Les raisons d'être de Rust
Faire du Rust, oui, mais pourquoi ?
C'est ce que nous allons essayer de montrer dans cette partie.
Posons-nous d'abord une simple question.
Quelles sont les caractéristiques de Rust ?
Rust est un langage de programmation compilé fortement typé sans garbage collector et qui a pour objectif de rendre la programmation asynchrone et parrallèle la plus safe possible.
Ok, la réponse est pas aussi simple que la question. 😅
Je propose que l'on réalise un tour d'horizon des connaissances nécessaires à la compréhension pleine et entière de la réponse.
Exécuter du code
Un ordinateur devrait s'appeler un calculateur, il ne sait que prendre des nombres et réaliser des opérations dessus.
Pour cela il utilise ce que l'on appelle un CPU Central Processing Unit littéralement "Unité centrale de calculs".
Pour savoir ce qu'il a à faire, il utilise ce que l'on appelle du code machine. Et ceci est l'unique langage qu'il comprend.
Il n'est pas possible de lui donner du python ou du javascript.
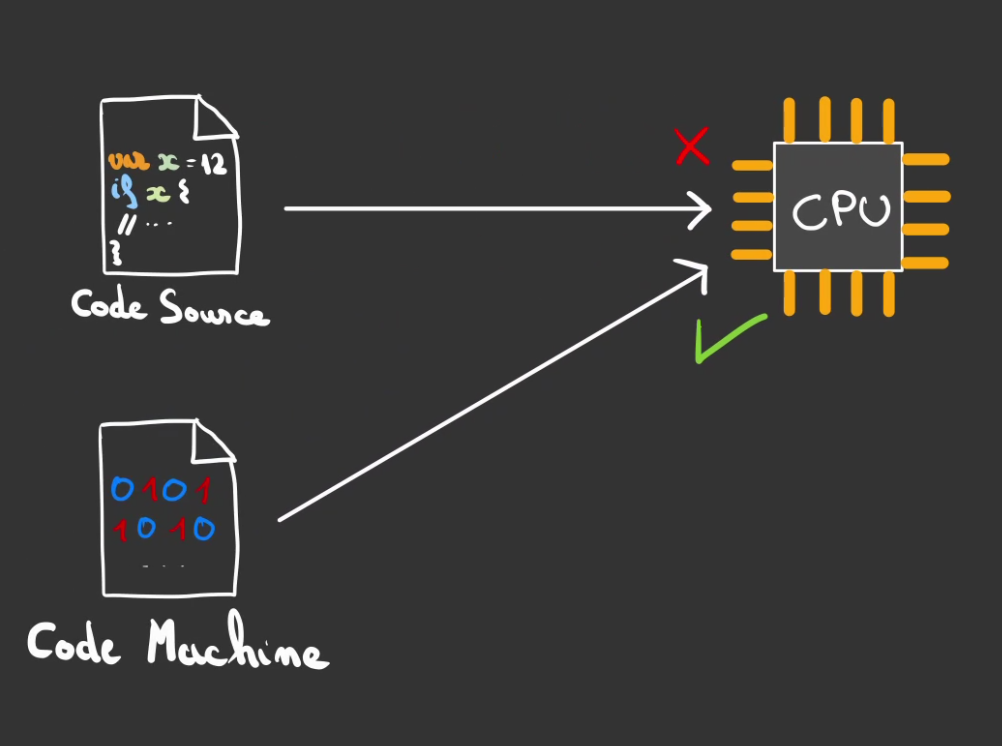
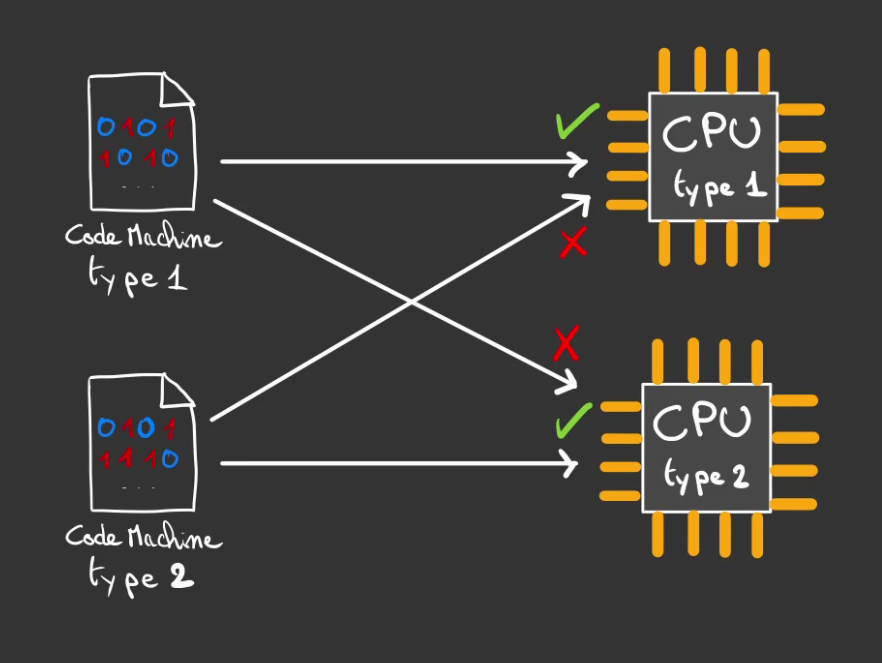
La subtilité c'est qu'il existe autant de codes machines qu'il y a de types de CPUs.
Et seul le bon type de code machine peut être compris par le bon CPU.
Il faut donc un chaînon manquant qui réalise la liaison entre le code source dont on a l'habitude et le code machine adapté à la plateforme.
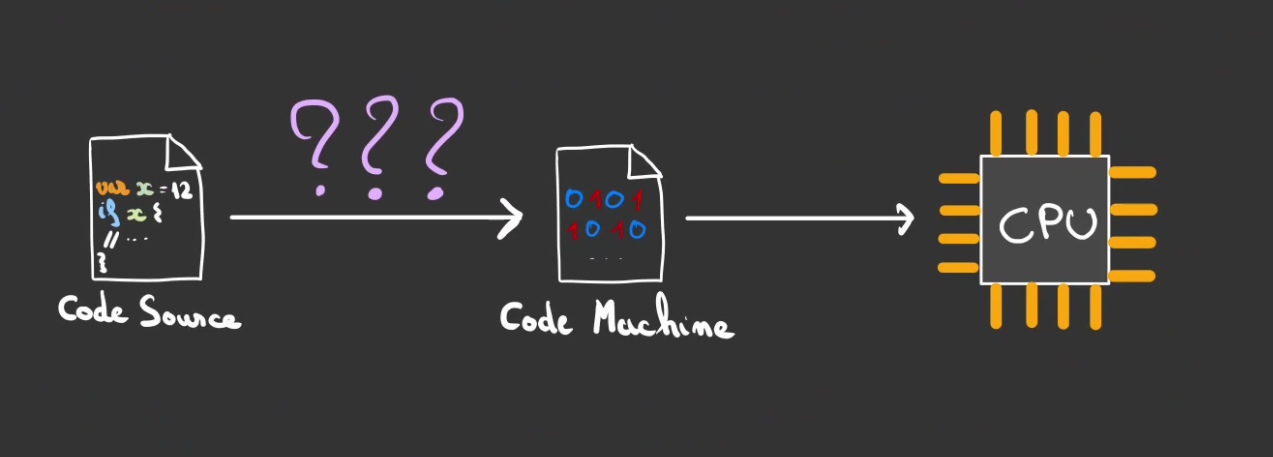
L'histoire de la programmation a été longue et a mené à diverses solutions techniques.
Nous allons voir ce qui existe.
Compilation ou interprétation
En programmation, il existe deux grandes familles principales de langages, les langages compilés et les langages interprétés.
