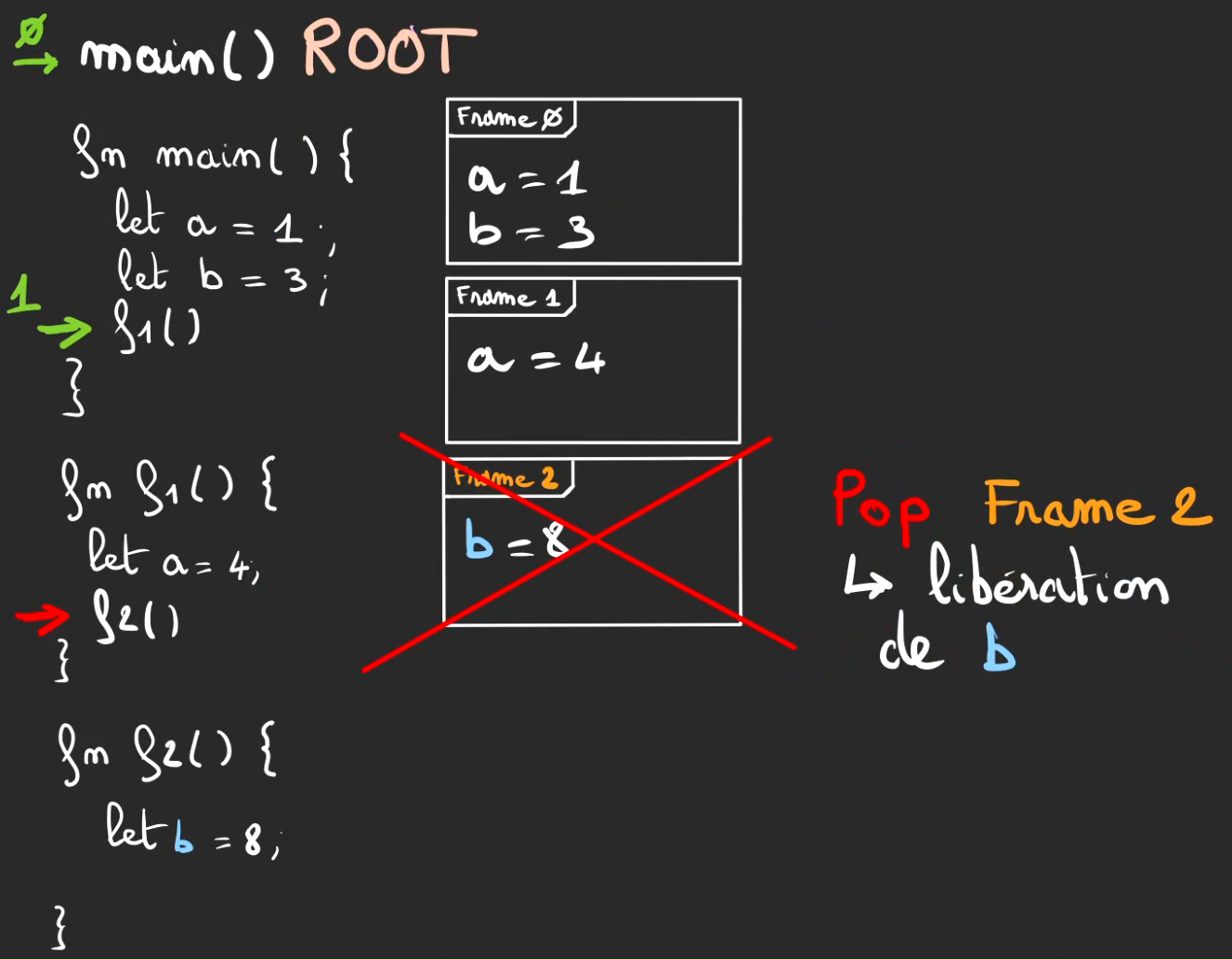
Puis on remonte dans l'exécution de notre pile.

On pop la frame 1. Et le a = 4.
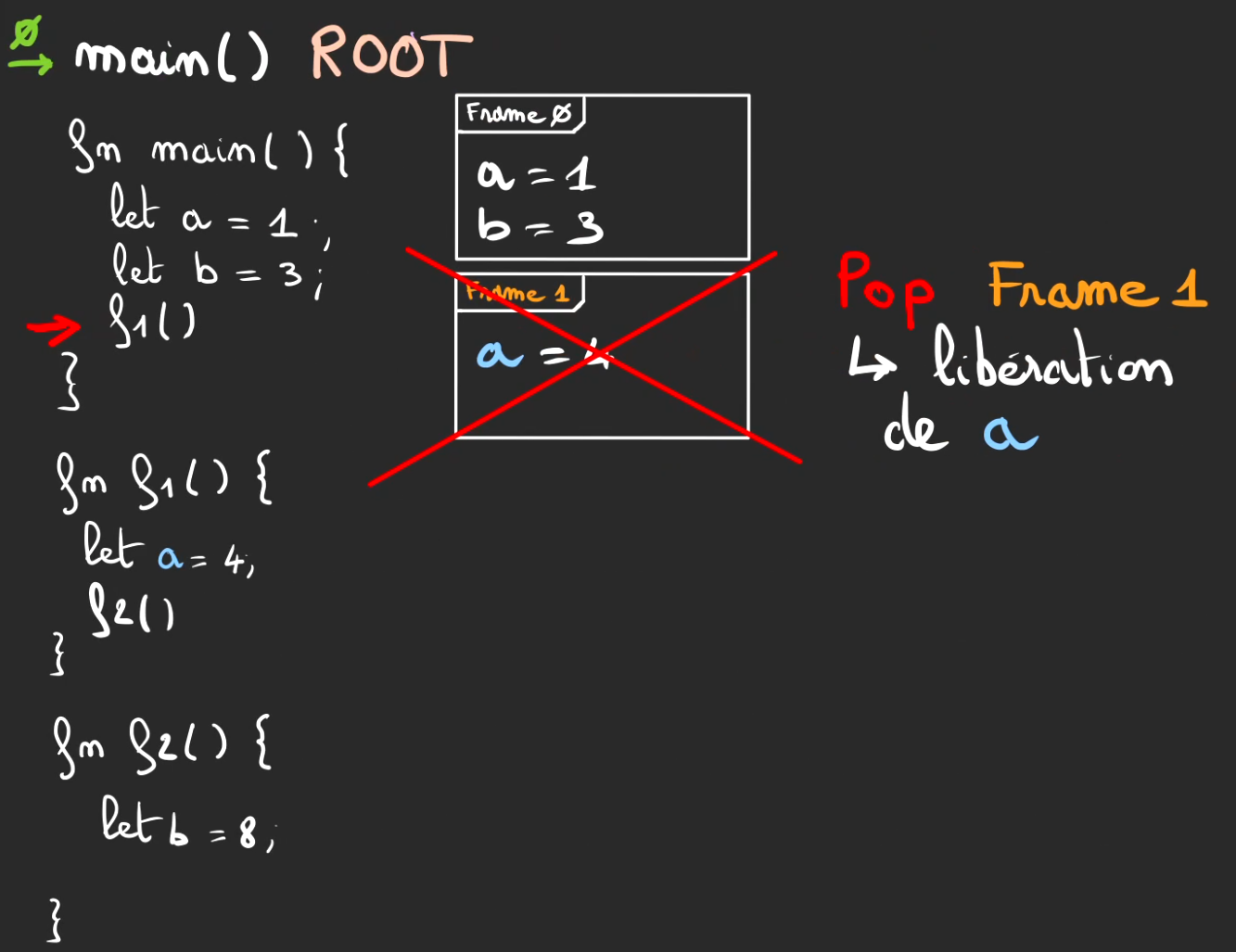
Et on continue à refermer ce qu'on avait ouvert.

Pour finalement nettoyer toute trace de notre passage en libérant a = 1 et b = 3 au pop de la frame 0.
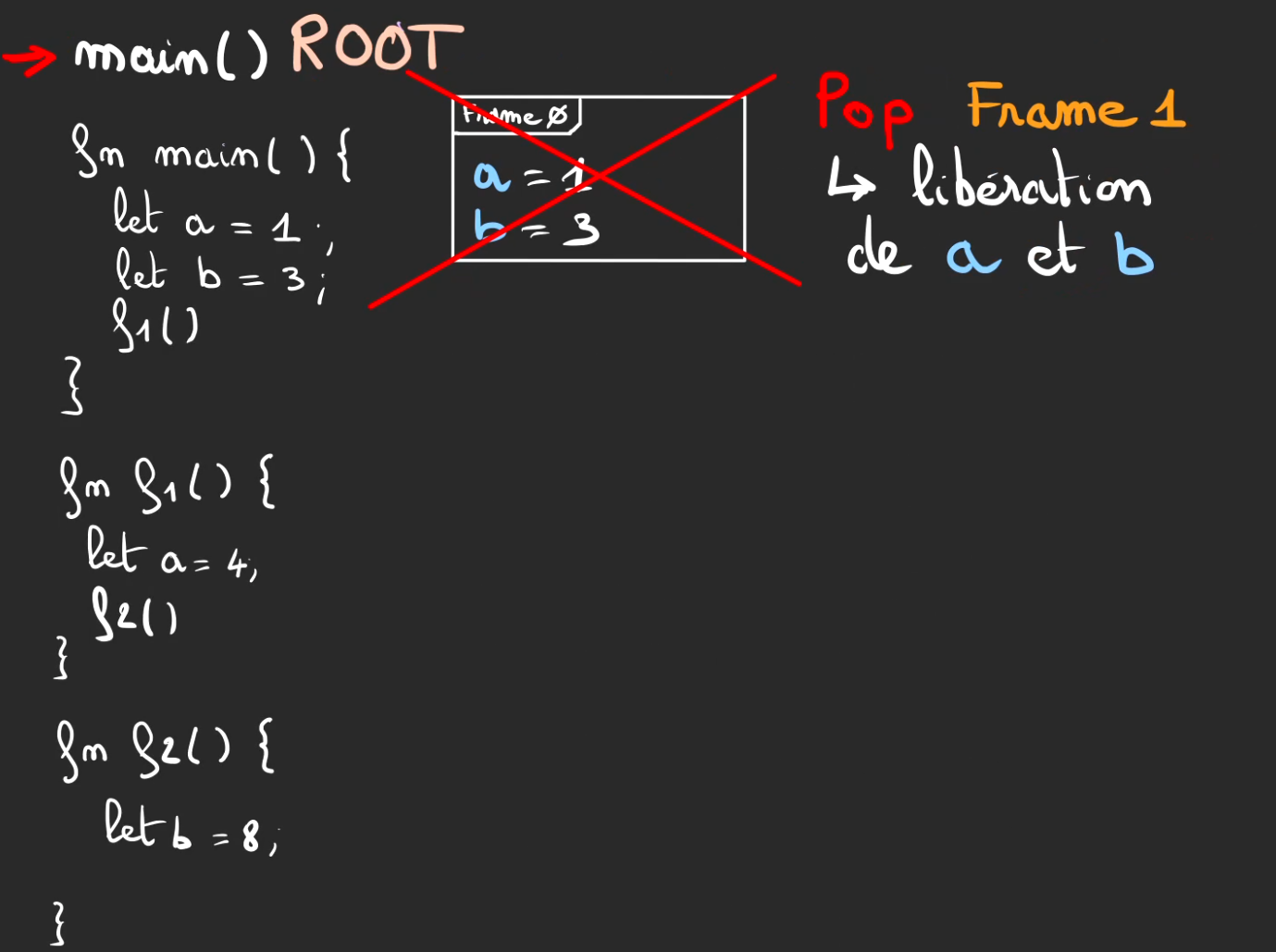
On fini alors l'exécution.

Ce qui est à comprendre ici est que ce qui est stocké dans une frame sera automatiquement nettoyé dès la fin de l'exécution du contexte.
Lors de notre article sur le Drop, j'ai utilisé une structure Toto.
;
Sauf qu'un code comme
Dans les faits rien ne se passe réellement, car de toute manière à l'issue de la fin d'exécution de f1 toto sera nettoyé avec la frame du contexte de f1. Il y a un risque nul de fuite mémoire.
Heap : On stocke en vrac
La Heap ou Tas est appelée ainsi, car contrairement à la Pile où il y avait un relatif ordre. Le Tas est organisé de manière anarchique, on y stocke ce que l'on a besoin dès qu'il y a la place pour y stocker quelque chose.
Si l'on reprend notre schéma de segmentation de la mémoire, nous allons nous retrouver avec ceci.

Des données, stockées pêle-mêle, pas forcément ordonnées dans leur ordre d'arrivée
String : vivre entre la Heap et la Stack
Un exemple de chose que l'on stocke dans le tas, sont les chaînes de caractères.
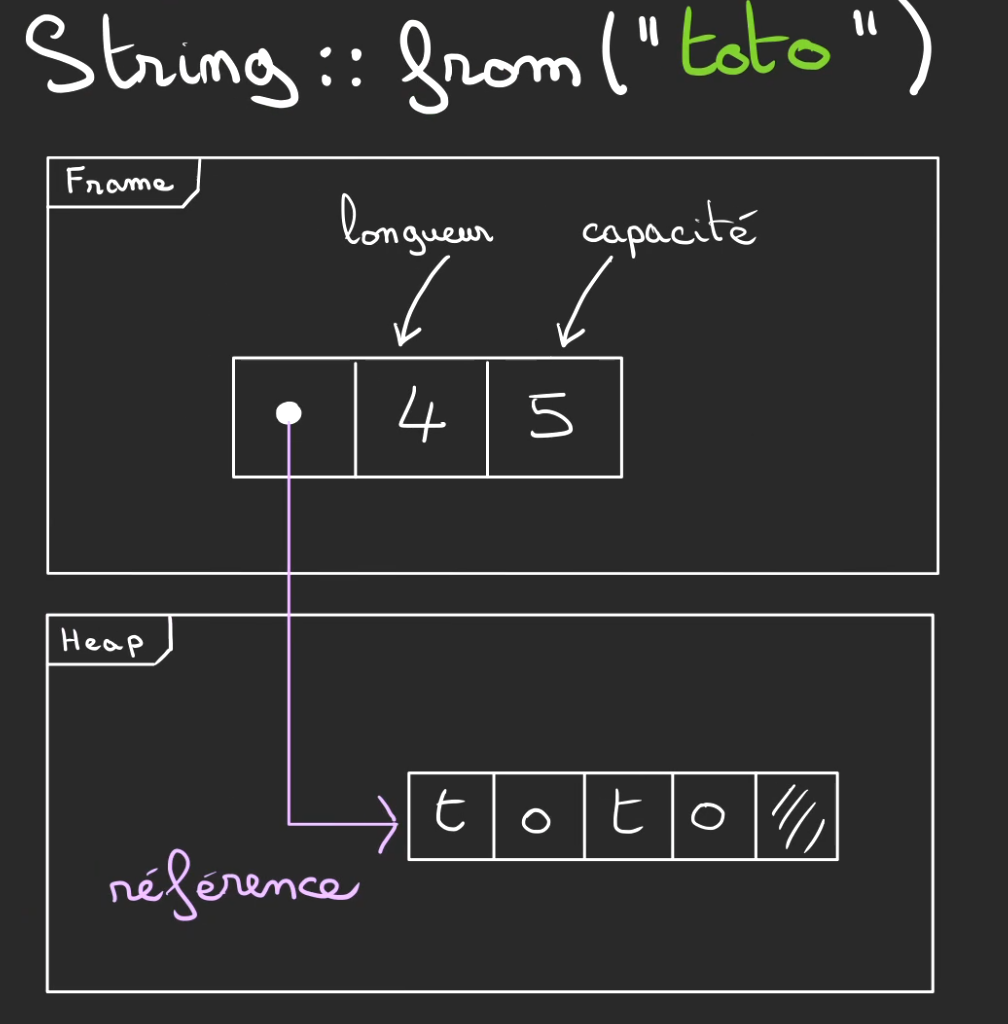
En Rust, il existe un type appelé String qui est une structure qui possède 3 champs principaux :
- la longueur de la chaîne de caractères
- la capacité de stockage actuel
- une référence vers la chaîne de caractères elle-même
Un article sera dédié aux chaînes de caractères tellement c'est complexe comme sujet mais, ce qu'il faut retenir c'est qu'il s'agit de nombre qui sont stockés et interprétés par la suite comme des lettres et des chiffres ou tout autre caractère.
Ce tableau de nombre est stocké dans la Heap tandis que la structure vit dans une frame et donc dans la Stack.
Ici ce tableau est composé de 5 cases, car notre String a une capacité de 5 et une longueur de 4, car on utilise réellement 4 cases pour écrire t·o·t·o.
La dernière case est non-définie mais allouée à notre String. Autrement dit, personne d'autre ne peut lui voler cette case, même si elle est inutilisée.
Allouer dans la Heap
Voyons ce qu'il se passe lors de la création d'un String.
La première chose qui est faite est de créer la structure String, pour cela, on compte le nombre de cases qu'il faut pour stocker ce que l'on a besoin et on rajoute un petit extra. Ici, on a une longueur de 4, mais une capacité de 5.
On vient alors allouer 5 cases dans la Heap. Ces cases sont désormais à la String s ! Personne d'autre ne pourra les récupérer.
Lorsque l'allocation est terminée, l'adresse du début de bloc alloué est retournée ce qui permet alors à notre structure String s d'y faire référence par la suite.

La manière de définir cette capacité est un algorithme qui peut varier.
Pour des raisons de lisibilité sur le dessin, je me limite à 1 case supplémentaire mais il est probable que dans la réalité, on alloue plutôt le double de la longueur histoire d'être tranquille.
On peut alors y écrire les nombres qui représentent t·o·t·o.
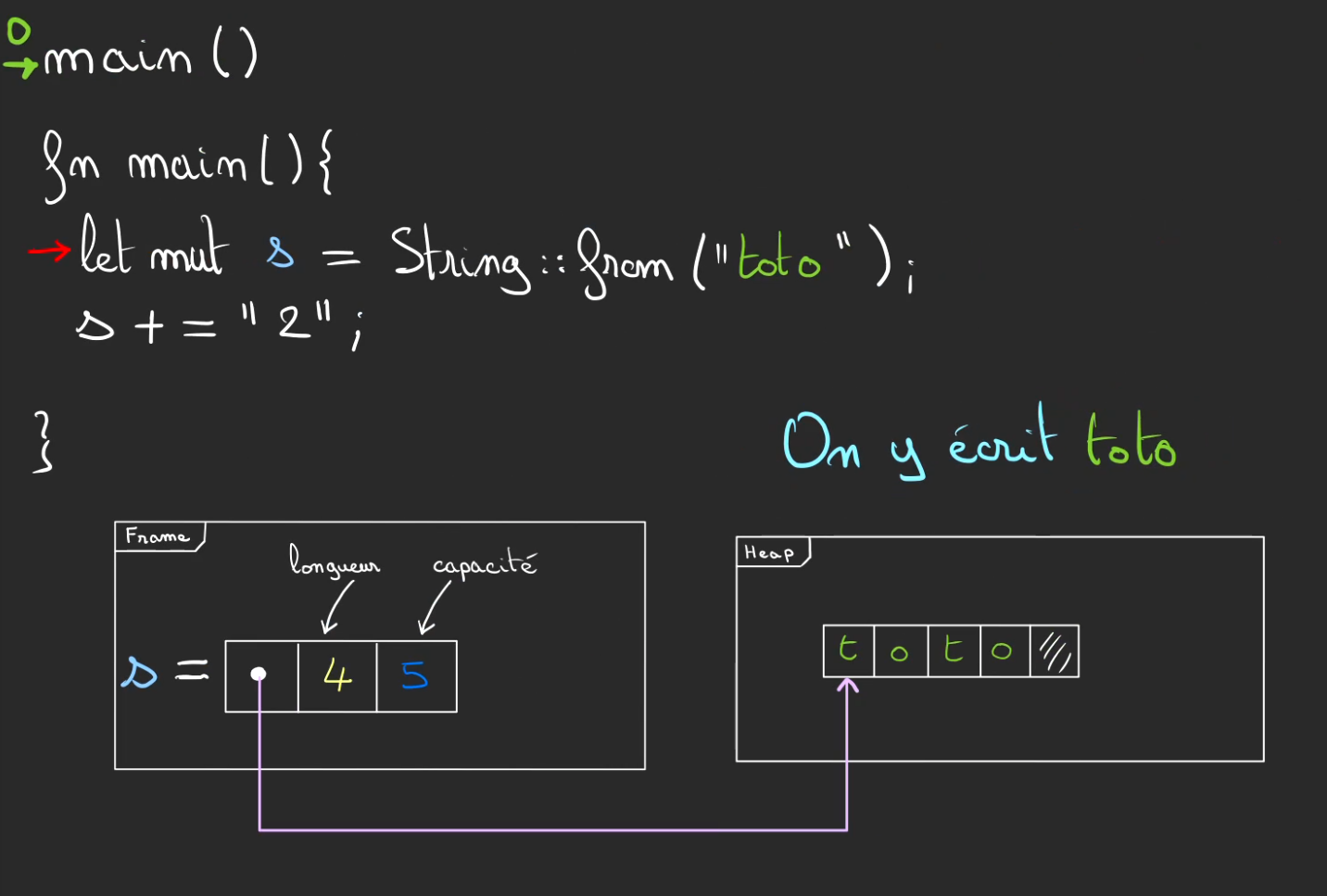
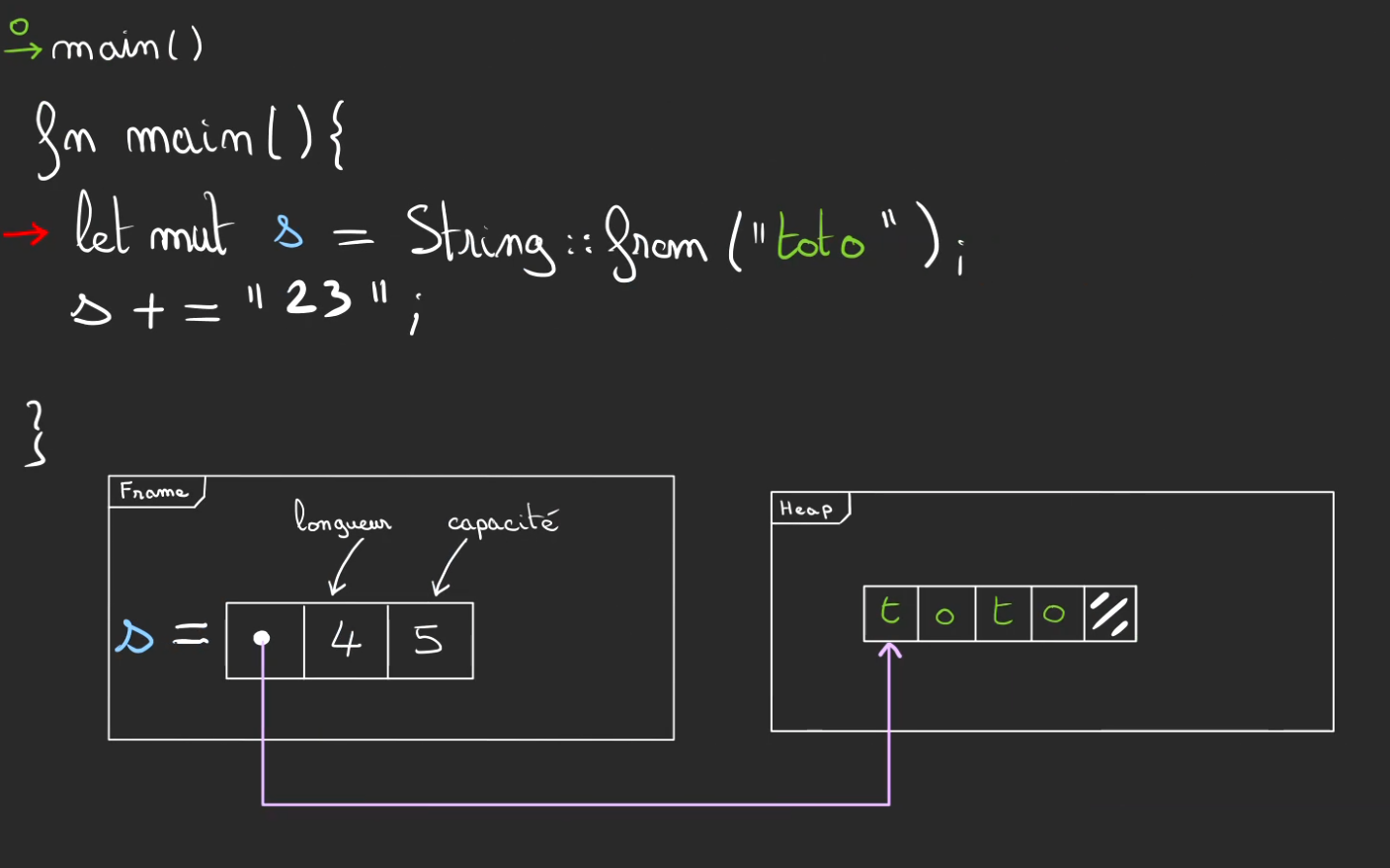
Lorsque l'on veut modifier s, ici par exemple concaténer avec la chaîne "2".
On vérifie la taille de ce qui doit être ajouté, si celle-ci ne dépasse pas la capacité restante alors on modifie les cases mémoires dans la heap.

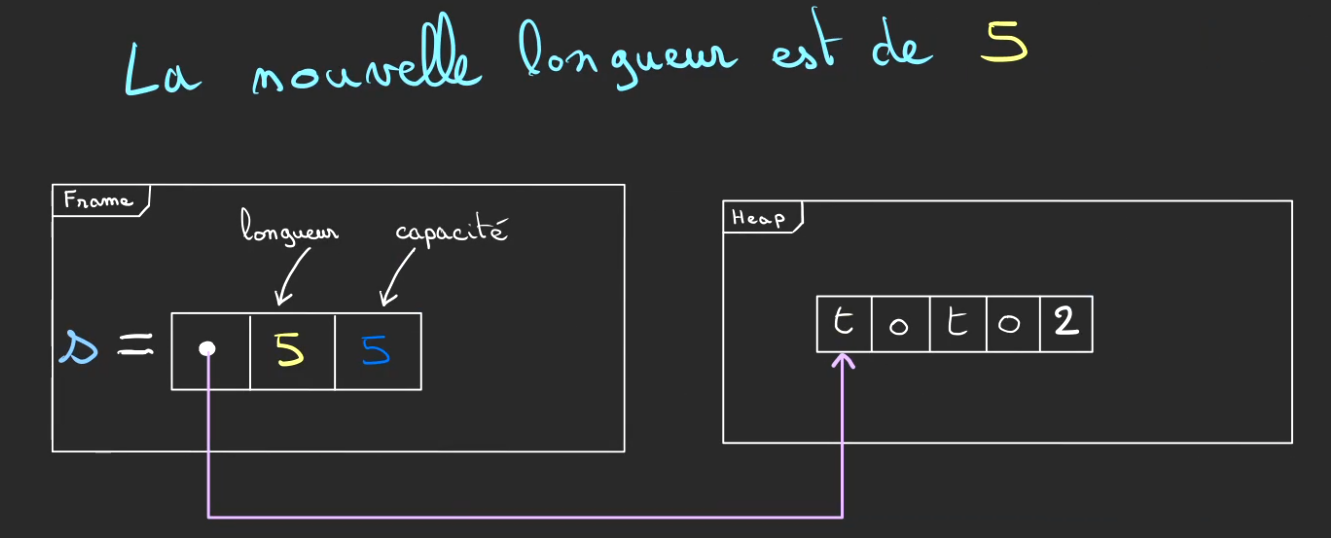
Et l'on fait évoluer la nouvelle longueur à 5.
La capacité reste inchangée.
C'est maintenant que l'on raccroche les wagons avec l'article sur le Drop.
A l'issue de la méthode main, suivant les règles du borrow checker, comme plus aucune référence n'est valide alors il doit être drop.