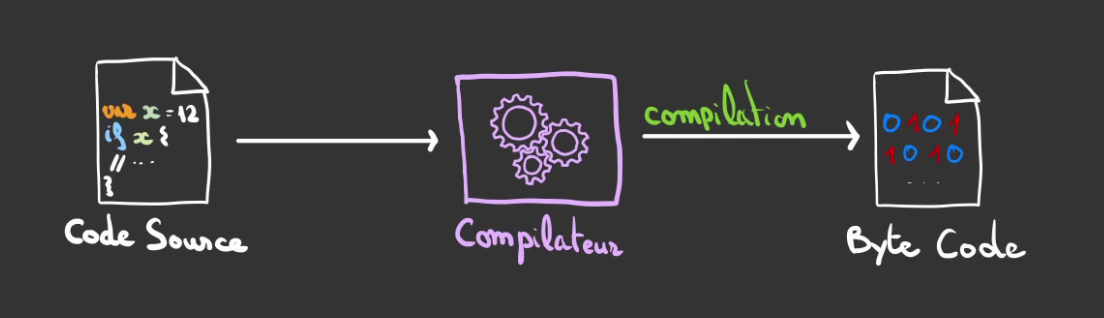
Compilation
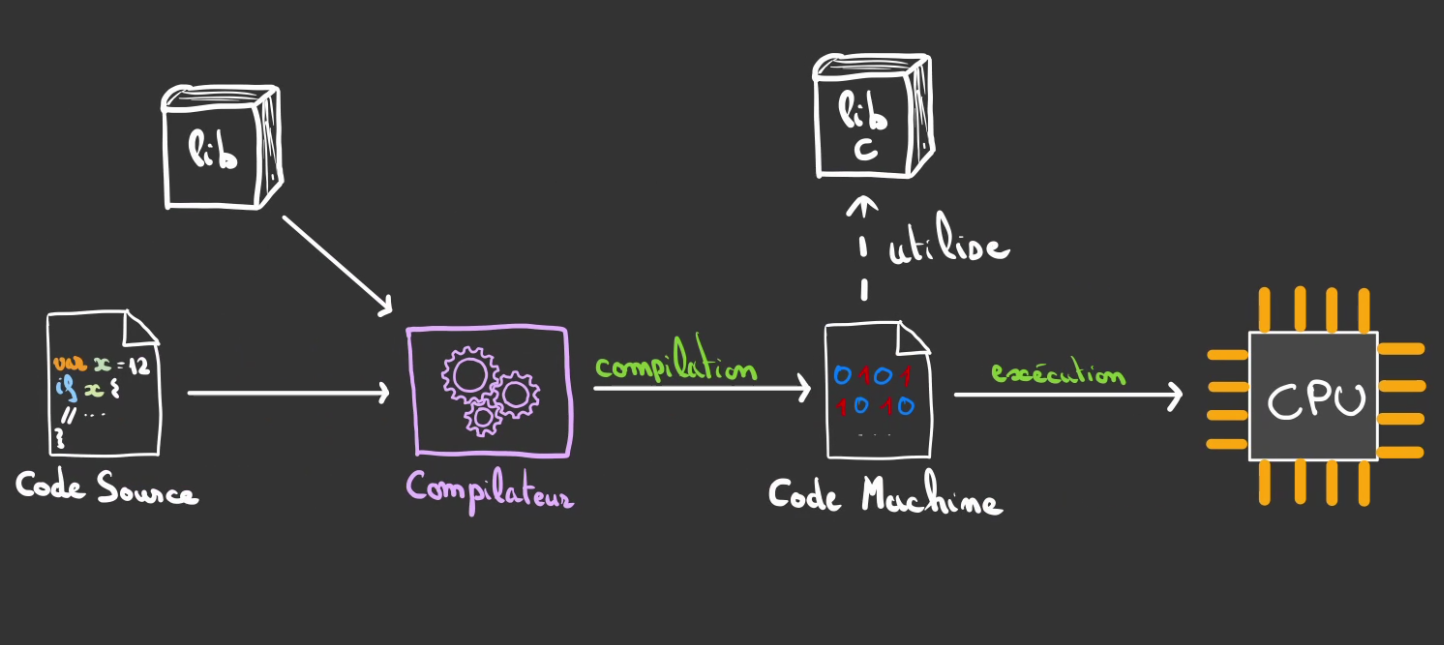
La compilation est une opération qui consiste à transformer du code source en du code machine.
On utilise pour cela un programme appelé un compilateur qui va lire le code source et le traduire en instructions compréhensibles pour le CPU.
Cette opération est réalisée une fois et échoue si le code est mal écrit.
Si tout est correct, un exécutable ou une bibliothèque est produite.
Le code peut alors être exécuté par le CPU sans autre outil nécessaire.
La plupart des programmes ont tout de même besoin de bibliothèques installées sur le systèmes d'exploitation. La lib C par exemple.
Interprétation
Les langages interprétés les plus connus sont le PHP, le Javascript et le Python, pour ne citer qu'eux.
Le principe est de lancer un programme appelé un interpréteur qui va lire le code source et transformer celui-ci en des instructions compréhensibles par le CPU de l'ordinateur.
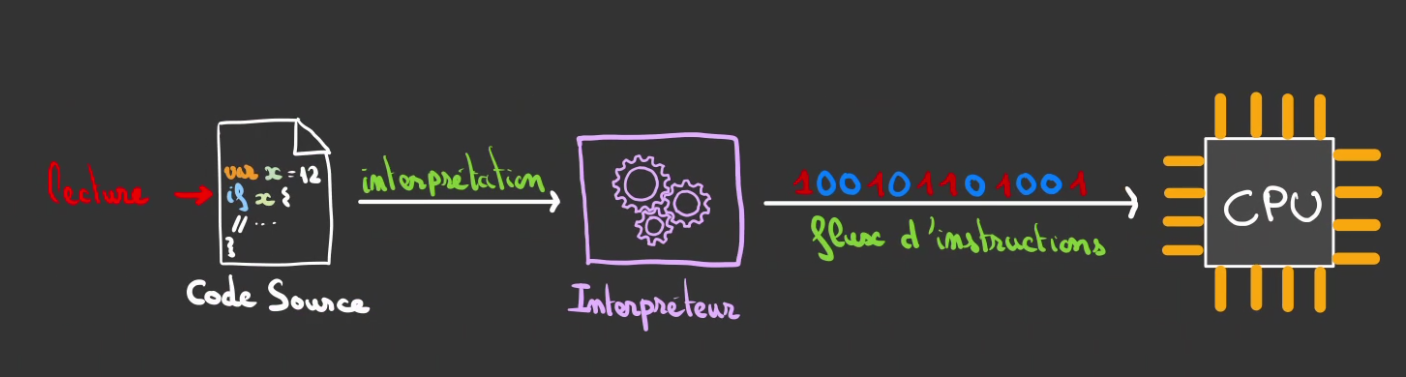
Ce qui signifie qu'il faut à la fois le code source et le bon interpréteur pour pouvoir éxécuter le programme.
Attention
Votre interpréteur doit être capable de discuter dans le langage machine du CPU.
A la différence d'un programme compilé, un programme interprété l'est à chaque éxécution. Cela siginifie plusieurs choses:
- on coupe la phase de compilation mais en contre partie le code doit être traduit à chaque éxécution du programme
- c'est globalement lent, l'interpréteur découvre le code ligne par ligne, doit comprendre et réagir en conséquence, ça prend du temps
- si le code est mal écrit, le programme plantera à l'éxécution -> en prod
VM
Il existe également une catégorie de langages comme le Java qui sont un peu entre les deux.
Le code est compilé mais non pas vers du code machine mais vers du byte code. C'est une sorte de langage machine mais adapté pour un CPU virtuel.
Puis l'on fait tourner un programme qui se nomme une machine virtuelle ou VM qui se charge d'exécuter le byte code. Contrairement à l'interprétateur qui prend des décisions au fur et à mesure de la lecture. La machine virtuelle se comporte comme un CPU virtuel et donc ne fait globalement qu'exécuter ce qui lui ai donné. Ce qui rend l'interprétation bien plus efficace.
La VM transforme alors le byte code en un flux instructions compréhensible par le CPU, lui bien réel.