Ce signal Drop a pour conséquence de déclencher le mécanisme de libération de la zone mémoire allouée dans la heap précédemment pour stocker nos 5 caractères.
C'est donc ce que l'on va demander :
Libère les 5 cases mémoire que tu m'avais prêtées précédemment
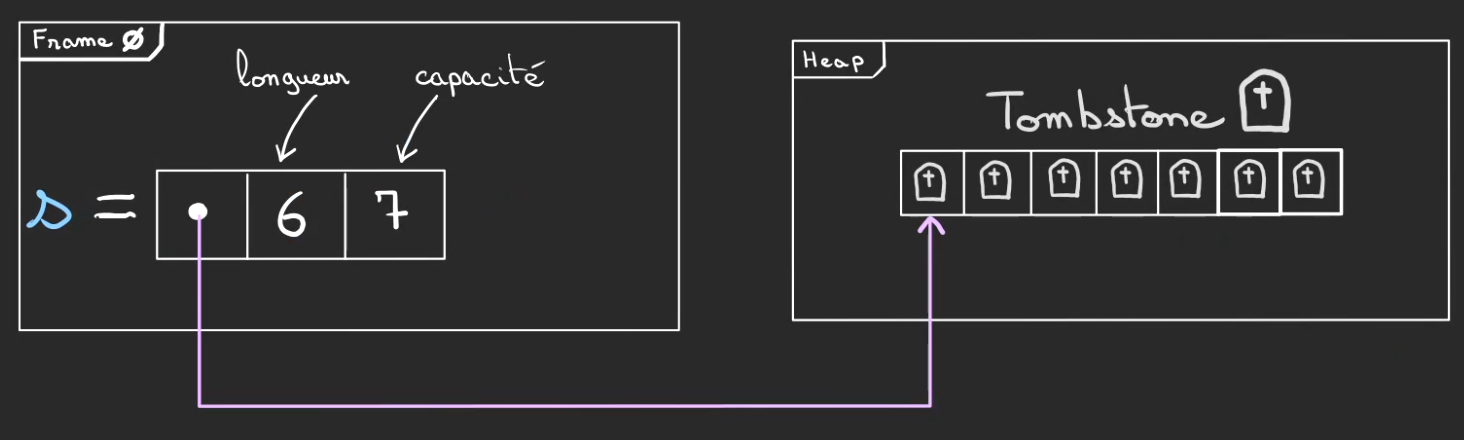
Ce qui va alors se passer, c'est que l'on ne va pas effacer les données, ça pourrait être bien trop coûteux en temps en fonction de la taille de ce qui a été alloué (parfois plusieurs Giga octets).
A la place, on va marquer ces cases comme étant "libres". On nomme ça un tombstone ou pierre tombale en anglais.
Cela signifie que les données qui sont présentes à ces adresses ne veulent plus rien dire et peuvent être réécrites par une autre allocation.

On termine l'exécution du programme en poppant la frame de main. Ce qui nettoie la variable s mais comme le Drop a déjà libéré la mémoire, pas non plus de risque de fuite mémoire.
Tout s'est passé automatiquement et le développeur ou la développeuse n'a jamais eu besoin d'y penser.
On manipule la chaîne de caractères, puis quand on en a plus besoin le borrow checker fait le travail à notre place et nettoie ce qu'il y a besoin de nettoyer. 🤩
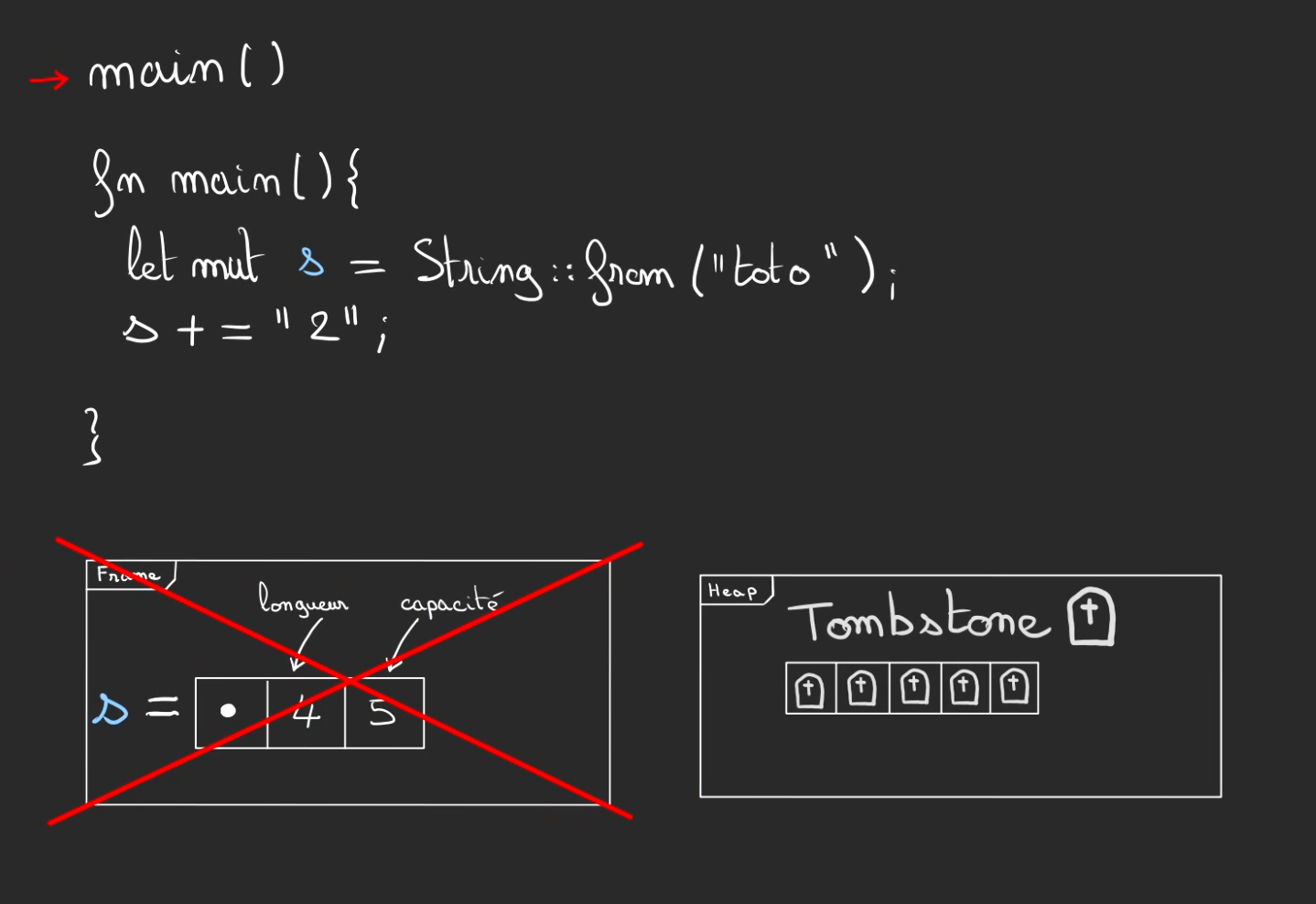
Réallocation : Ça dépend, ça dépasse
On reprend la même situation après allocation de "toto".
Cette fois-ci la longueur ce que le l'on veut rajouter est de 2. Ce qui excède la capacité de 5.
Nous allons avoir besoin de réallouer de la place supplémentaire.
On rajoute alors plusieurs cases, ici 2 de plus.
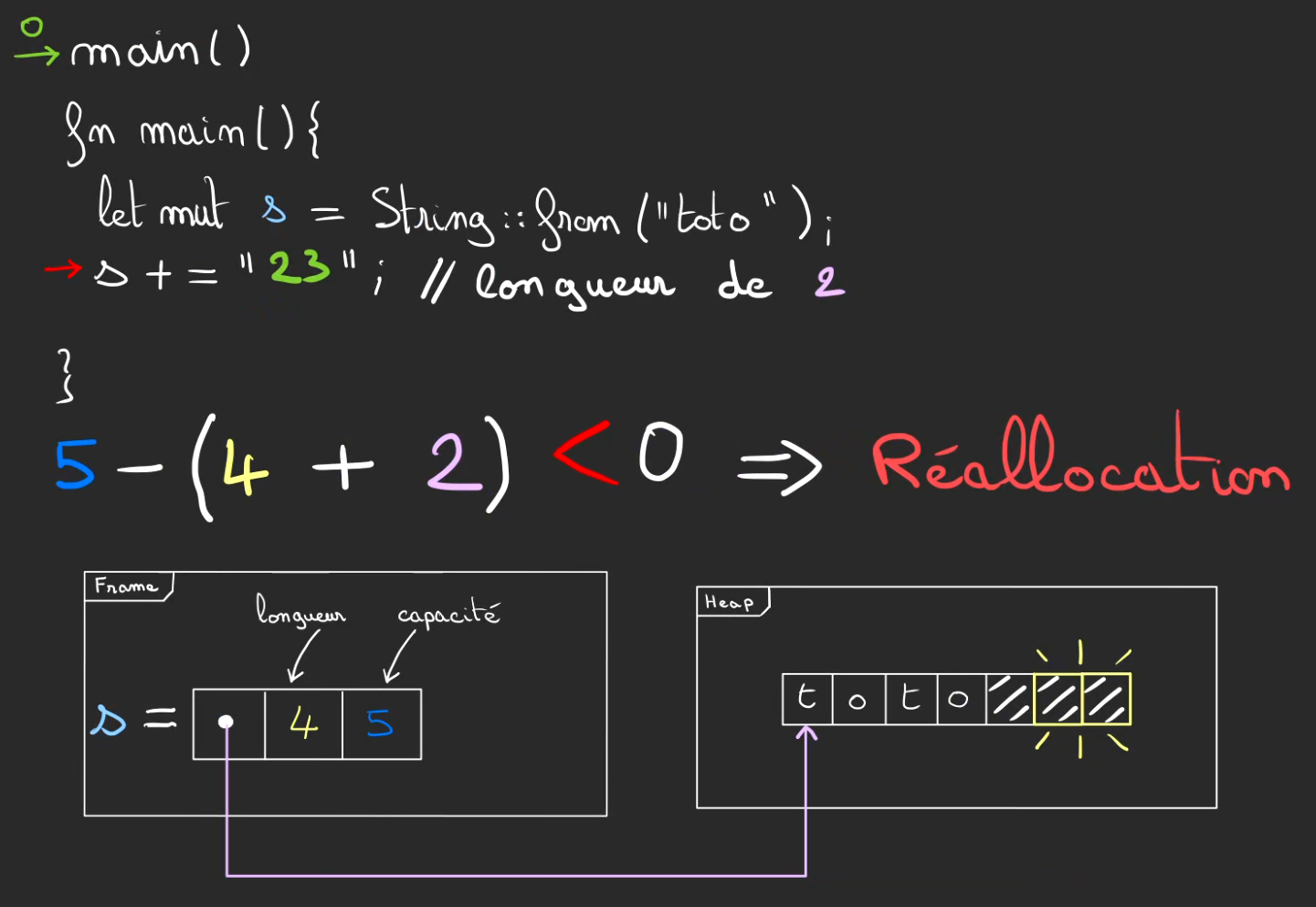
La nouvelle capacité devient 7 et la longueur devient 6.

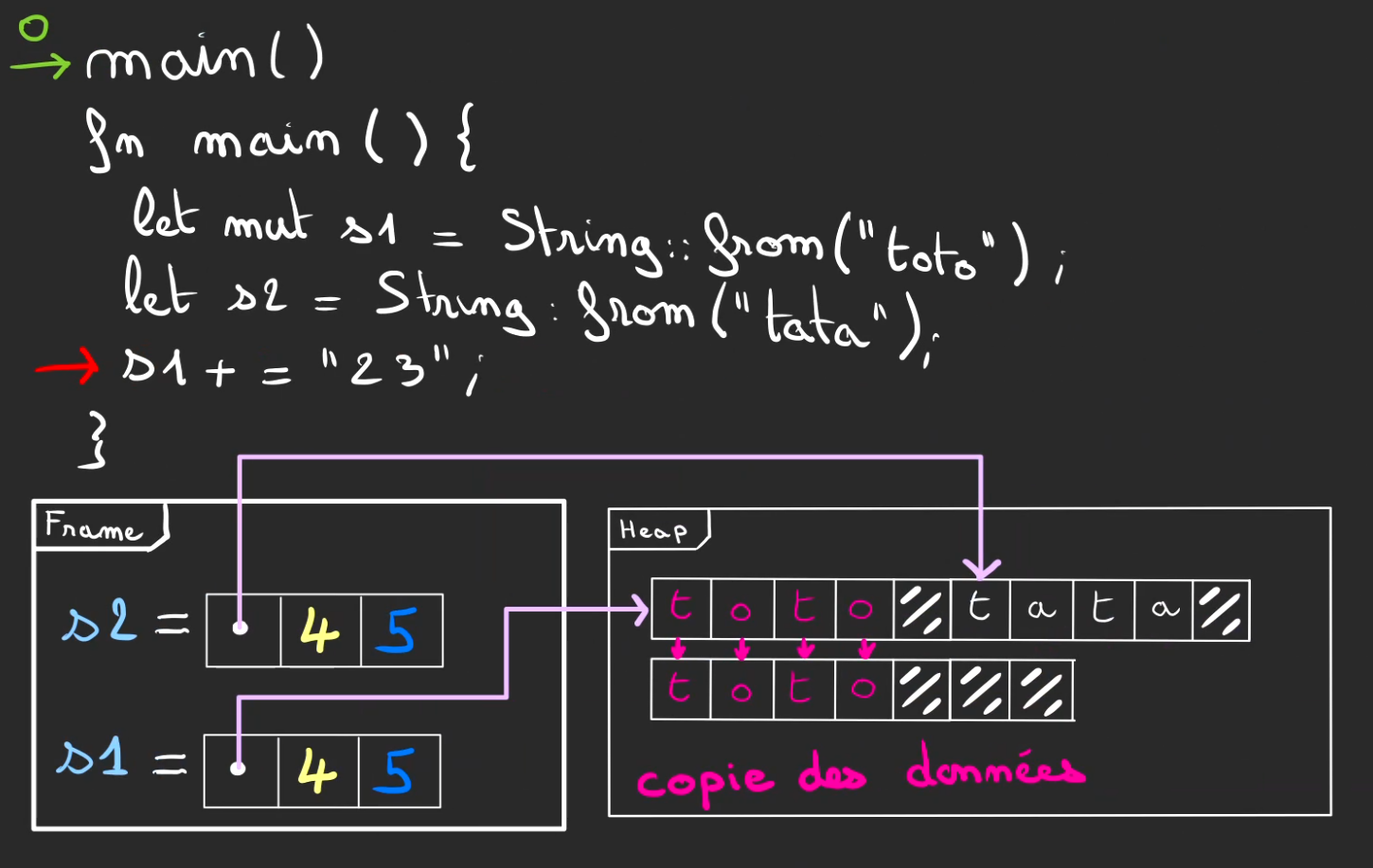
Allouons deux String, s1 et s2.
Le hasard de l'allocation, va localiser côte à côte les deux chaînes de caractères.