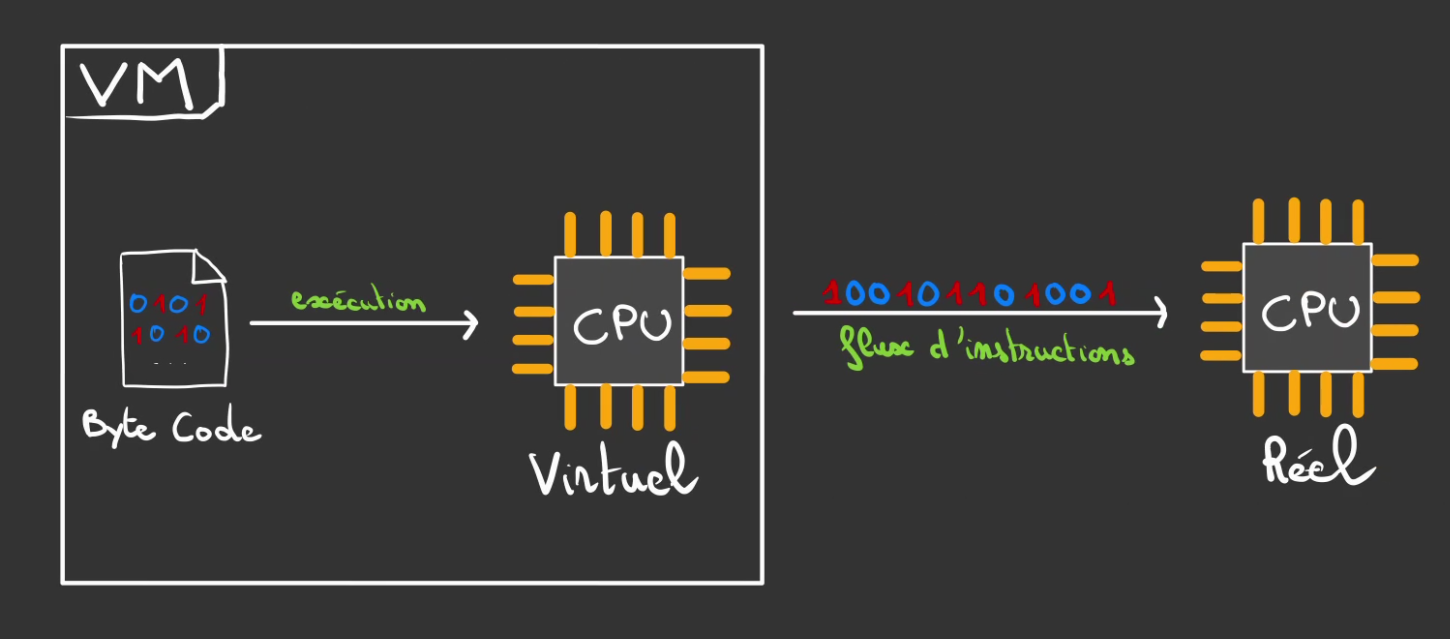
L'idée derrière ce compromis est de bénéficier à la fois des avantages de la compilation qui permet de détecter très tôt les erreurs du développeur ou de la développeuse. Et en même temps d'avoir une portabilité: du byte code est valide pour toute plateforme et donc pour tout CPU.
C'était le slogan de Java
Write once. Run anywhere.
Ecrire une fois, exécuter partout.
Le choix de Rust
Rust a choisi la compilation pour déceler le plus tôt possible les erreurs et être au plus près de la machine pour des raisons de performances. Cela induit un temps de compilation et de recompilation pour le développeur mais s'assure que le code exécuté est valide syntaxiquement.
La VM a également été écarté car elle induit son installation avant de pouvoir exécuter du code.
Typage
Le typage est la faculté à donner un sens à des données. Un ordinateur ne comprend que des 0 et des 1. C'est le développeur qui leur donne un sens au moyen d'un langage de programmation.
Le même nombre 42 peut à la fois être l'entier 42, le charactère * ou le décimal 42.0.
Tout dépend de ce que l'on souhaite en faire.
Il est même possible que ce 42 corresponde à la valeur de la composante rouge d'un pixel, alors il porte en plus d'une valeur, une sémantique.
moi r un entier positif correpond à la composante rouge d'un pixel.
Il existe deux manières de réaliser cela.
Typage dynamique
C'est de là que viennent toutes les bizarreries du Javascript.
3 - "1" // renvoit 2 le nombre
Ici par exemple on soustrait un nombre, une quantité numérique avec une chaîne de caractère.
Le choix a été fait de le transformer en nombre avant d'effectuer la soustraction. Mais cette décision est totalement arbitraire.
On aurait pu tout a fait décider que c'était le code ASCII de 1 qui vaut 49.
Ce qui signifie que toutes ces manipulations de types différents sont totalement liés aux connaissances du langages et de sa capacité à ne pas faire les "mauvais choix".
Si l'on revient à notre exemple de pixel, nous allons contruire un tableau de clefs et valeurs, plus communément appelé Map.
Les champs n'étant pas typés, nous pouvons très bien avoir les mêmes noms de champs mais avec des types différents.
Ce qui fait que lorsque l'on créé un tableau
Et que l'on désire appliquer une transformation comme faire la moyenne des composantes d'un pixel
a.r + a.v + a.b / 3
On se retrouve avec ce résultat ci:
[38, NaN]
Les champs existants, le processus c'est bien déroulé, mais le typage non.
Le premier résultat est bon, le second non, on a additionné des entiers, des booléens et des chaines de caractères sans se préoccuper de ce qui se passe.
Et ça pourrait très bien arrivé si par exemple les données proviennent de la lecture d'un JSON par exemple.
Le développeur ou la développeuse doit faire extrêmement attention à toutes les opérations qu'il réalise explicitement ou implicitement.
Typage statique
La deuxième manière d'appréhender le sujet est de dire que l'on sait à tout moment ce que l'on manipule et par conséquent nous sommes capables d'attribuer un scope de comportement voulus ou non.
De fait les bizarreries d'additions de types différents ne devrait pas être possible implicitement.
Pour aider le compilateur ou l'interpréteur à savoir de quoi l'on parle, nous allons typer tout ce qui existe et ainsi restreindre les axes de libertés du développeur et surtout lui éviter des chutes dans le ravin! 😅
Ainsi notre pixel n'est plus une Map mais une structure.
;
Pour créer un Pixel:
struct Pixel pixel = ;
Cela ressemble fortement à notre Map, mais il y a une différence
Il n'est pas possible de générer not_a_pixel!
On veut créer un Pixel, mais on ne donne pas les ingrédients pour!
struct Pixel not_a_pixel = ;
Le compilateur ou l'interpréteur dira qu'il attend un entier comme composante r qu'il a reçu un string.
De même, si l'on réalise
;
;
struct Pixel pixel = ;
struct NotAPixel not_a_pixel = ;
Les deux initialisations se passeront bien.
Par contre, si l'on tente de créer notre tableau
Pixel tab = ;
Le système dira qu'il n'est pas possible de créer un tableau avec du Pixel et du NotAPixel. Nous assurant que les types manipulés sont toujours les bons.
Le typage fort ou statique impose également une règle, le type d'une variable ne peut pas varier implicitement.
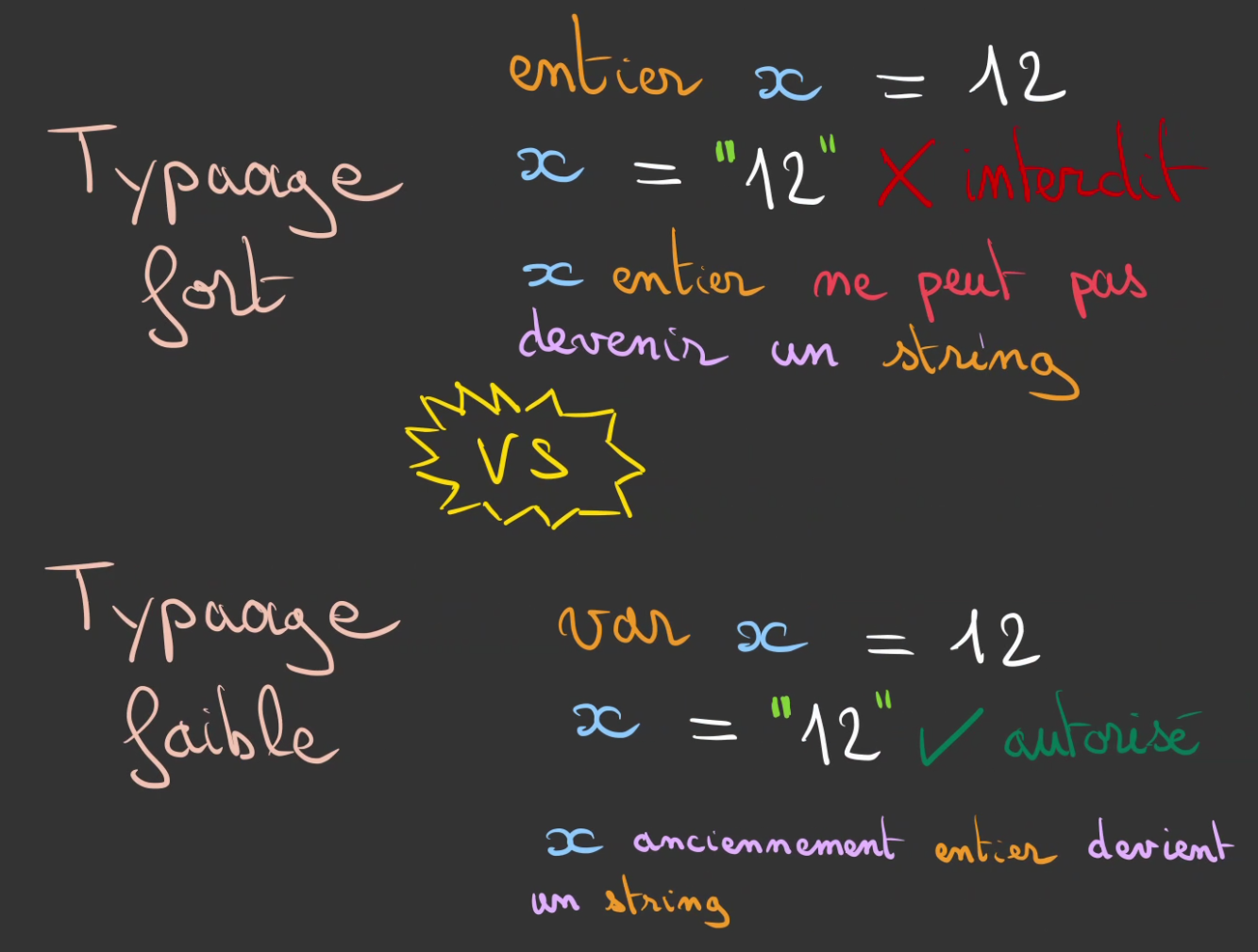
Si le langage est compilé alors toutes ces vérifications sont faites avant que le programme ne puisse s'exécuter.
Le choix de Rust
Rust a choisi un typage fort pour éviter toutes manipulations implicites malencontreuses. Le fait également que le langage soit compilé aurait induit une trop grande complexité pour réaliser un typage faible.
Gestion de la mémoire
La plupart des codes qui exécutent des opérations un tant soit peu complexes, ont besoin de venir stocker dynamiquement de la donnée en mémoire. Si rien n'est fait, elle s'accumule jusqu'au crash de l'application.
Il existe deux manières principales de gérer le problème.
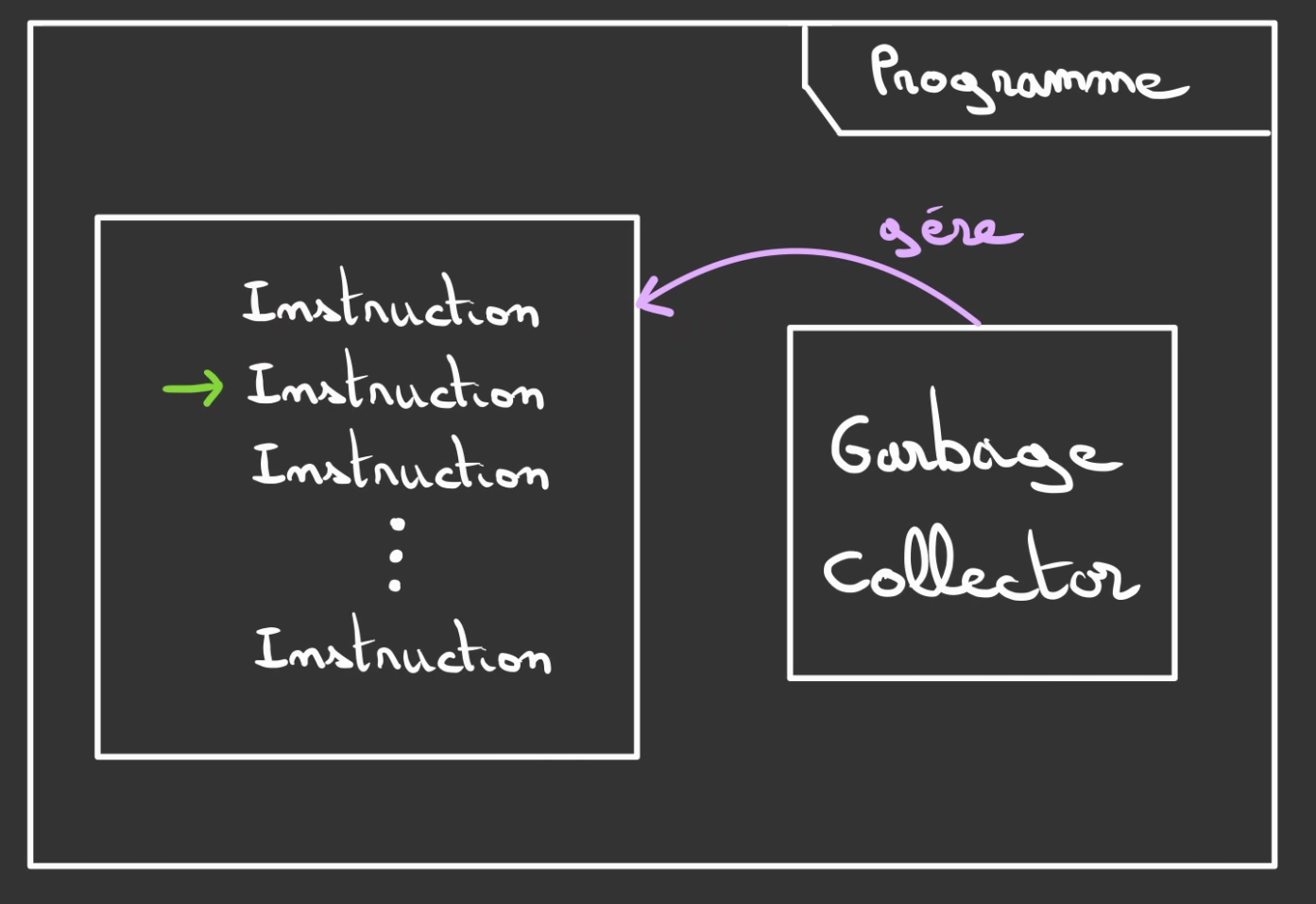
Garbage collector
La première et la moins contraignante pour le développeur est de laisser le programme se débrouiller seul.
Seul pas vraiment.
L'idée est de faire tourner à côté du programme utilisateur un autre programme qui a pour but de gérer la mémoire de l'autre programme. Ce second programme se nomme un Garbage Collector ou ramasse-miette.
Son principe de fonctionnement est à intervalles réguliers de stopper purement et simplement le déroulé du programme.