Là aussi pas de place pour stocker le "toto23". On doit réallouer.
Mais cette réallocation est différente, on ne peut pas juste rajouter des blocs.
On doit tout réallouer ailleurs, là où il y a de la place.
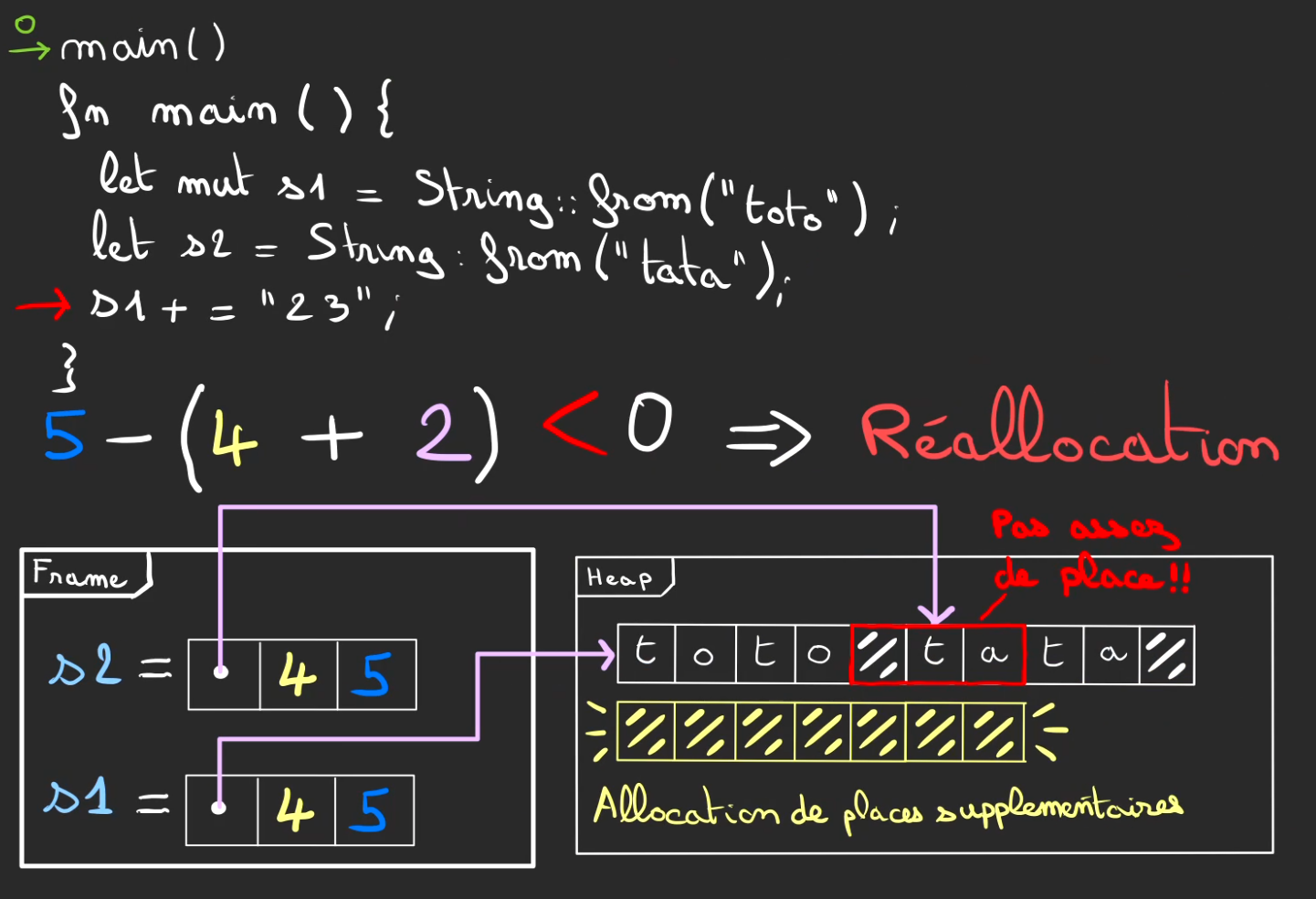
On peut alors copier les valeurs des blocs précédents dans les nouveaux blocs alloués.
On peut alors modifier la zone mémoire pointée.
Modifier la capacité.
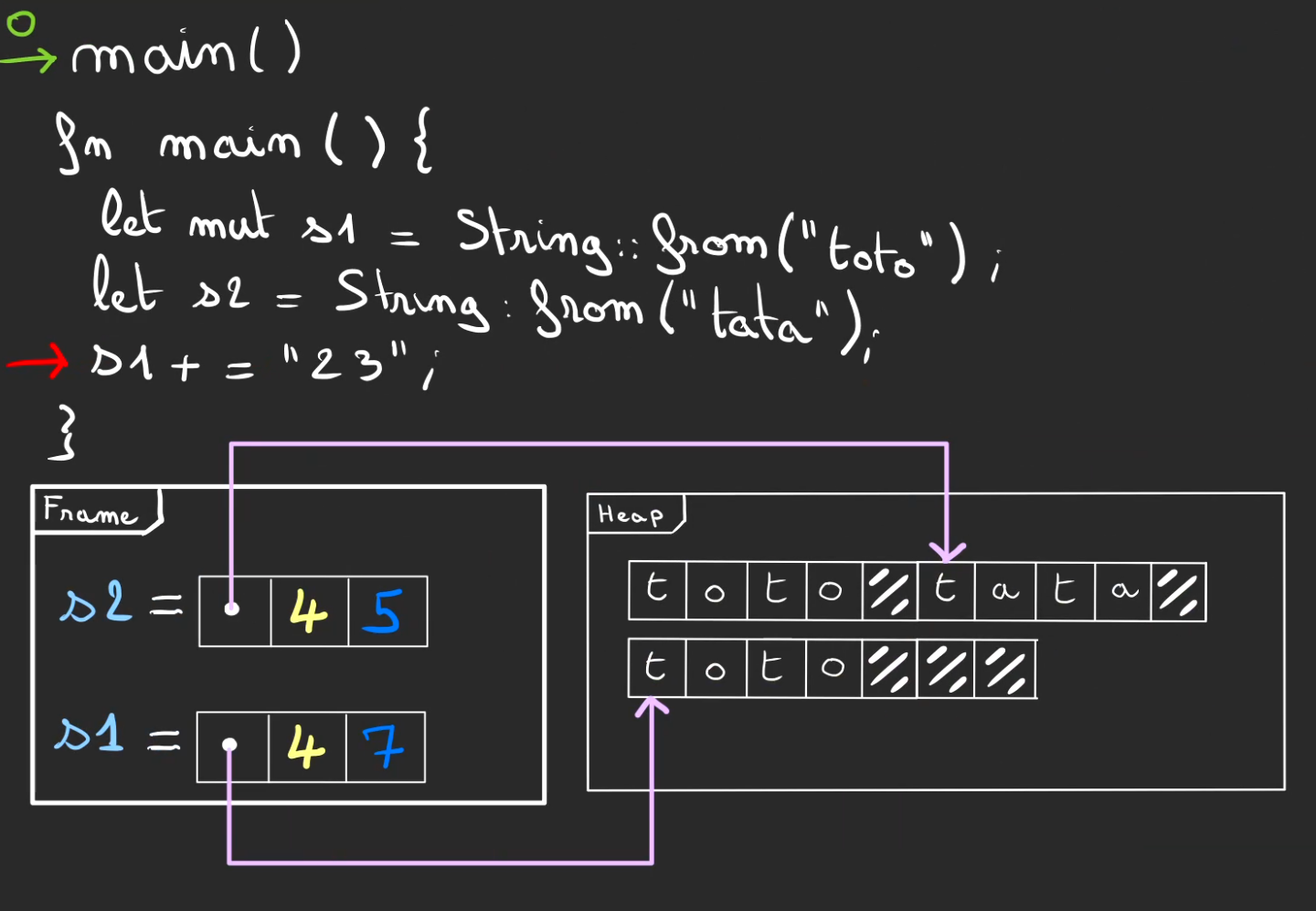
Libérer l'ancienne zone allouée.

On peut finalement faire que l'on désirait, et écrire "toto23".

Tant qu'il y a de la place on peut toujours réallouer.
Référence chaînée
Nouvelle situation.
Cette fois-ci, la fonction f1 prend une référence de String.
En Rust, le caractère *, permet de déréférencer. Autrement dit, remonter la piste de la référence.
Un mécanisme au sein de la structure String, permet d'automatiquement déréférencer vers la zone mémoire de la heap qui permet de stocker la chaîne de caractères.

La ligne
*s_ref += "23"
est identique en action à
s += "23"

De fait, on a le même système de réallocation de mémoire.
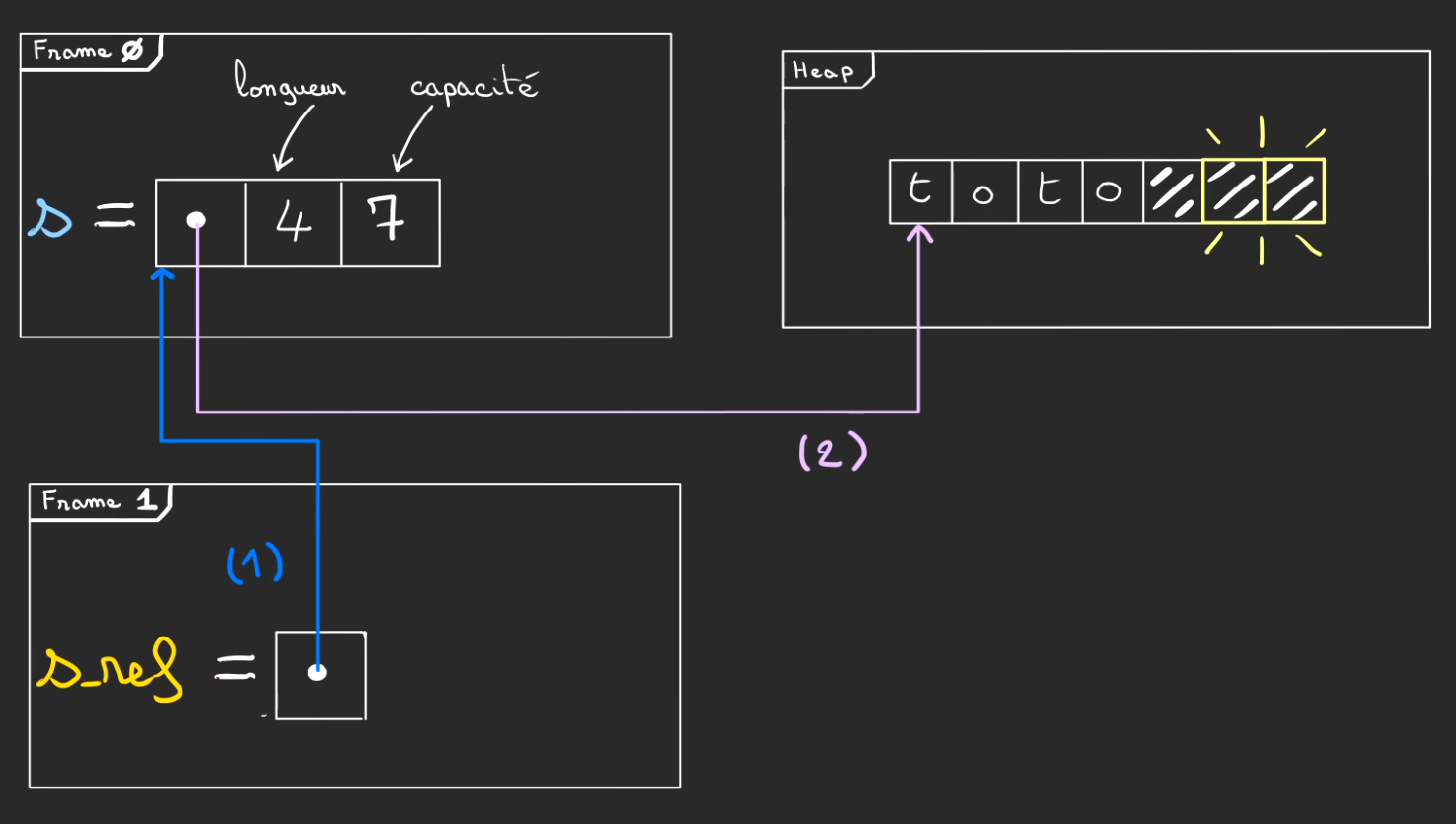
Puis d'affection des nouvelles cases.
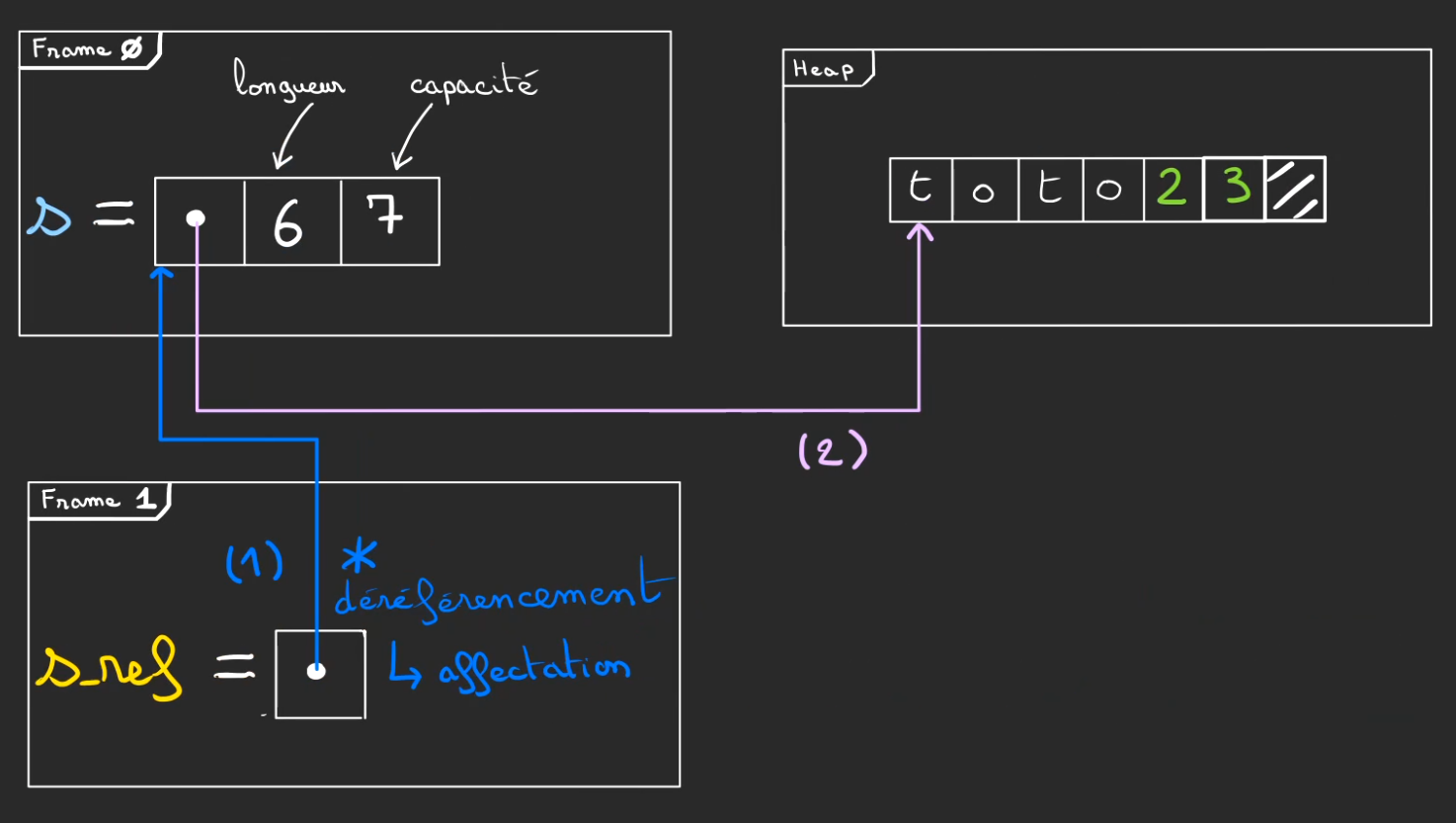
En fin de fonction f1, le borrow se termine mais comme la variable s vit toujours dans main.
Il n'y aura pas de Drop à lissue de f1.
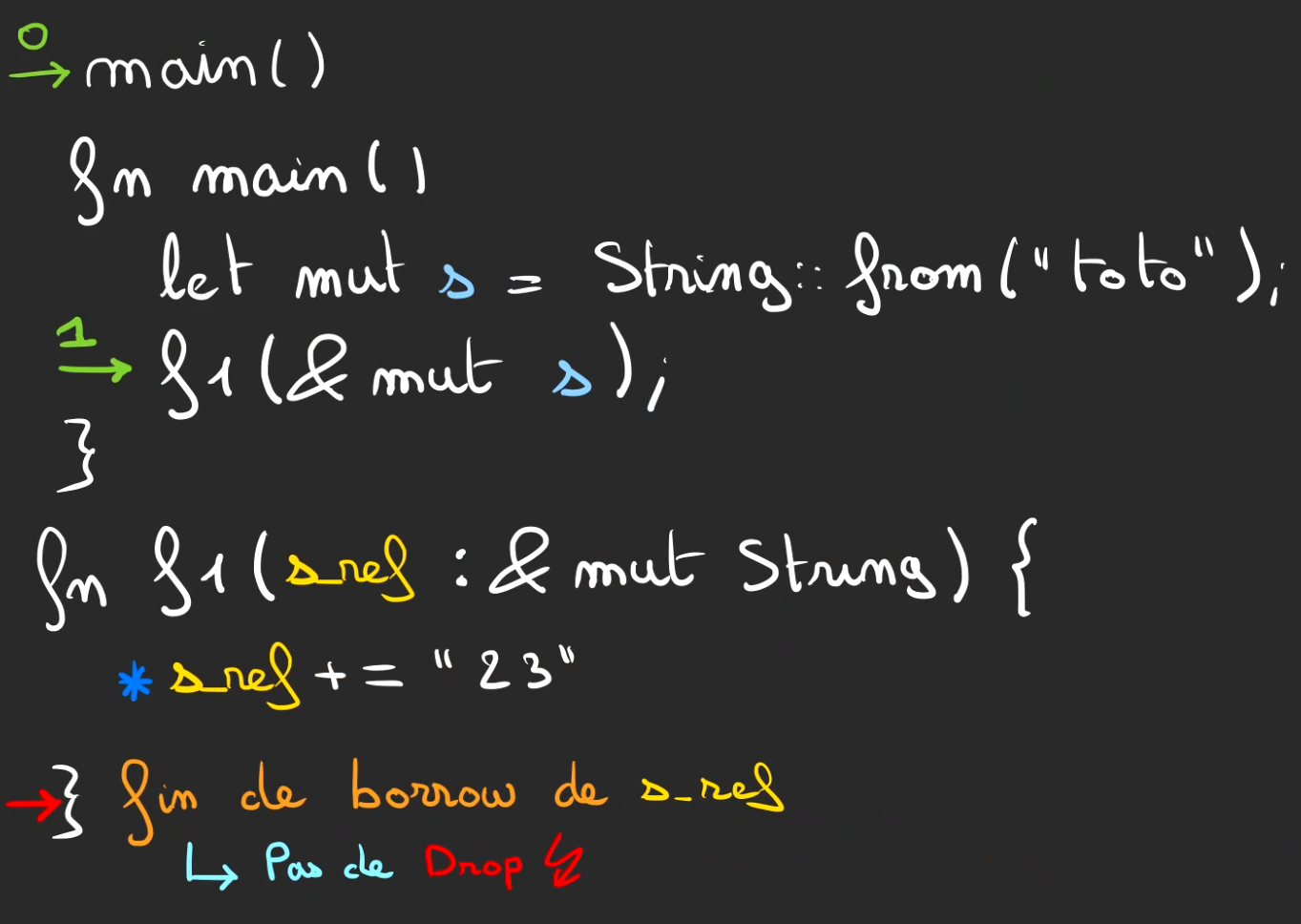
A lissue de f1, on pop la frame 1 contenant la s_ref.
Mais sans drop.

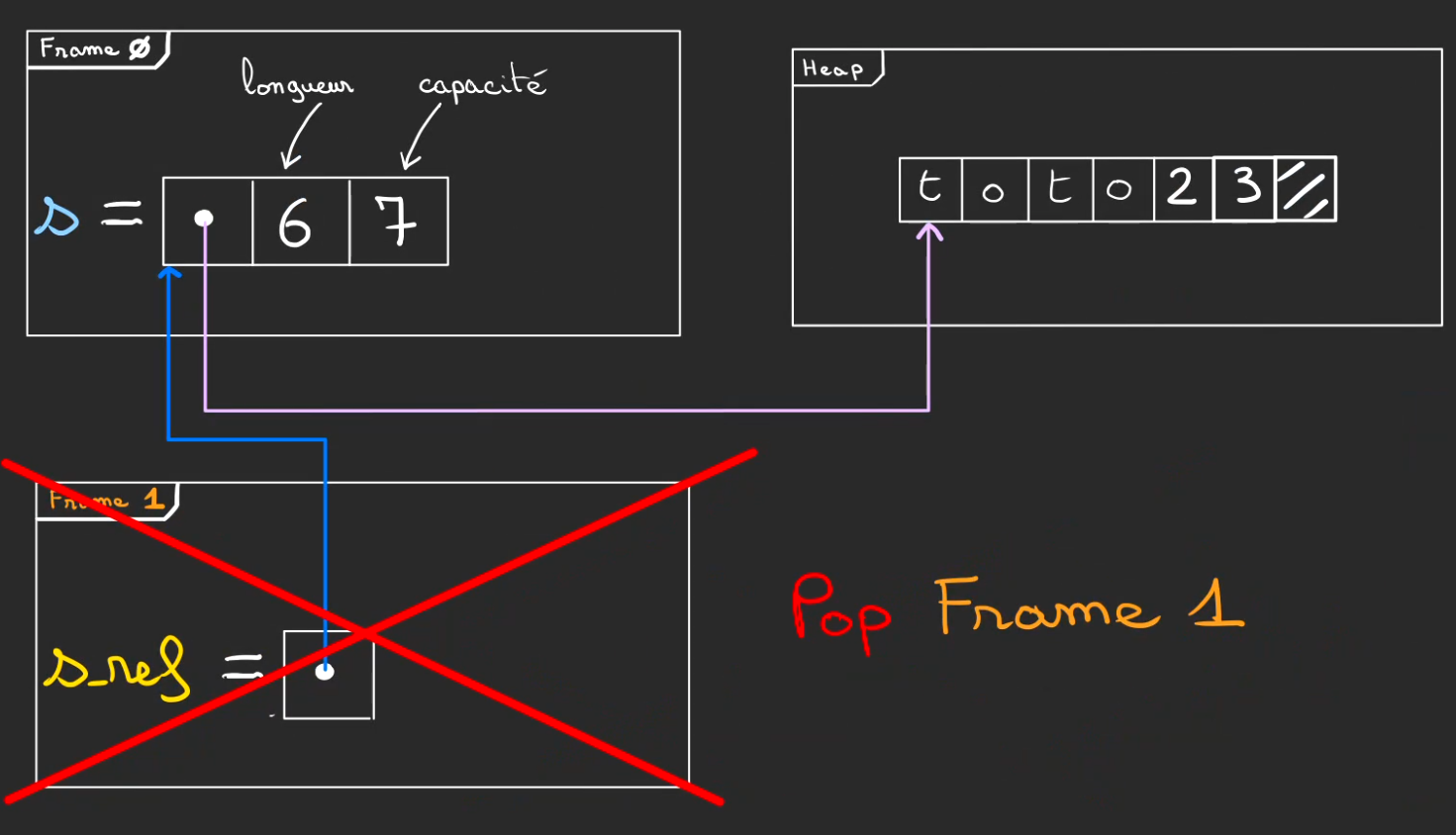
Par contre à l'issue de main.

Le mécanisme de Drop se déclenche.
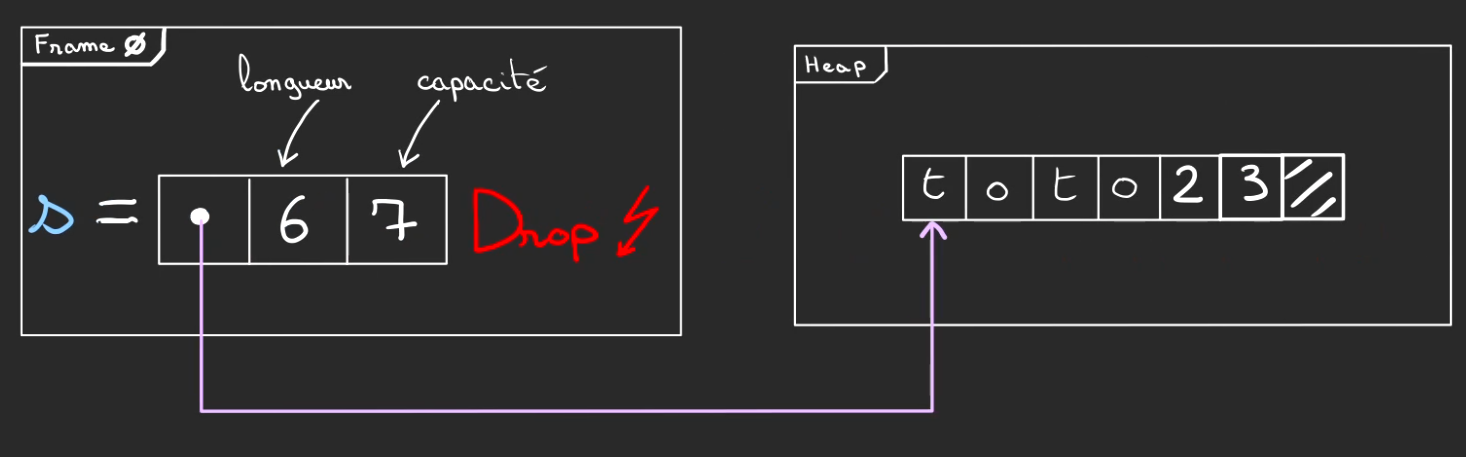
Puis finalement, on peut libérer la zone de la heap allouée pour s.
Retour de fonction
On va complexifier un peu les choses. 😁
On crée une structure Person qui possède 2 champs:
- age un
u8 - name un
String
On défini également une méthode with_name qui un &Person, un &str et renvoie une Person.
Nous nous retrouvons dans la situation où une Person a déjà été créée.