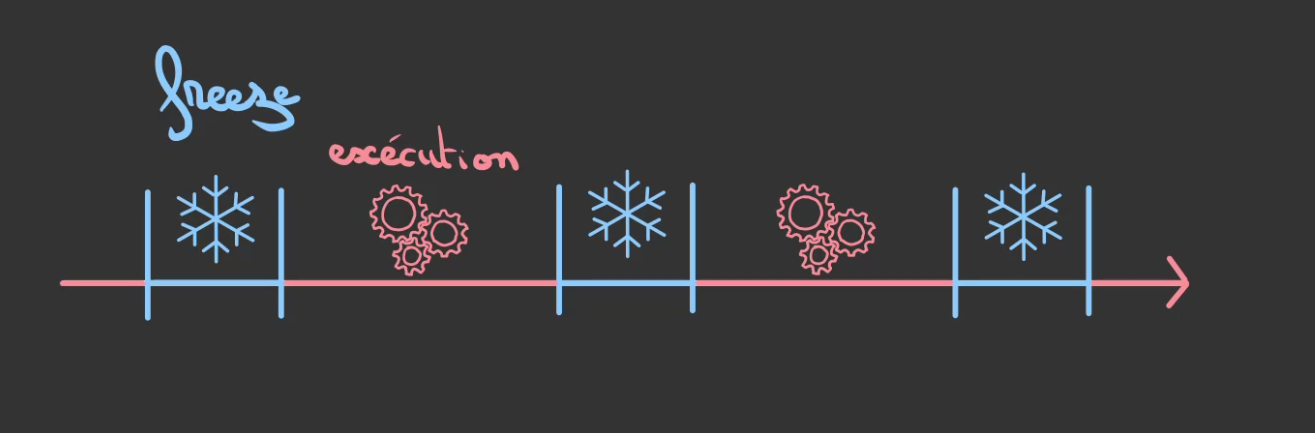
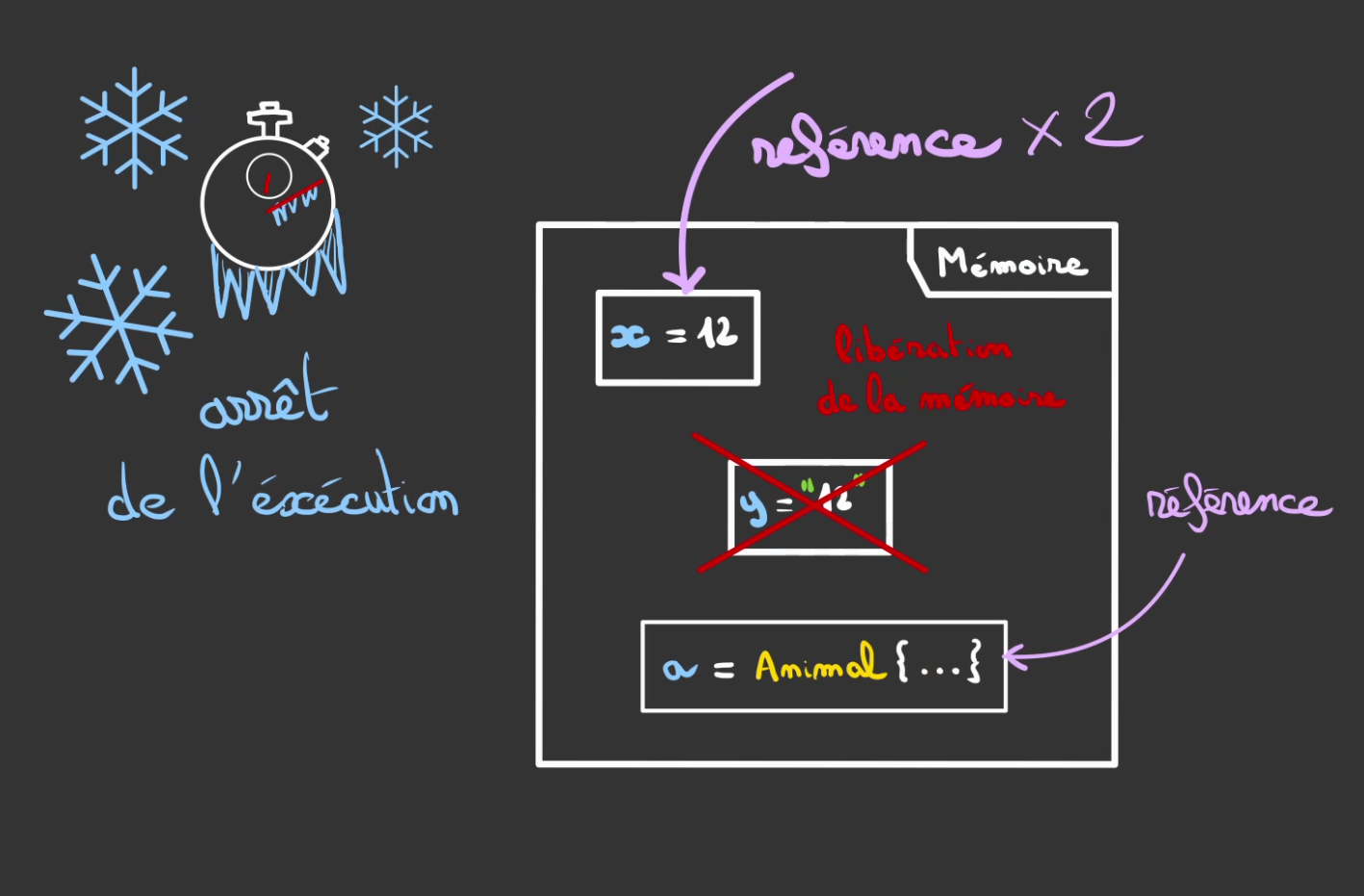
Une fois le programme stoppé, le garbage collector liste toutes les variables du programme et compte le nombre de fois que la variable est référencée à l'instant de l'arrêt de l'exécution.
S'il existe au moins une référence à la variable, elle est gardé. Sinon, la mémoire occupée par la variable est libérée.
Il est à noter que la durée de période de stop est dépendante du temps d'exécution du garbage collector.
Plus il y a de variables à vérifier, plus le programme fait des choses compliquées, plus le garbage collector mettra du temps à réaliser sa passe de vérification.
Et donc stoppera longuement le programme principal.
Libération explicite
La façon la plus "casse-gueule" de faire les choses. Si le code est mal fait il aura des fuites de mémoire on dira qu'il "leak".
Toute la bonne utilisation et libération de la mémoire repose sur les compétences du développeur et ainsi sur sa connaissance du flux d'exécution.
L'avantage est qu'il n'est plus nécessaire d'avoir un Garbage Collector. Et donc plus de freeze du programme.
Les intructions de libérations sont directement inscrites dans le code et exécuter comme le serait une addition.
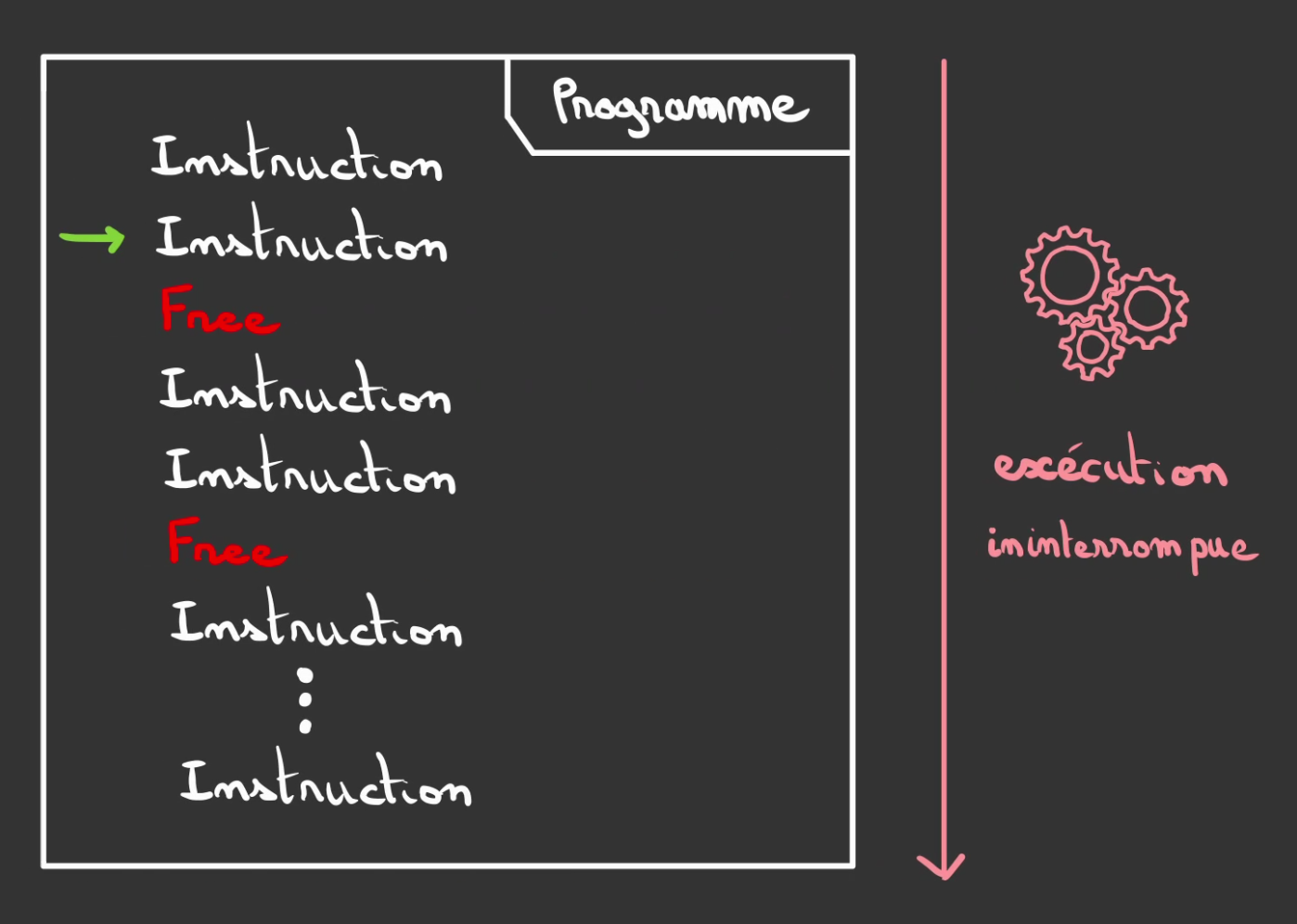
Par contre cela impose une grande rigueur pour au choix:
- oublier de libérer la mémoire
- la libérer deux fois
- libérer le mauvais emplacement
- libérer quelque chose encore utilisé
Bref moult soucis et l'étape suivante qui consistera à faire des choses en parallèle ne va pas arranger les choses. Et rendre presque impossible cette manière de faire.
Il existe des outils qui a posteriori de la rédaction du code nous montre les erreurs.