On a alors une zone dans la frame de la pile qui contient à la fois la String et le u8.
Et dans la heap, la chaîne de caractères allouée pour s.name.
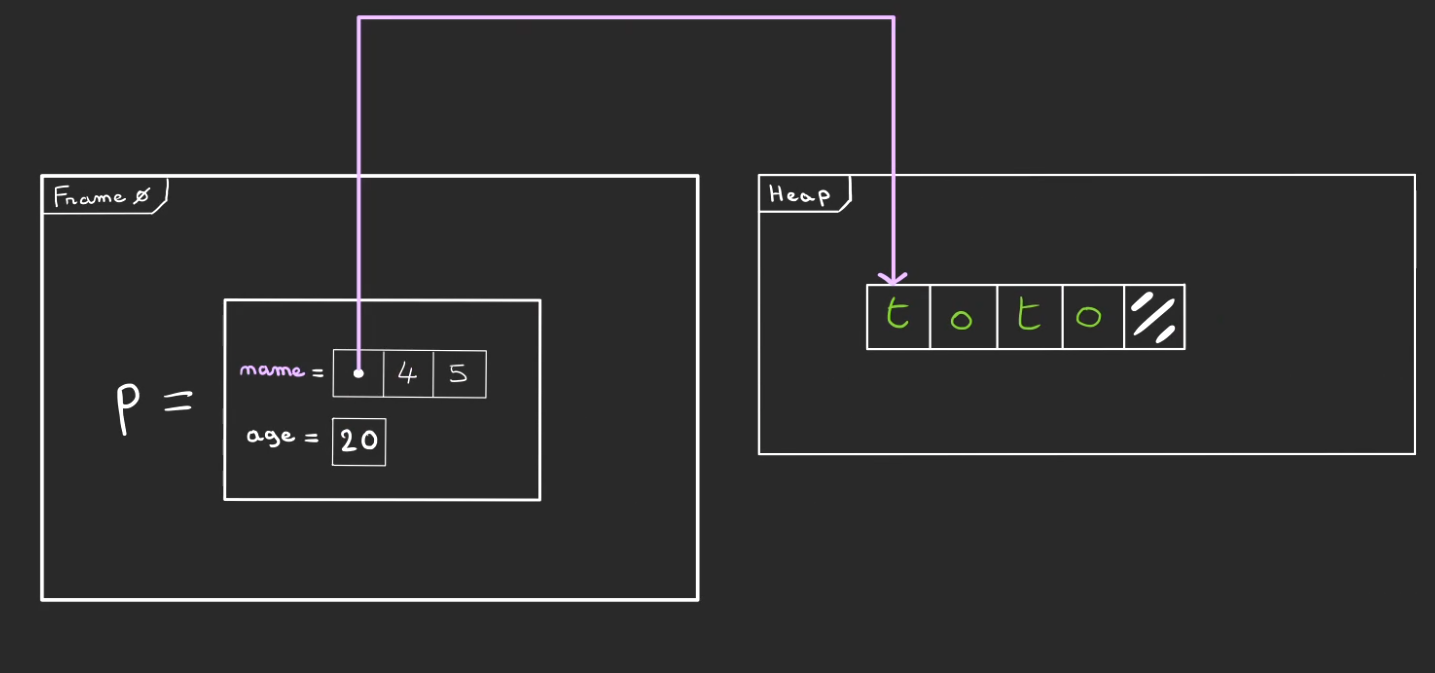
On avance un peu dans le temps, on atteint l'appel à la méthode Person::with_name.
On lui fourni à la fois une reférence vers p, mais aussi une chaîne de caractères.

Dans la frame 1 de Person::with_name, nous nous retrouvons donc avec:
Une reference à p sous la dénomination self, p qui vit dans la frame 0 de main.
Une référence name qui pointe ailleurs que dans la heap ou sur la frame 0. Cet "ailleurs" est le segment de mémoire Statique.
Il s'agit d'une zone spéciale de la mémoire qui est allouée automatiquement au début du programme et qui ne peut pas évoluer au cours de celui-ci. De plus ce qui est dedans vit tout au long du programme et n'est jamais libéré.
name lui-même est spécial, ce n'est pas seulement une référence, c'est ce que l'on nomme une slice. C'est une référence qui est au courant de la taille de ce qu'elle référence. Généralement un tableau. Cela tombe bien, une chaîne de caractères est un tableau ! 😄
Ici notre &str pointe vers une chaîne de 4 cases.
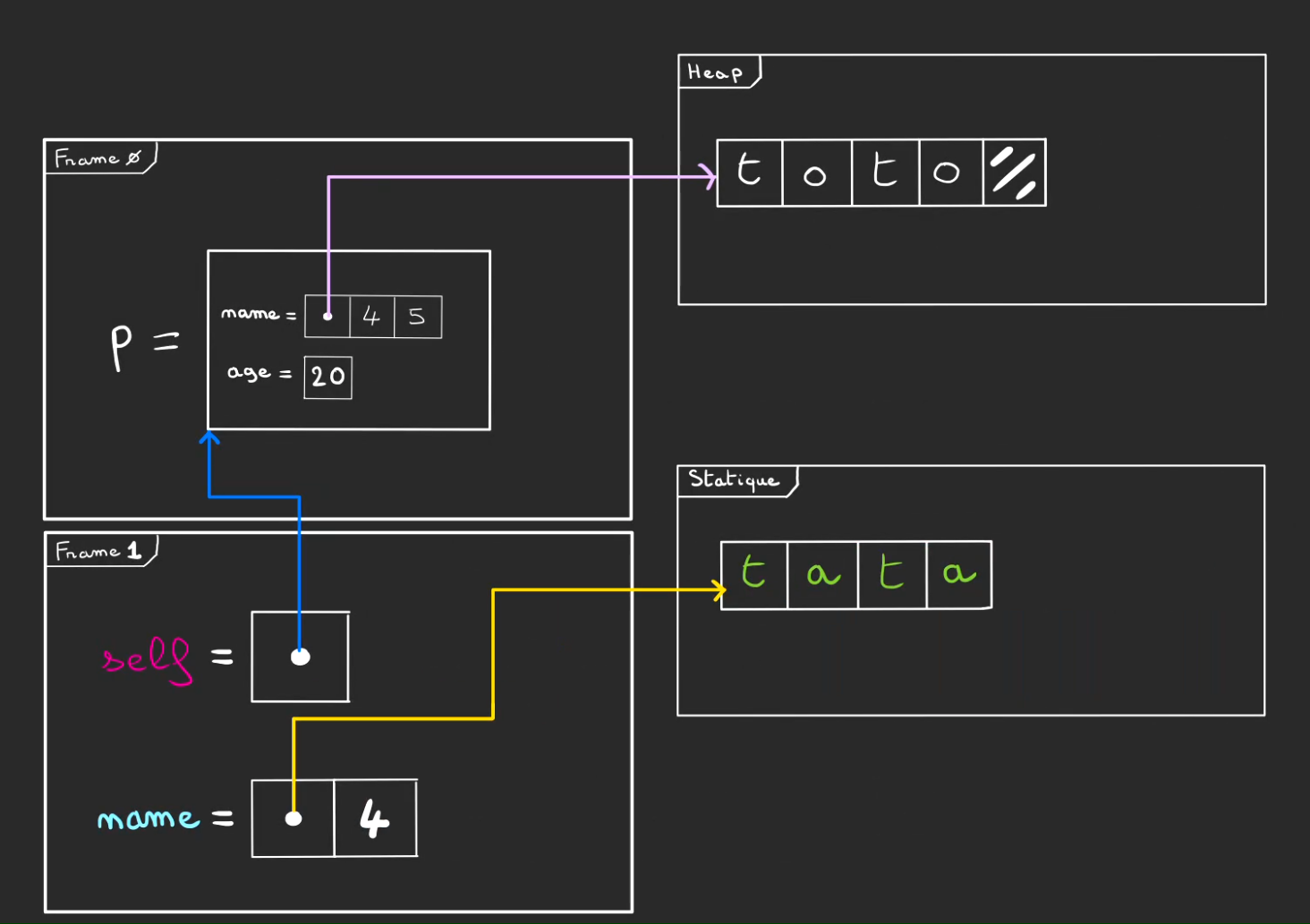
Lors de l'exécution de la fonction with_name, il y a besoin de créer un nouveau Person.
Comme on veut potentiellement modifier la variable name, on va créer un nouveau String pour l'accueillir.

Cela implique d'allouer de la place dans la heap.
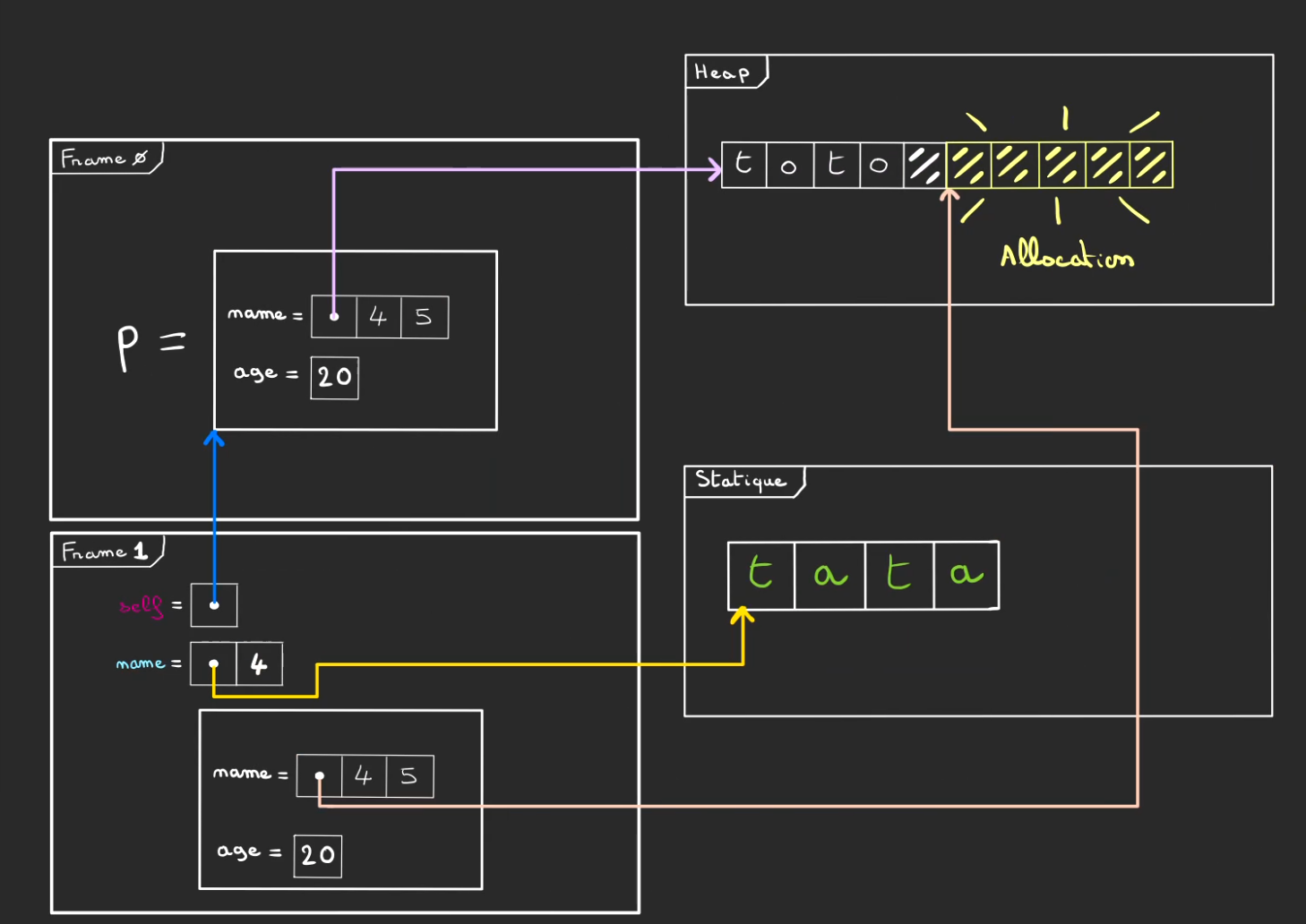
Puis de copier de la mémoire statique vers la zone de la heap allouée.
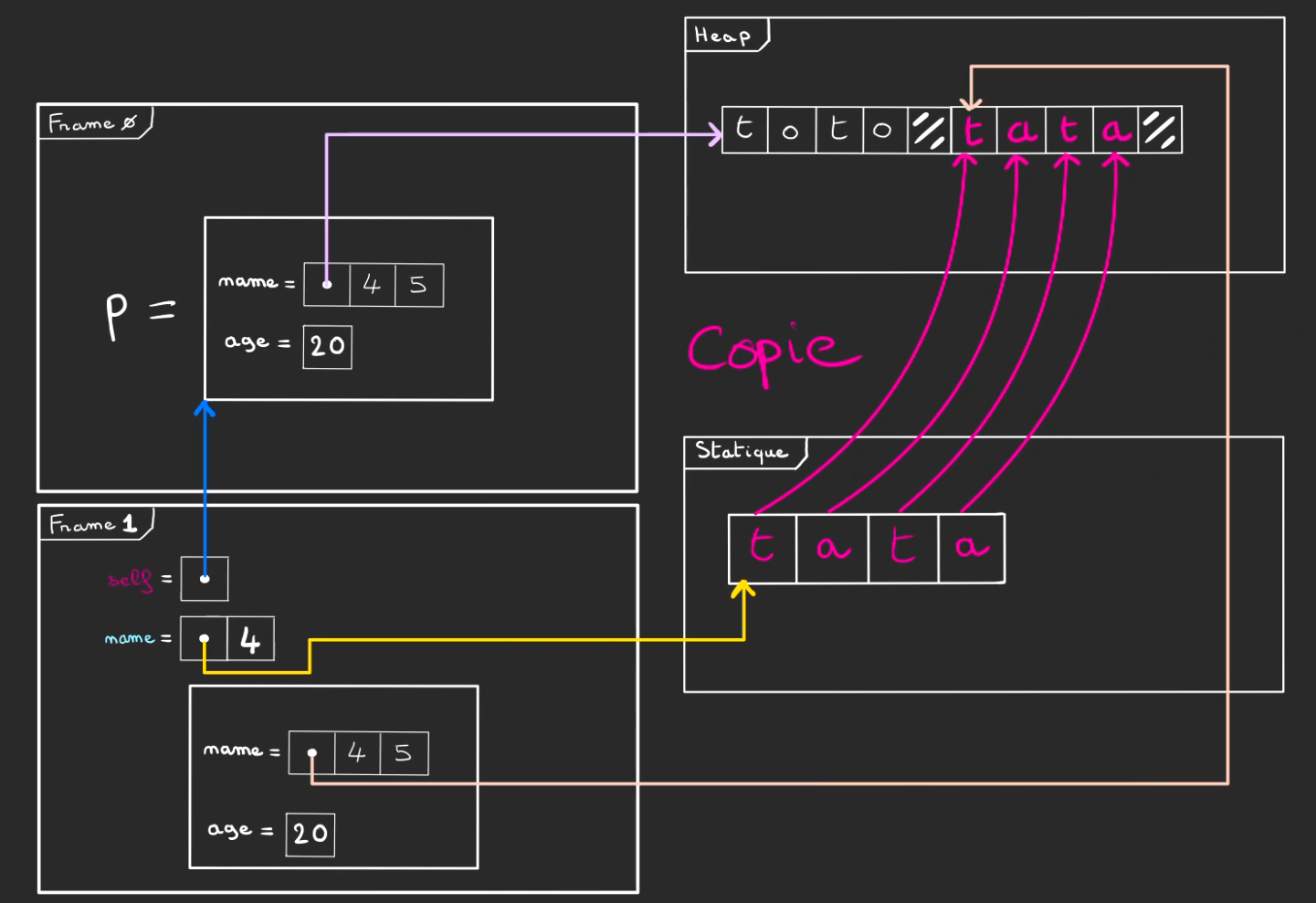
En fin de méthode with_name, on devrait drop le Person créé, mais comme la signature est :
;
Et que p2 est là pour récupérer la Person créée.
On retourne le Person et comme tout va brûler dès que la frame sera pop.