Mais est ce que ce ne serait pas plus simple que lors de la compilation une analyse statique détermine pour nous ce qui doit ou pas être libéré et surtout quand cela doit être fait ?.
La valeur ajoutée de Rust
Rust est un langage qui se veut le plus performant possible.
Dans certains contextes, le temps passé par le Garbage collector n'est pas acceptable.
Ainsi, Rust utilise de la libération explicite de la mémoire. Mais pour toutes les raisons énoncées ci-dessus, il n'est pas possible de se fier à la capacité du développeur à manipuler proprement la mémoire.
C'est ainsi que l'on rajoute une autre pièce dans la machine.
J'ai nommé l'analyse statique !
L'idée est de parcourir à "froid" le code et de deviner son comportement à l'exécution pour déterminer à quel moment tel emplacement mémoire deviendra inutile.
Les différentes règles qui régissent cela sont décrites plus en détails dans ce chapitre.
Ainsi Rust, même sans Garbage Collector, ne fait pas reposer la responsabilité de la libération de la mémoire sur les frêles épaules du développeur. 😁
Au lieu de ça lui donne un cadre solide qui devient essentiel, lorsque le code perd sa séquentialité.
Programmation parallèle
Imaginez vous avez un tapis roulant où défilent des tâches à effectuer, ces tâches ont chacune une durée estimée, certaines rapides se font en 1min, d'autres en 2 min et d'autres encore en 3 min.
Si vous n'avez qu'un seul ouvrier sur la chaîne, il ne pourra travailler que sur une tâche à la fois.
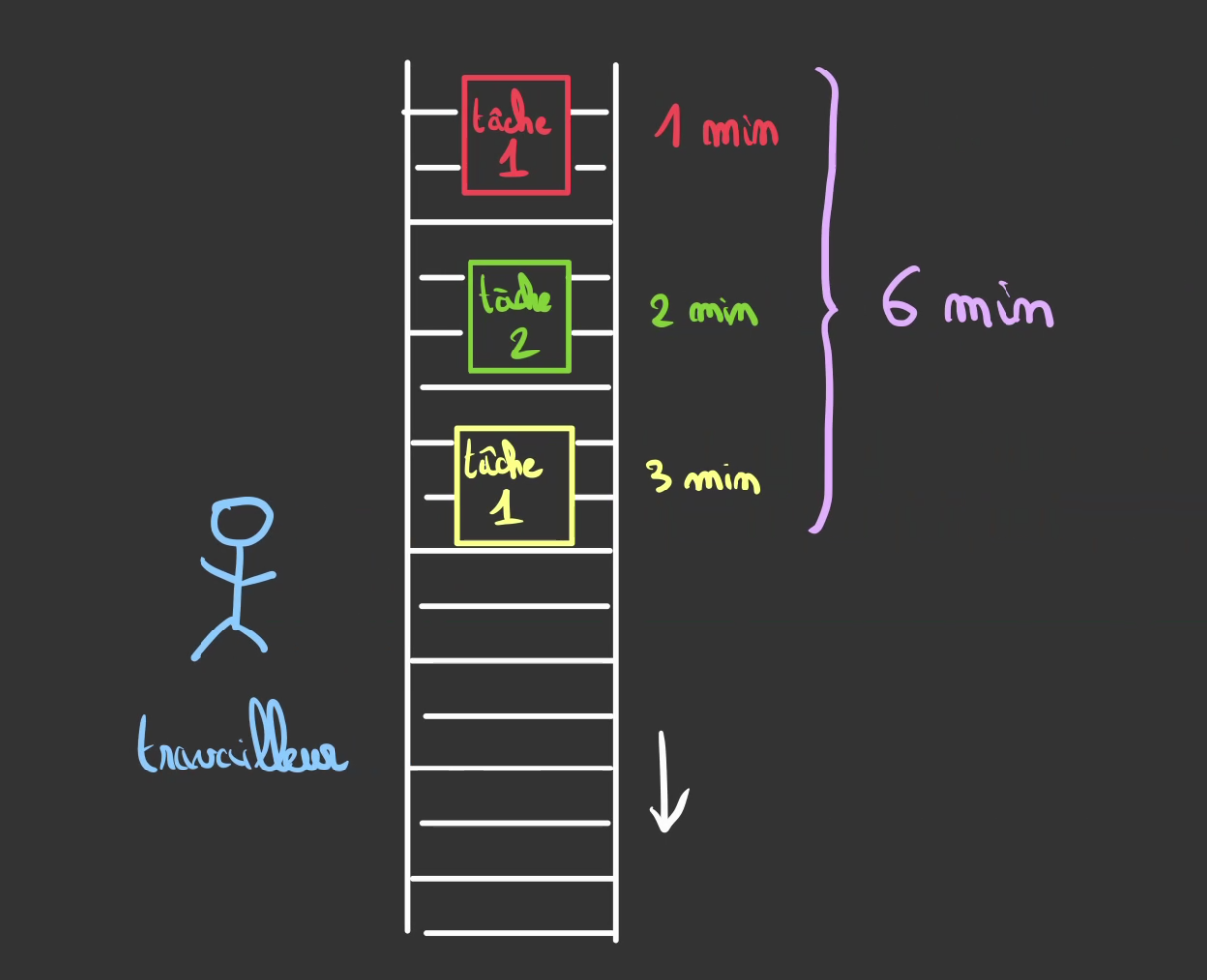
Ainsi, le temps passé à effectuer les tâches sera la somme des temps de chaque tâche. Ici 6 min.
On voit bien que dans le laps de temps pour réaliser la tâche de 3 min, nous avons le temps de faire les tâches de 2 min et 1 min.
Comme d'habitude, "diviser pour mieux régner".
On dispatche le travail en deux tapis. A partir du moment où l'ouvrier ne fait rien on lui envoie une nouvelle tâche.
Ainsi, pendant que l'ouvrier 1 s'occupe de la tâche 1 de 3 min. L'ouvrier 2 à déjà terminé la tâche 2 de 2 min et va s'attaquer la tâche 3.
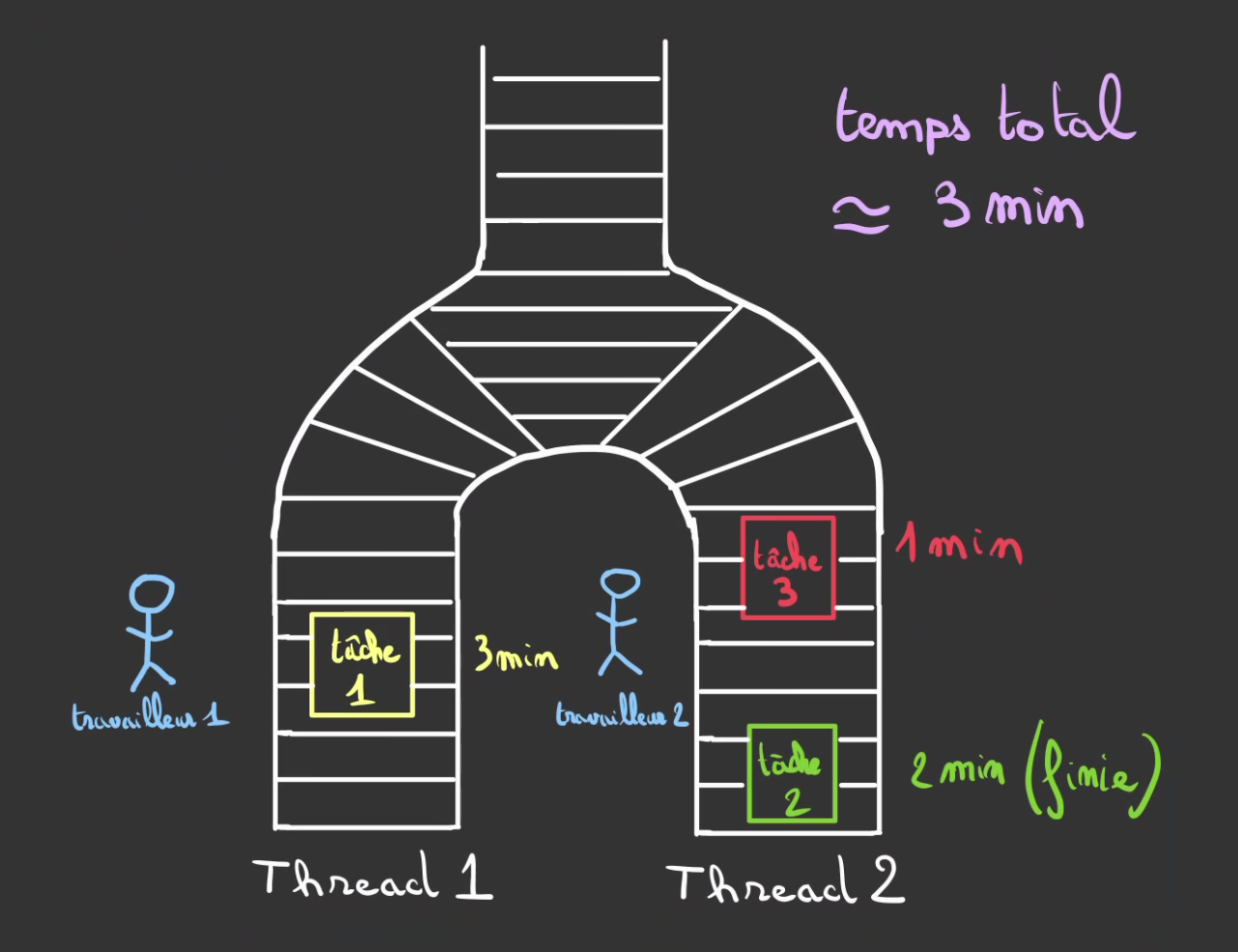
Nous avons parrallélisé le travail !