On move dans p2 qui vit dans la frame 0 la Person créée.
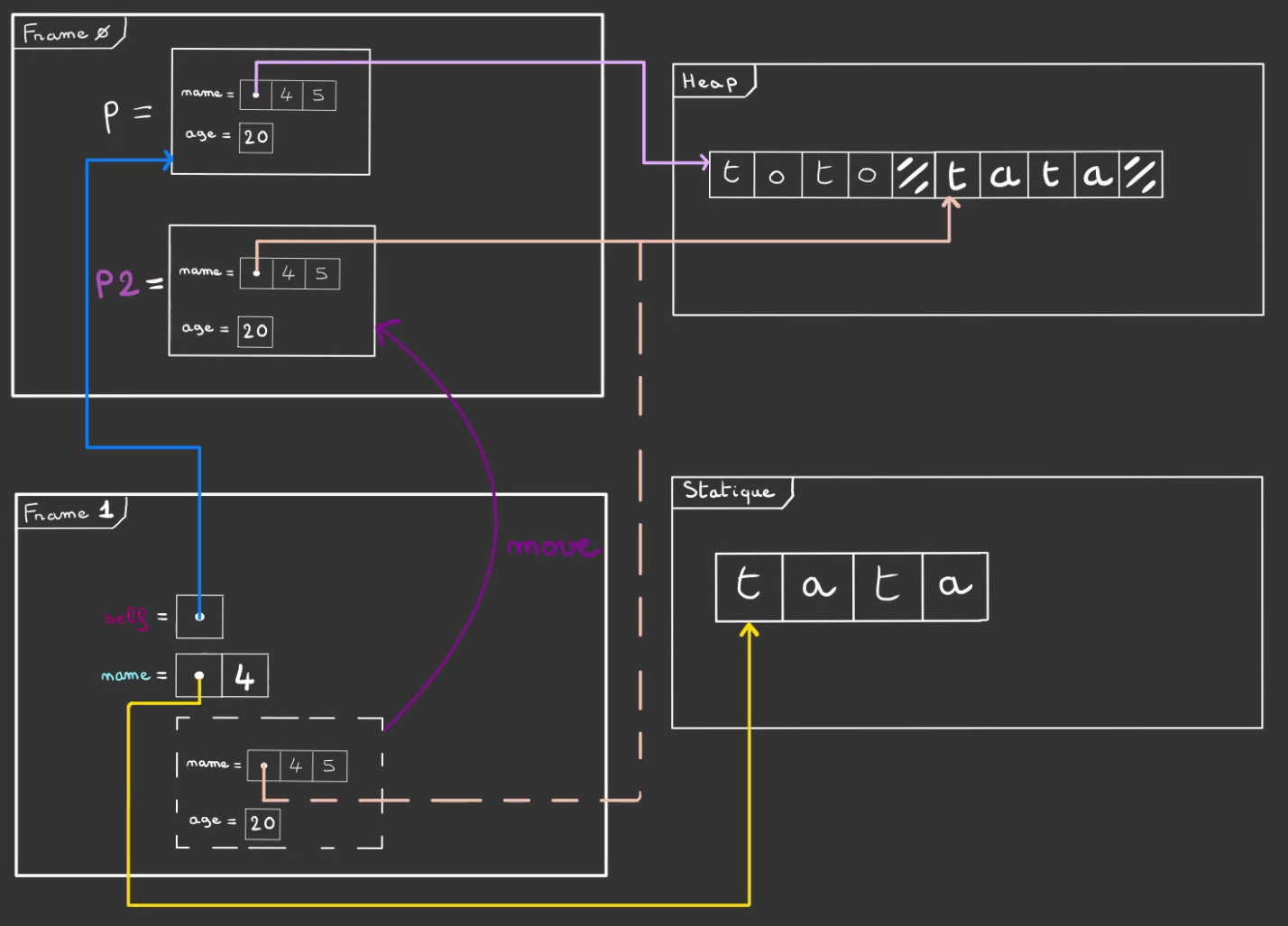
A l'issu du move, on alors la frame 0, qui contient p2. Une personne qui a le même âge que p mais un nom différent. Et donc une zone mémoire dans la heap qui lui est propre.
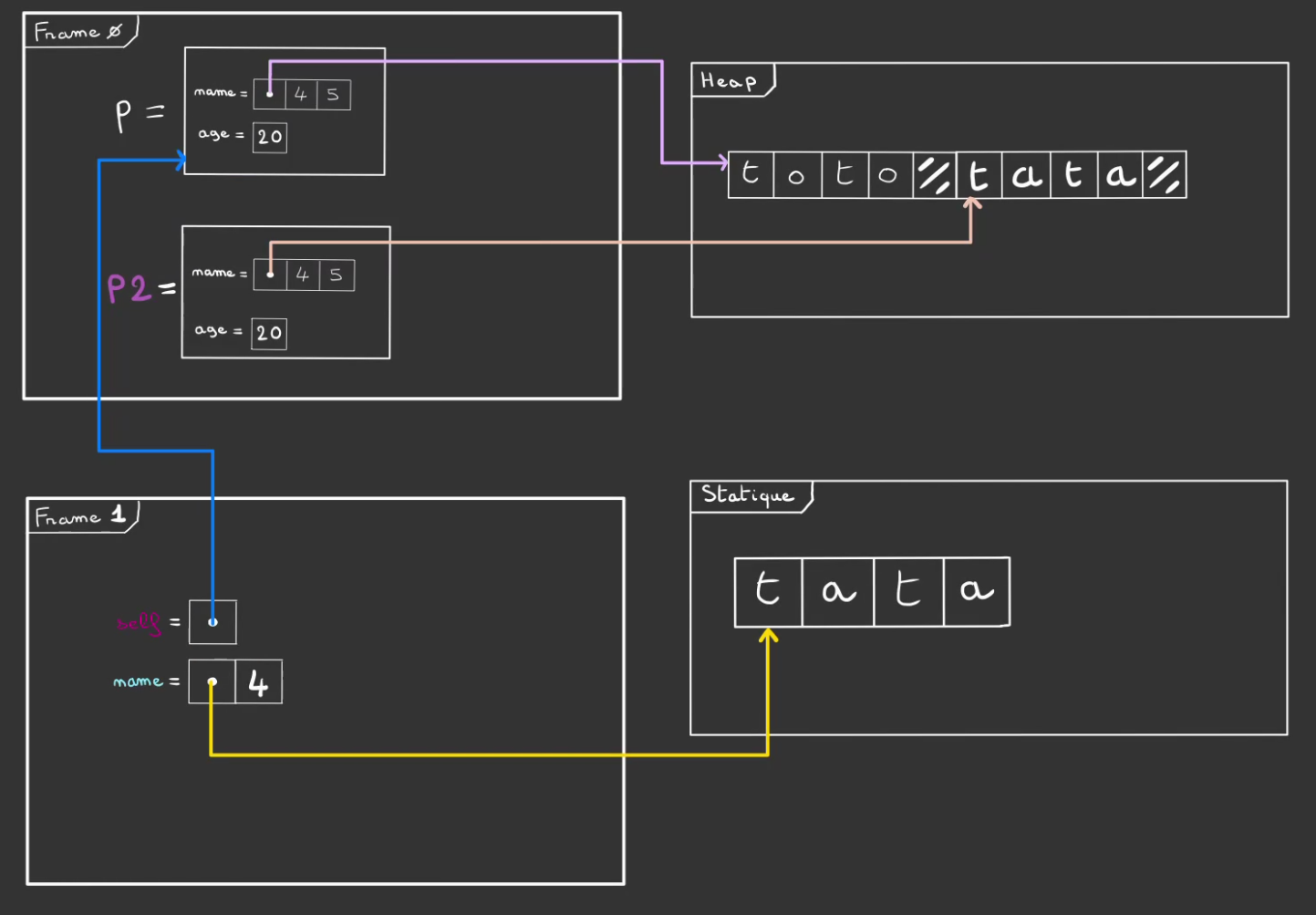
A l'issue de Person::with_name, on pop sa frame 1.

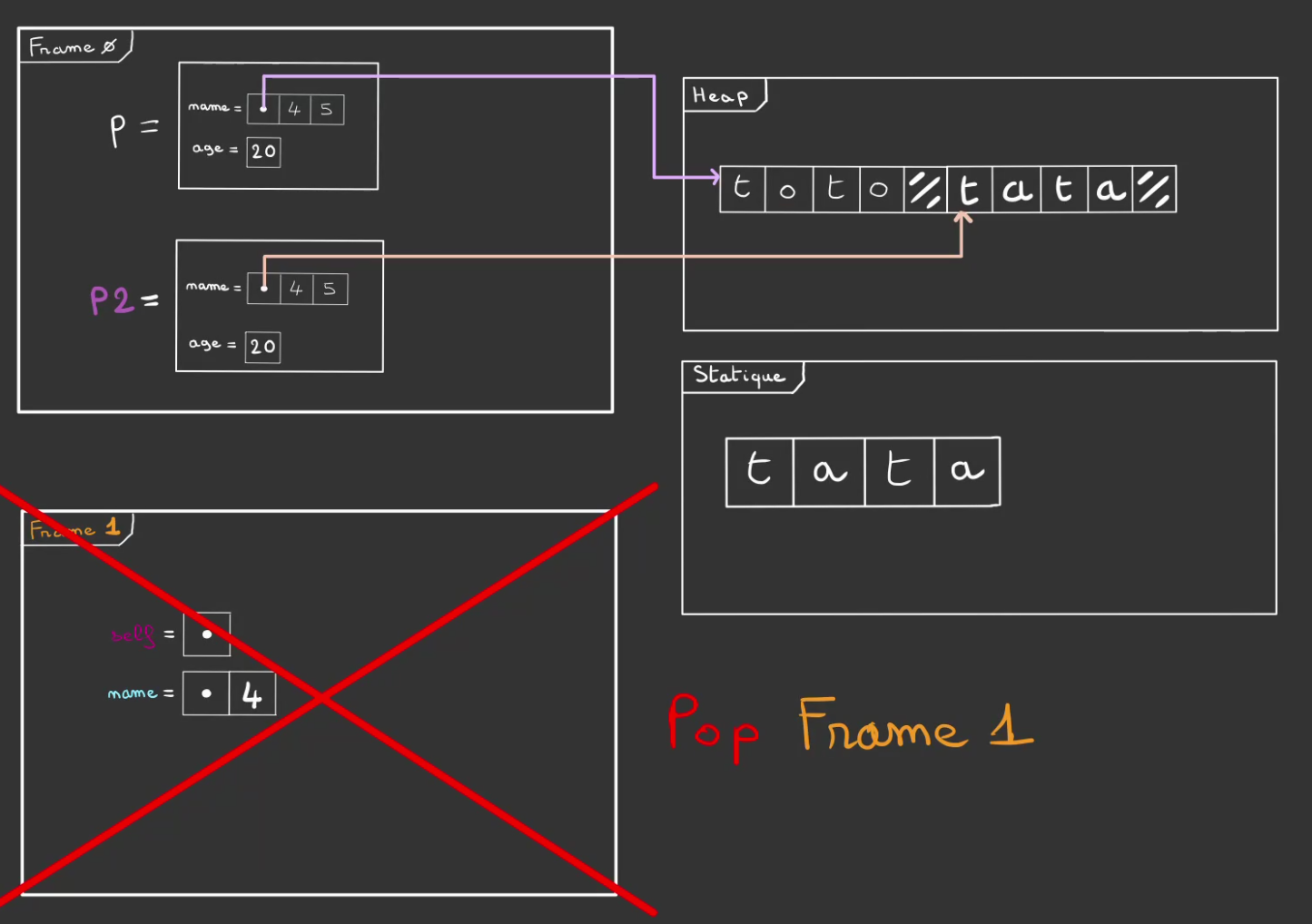
Puis on termine l'exécution du main.

Cela déclenche les drop de p et p2. Et par voie de conséquence la libération des zones mémoire dans la heap qui appartenaient aux deux structures.
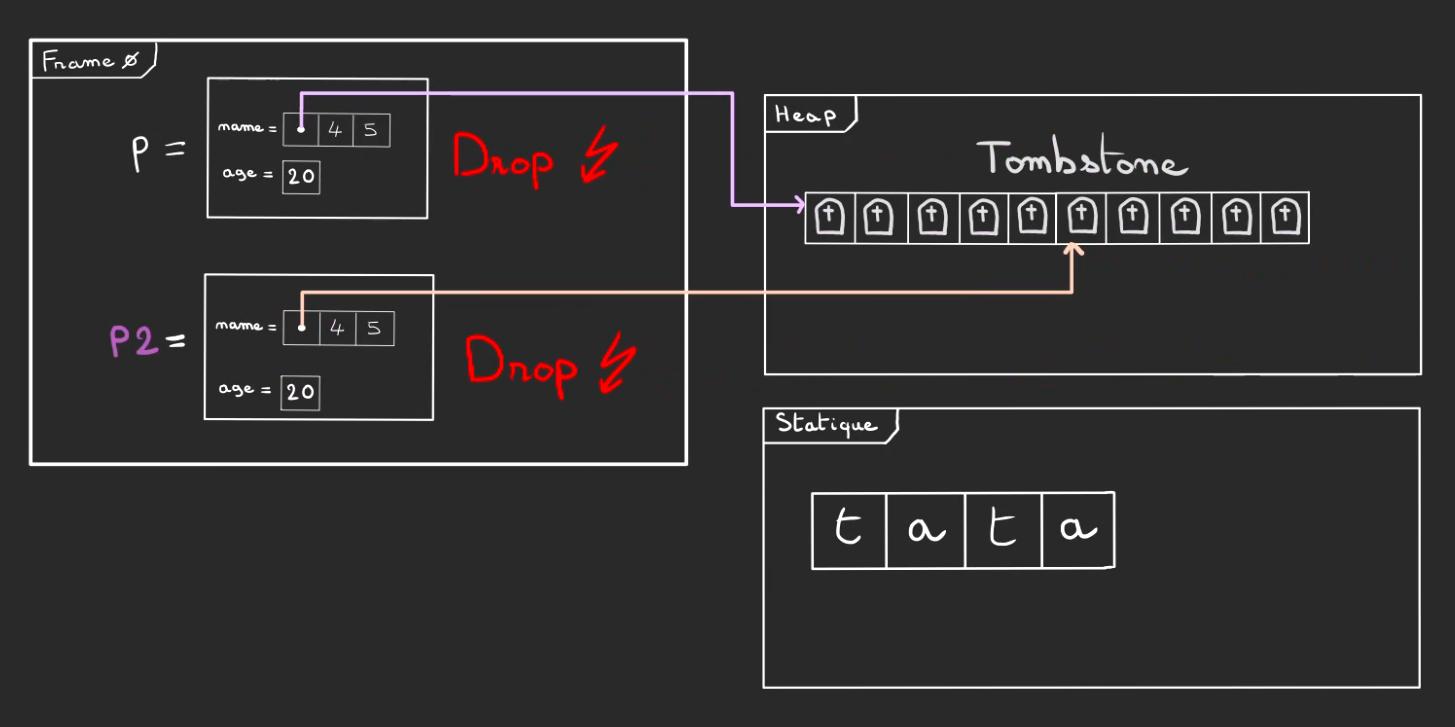
Une fois sortie du main, la frame 0 est pop.

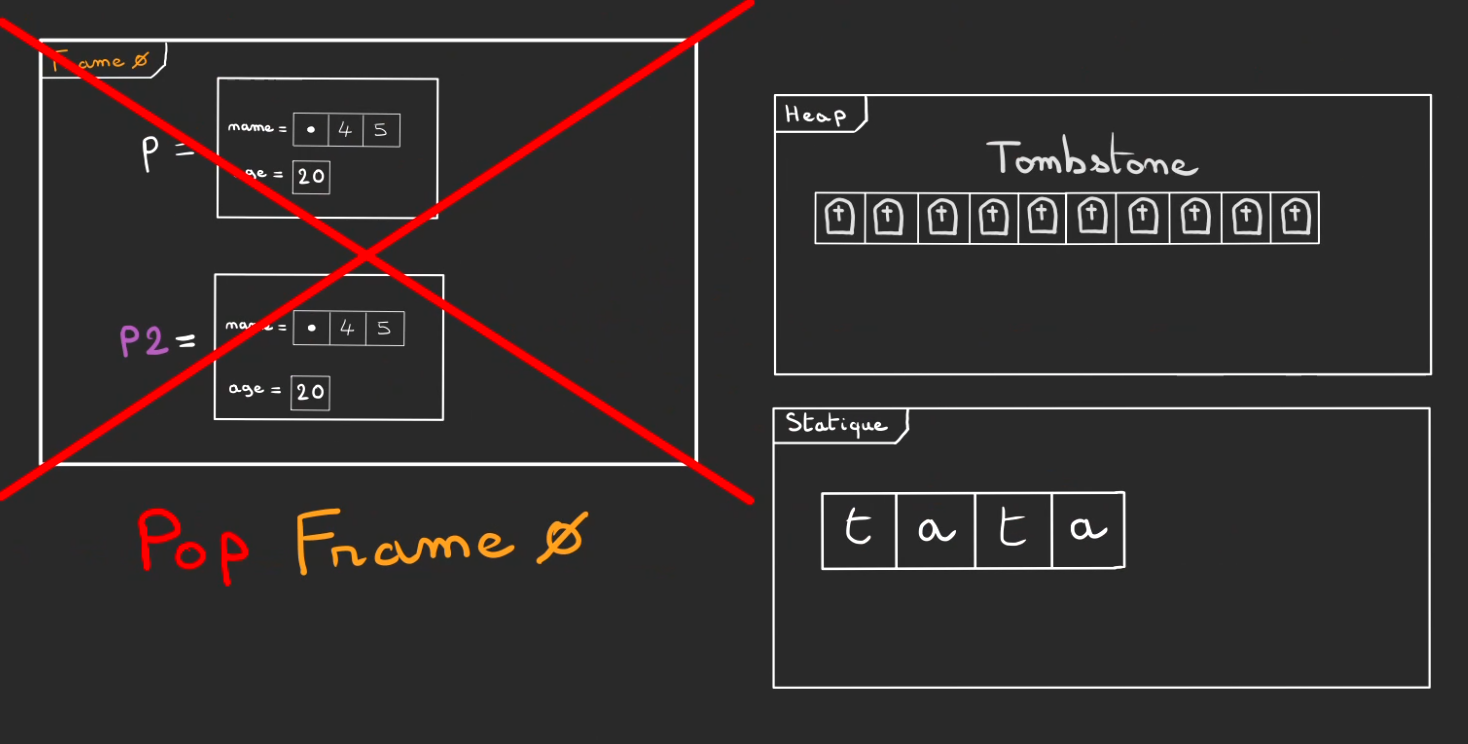
Seul "tata" dans la mémoire statique résiste fièrement, du moins jusqu'à ce que le programme se coupe et que les pages de la mémoire virtuelle ne soit allouée à un autre programme!
Accroissement de la Heap et de la Stack
Un mot sur l'augmentation de taille des segments mémoire.
Tout d'abord la pile, chaque taille de frame est connue à la compilation ce qui fait que chaque contexte à toujours ce qu'il lui faut comme mémoire de travail.
La seule limitation est le StackOverflow qui comme son nom l'indique, dit qu'on a trop empilé, autrement dit on est descendu trop bas, jusqu'à atteindre une limite infranchissable. Le programme est alors instantanément tué ou si le langage le permet on dépile jusqu'à ne plus être dans une situation gênante ! 🙄
Pour le tas, maintenant, le tas n'a pas de taille connue, il croît au besoin et peut même décroître.
Vous vous rappelez quand je disais qu'on pouvait rajouter des pages virtuelles à un programme qui tourne. Et bien c'est maintenant !
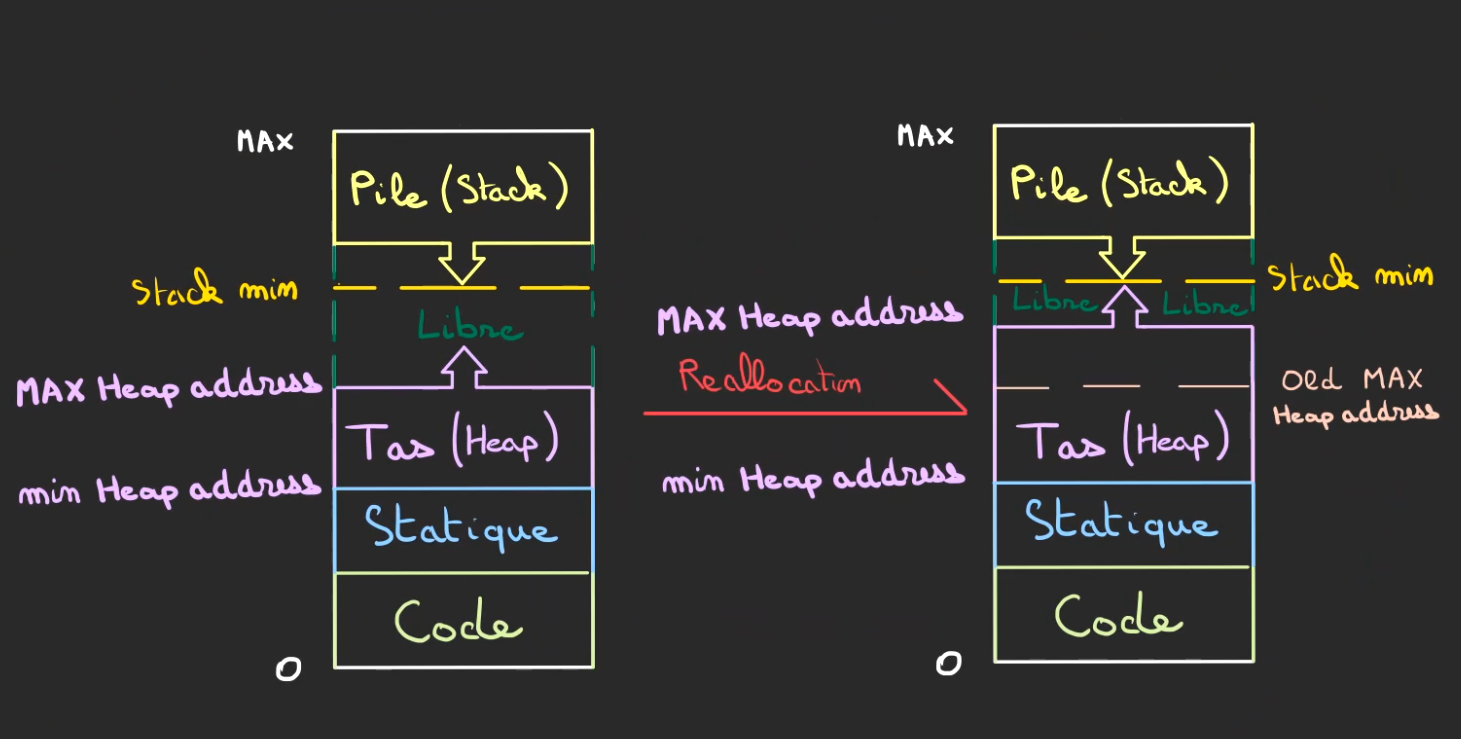
Pour faire grandir le tas, il suffit de modifier l'adresse de fin du tas. Comme tout ce qui a été déjà alloué a une adresse plus faible, aucune réallocation n'est nécessaire, autrement dit l'adresse ne change pas ( et heureusement 😅).
Et du côté de la pile non plus. Pourquoi et bien la première adresse de la pile reste toujours le MAX. Donc là non plus rien ne bouge.
Ce qui bouge c'est l'addresse de fin du tas qui devient plus grande, mais comme ce qui a été rajouté faisait parti de l'espace Libre, nous avons la certitude que rien n'avait besoin d'être bougé !
Enfin, si le tas devient trop grand, plus grand que la mémoire virtuelle qu'on peut lui fournir, le système d'exploitation a son réseau d'assassins, l'OOM Killer qui tue le programme pour sauver le reste du système.
(parfois c'est pas toujours le programme en cause qui est tué 😭).
Cette erreur se nomme un Out of Memory.
C'est ce qui tuait le programme en C de l'article précédent.
Conclusion
Pour travailler un programme à besoin de mémoire de travail et de stockage. Il la récupère du système d'exploitation sous la forme d'une mémoire virtuelle qui est réservée.
Le programme subdivise alors cette mémoire virtuelle en segments qu'il utilise à sa guise.
Les contextes d'appels de fonctions se retrouvent dans la pile qui grandit avec la profondeur d'appels de fonctions.
Tout ce système est entièrement automatisé, y compris la libération de la mémoire à la fin de l'exécution d'une fonction.
Ce qui ne vit pas dans la pile, vit dans le tas. Le tas est beaucoup moins automatisé et nécessite qu'on libère explicitement la mémoire après usage.
Heureusement en Rust, nous avons le borrow checker qui est capable de déclencher lorsque c'est nécessaire les libérations de la mémoire dans le tas.
Ce travail est sous licence CC BY-NC-SA 4.0.