Résultat: le temps total passé à réaliser les 3 tâches n'est plus de 6 min mais de 3 min environ. 😁
Dans un ordinateur
Quoi que l'on puisse croire, un ordinateur ne sait pas faire les choses en parrallèle.
Il prend les choses une par une et les réalise séquentiellement.
S'il est en train de faire une addition, il ne fera pas une autre addition en même temps.
Par contre il est super rapide ! 3 GHz que l'on peut lire. Ce qui signifie que son coeur bat à 3 milliards de pulsation par seconde ! Et sur chaque pulsation il peut faire une action !
Notre temps n'étant pas au milliardième de seconde et même les programmes ne le sont pas. On peut faire croire à du parrallélisme en faisant quelque chose d'intelligent.
Découper le temps alloué en des bandes.
Chaque bande est appelé un Thread ou fil d'éxécution dans la langue de Molière.
Le programme s'il a 2 threads, il ressemblera à une alternance de thread 1 et de thread 2.
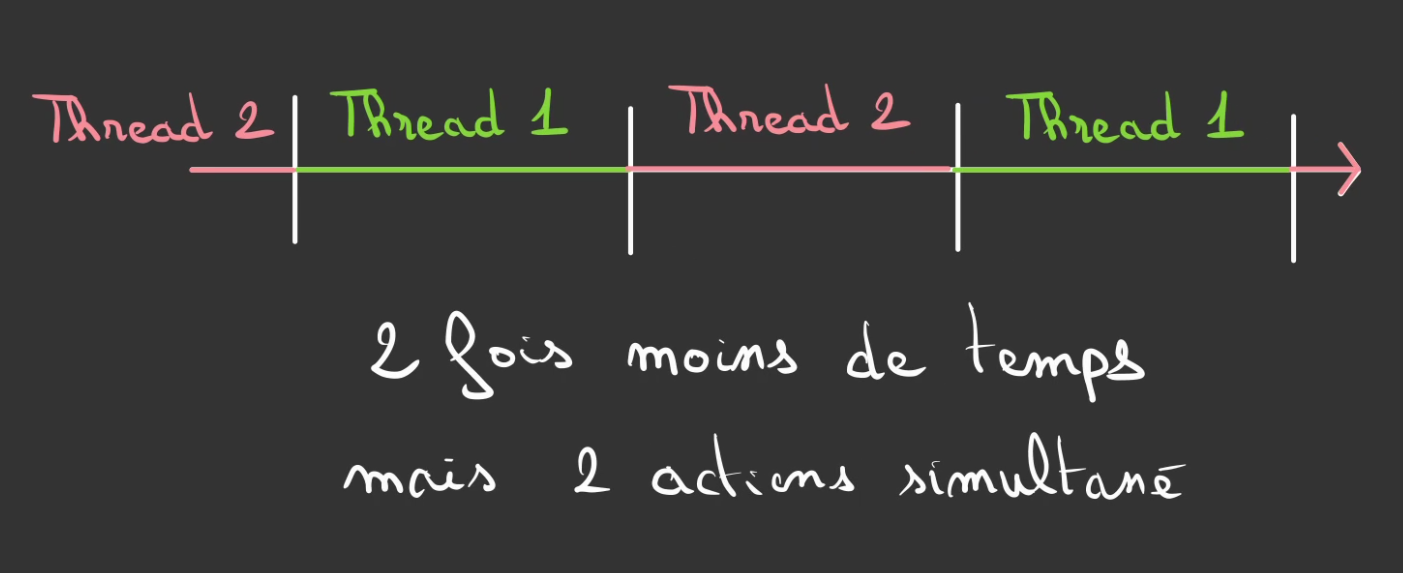
Avec 4 threads

Avec 10 threads
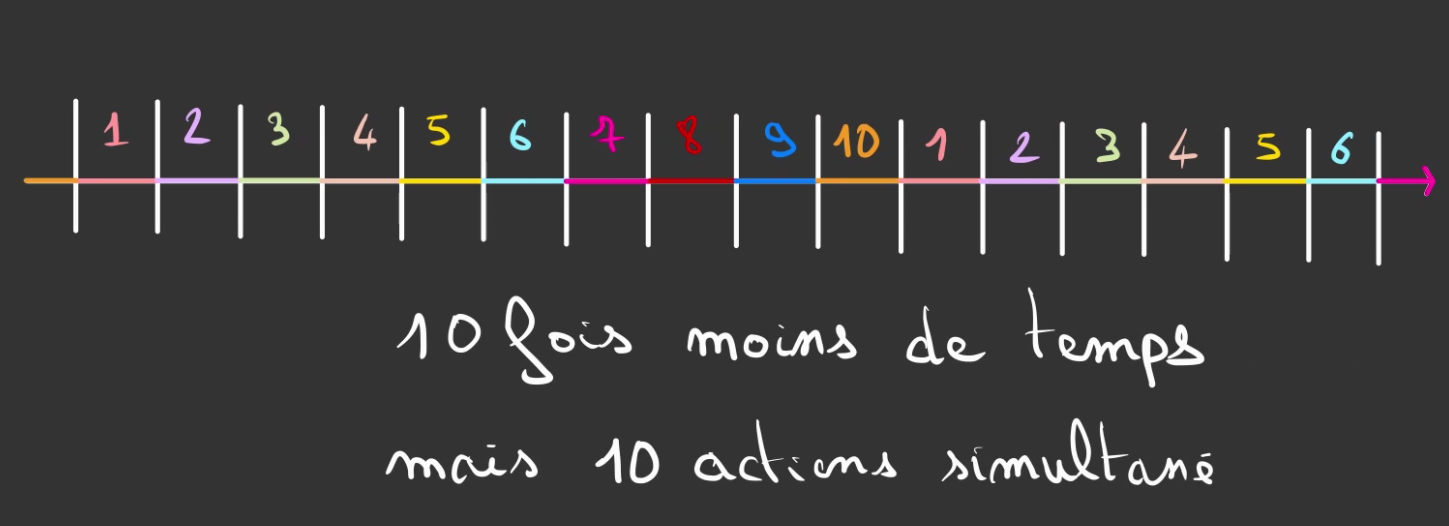
Etc ...
Plus l'on met de threads, plus le temps alloué à chacun se raccourci. C'est donc une balance à avoir entre les tâches que l'on réalise et le temps passé à les réaliser.
Si c'est mal réglé on peut même passer tout son temps à changer de contexte et plus du tout à faire des choses utiles.
Oui cette histoire de threads ressemble furieusement au Garbage Collector, et pour cause !
Le Garbage collector tourne dans un thread, le programme dans un autre. ^^
Concurrence
La concurrence est un vaste sujet. Mais disons que c'est l'idée qu'une donnée ne doit pas être modifié par plus d'une personne à la fois.
Imaginons 2 threads, dedans on réalise une modification de valeur.
Il possède en commun une variable i, celle-ci vit quelque part dans la mémoire.
i += 1
Le code est identique dans les deux threads.
Décomposons le un peu:
accumulateur <- charger i;
accumulateur <- accumulateur + 1;
accumulateur Donc ce code:
- charge de la mémoire la valeur de
i - incrémente
i - stocke la nouvelle valeur de
i
Comme je vous l'ai dit plus haut, le temps du thread est compté et dès que celui-ci arrive à terme on passe au deuxième threads.
On peut alors dans des cas bien précis se retrouver dans la situation suivante:
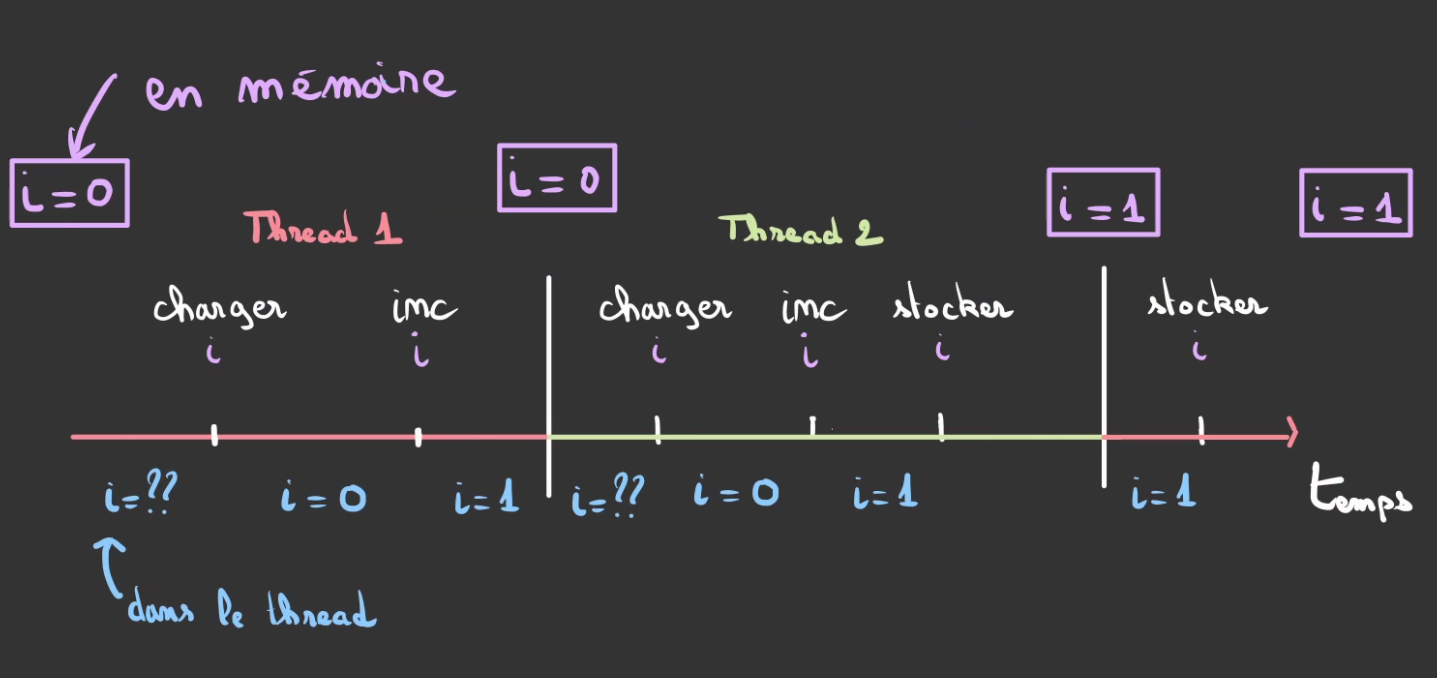
ien mémoire partagée à une valeur de $0$- Le
thread 1démarre - Le
thread 1chargeide la mémoire avec une valeur de $0$ - Le
thread 1incrémentei localqui vaut maintenant $1$ - Le
thread 1passe la main authread 2 - Le
thread 2chargeide la mémoire avec une valeur de $0$ - Le
thread 2incrémentei localqui vaut maintenant $1$ - Le
thread 2stockei local = 1dansien mémoire partagée ien mémoire partagée à une valeur de $1$- Le
thread 2passe la main authread 1 - Le
thread 1stockei local = 1dansien mémoire partagée ien mémoire partagée à une valeur de $1$
Les threads se sont télescopés! le thread 1 n'a pas eu le temps de finir, que le thread 2 a débuté et s'est terminé.
Résultat, au lieu d'avoir i = 2, nous avons seulement i = 1. Car le thread 1 qui va redémarrer va écraser ce que le thread 2 a fait.
On appelle ça une Race condition, elle n'intervient que dans des cas biens précis de mauvais timing, mais quand cela arrive, on fait n'importe quoi !
Pour résoudre se problème nous allons utiliser un outil appelé un Lock. Il s'agit d'un marqueur qui explique que la variable est en cours d'utilisation et ne peut actuellement pas être modifiée.
Notre code tournant dans les thread devient alors:
lock;
i += 1;
release;
Que l'on décompose en :
acquérir;
accumulateur <- charger i;
accumulateur <- accumulateur + 1;
accumulateur ;
Temporellement cela donne :
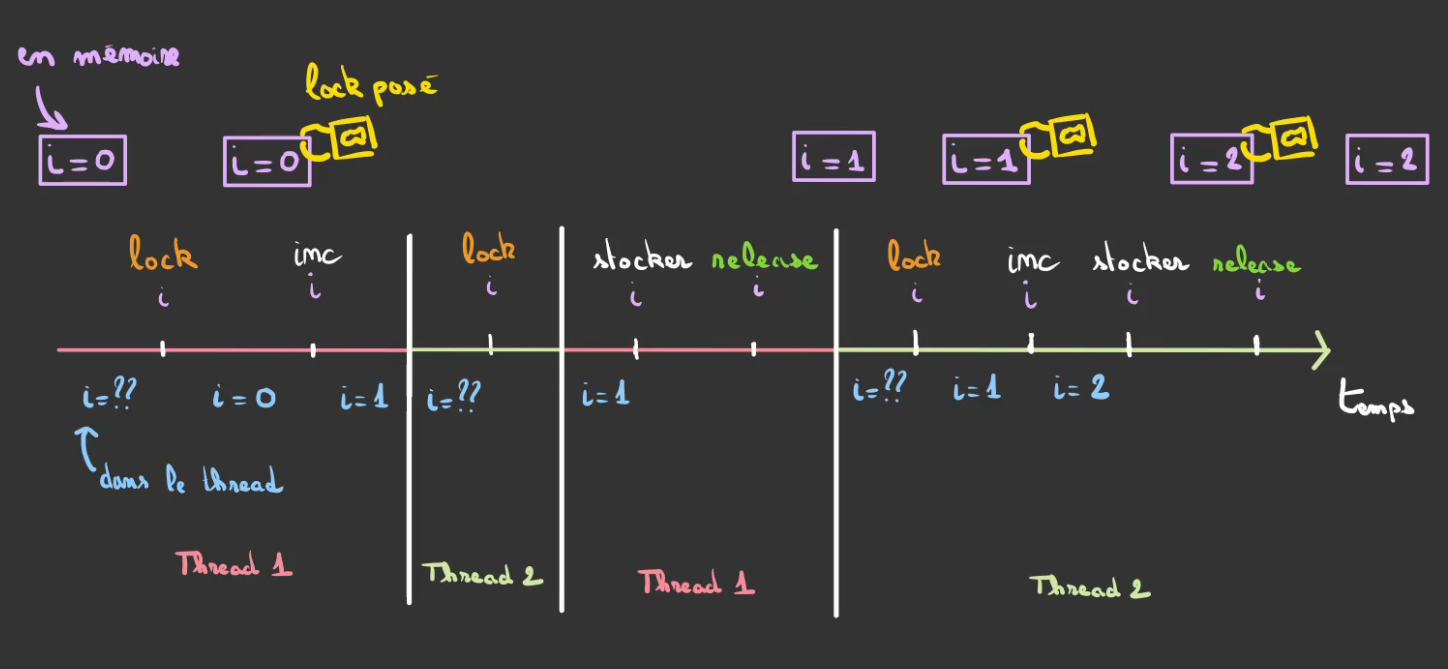
ien mémoire partagée à une valeur de $0$- Le
thread 1chargeide la mémoire en acquérant le droit de modification avec une valeur de $0$ - Le
thread 1incrémentei localqui vaut maintenant $1$ - Le
thread 1passe la main authread 2 - Le
thread 2tente de chargerimais il déjà acquis parthread 1 - Le
thread 2passe la main authread 1 - Le
thread 1stockei local = 1dansien mémoire partagée ien mémoire partagée à une valeur de $1$- Le
thread 1libèrei - Le
thread 1passe la main authread 2 - Le
thread 2chargeide la mémoire en acquérant le droit de modification avec une valeur de $1$ - Le
thread 2incrémentei localqui vaut maintenant $2$ - Le
thread 2stockei local = 2dansien mémoire partagée ien mémoire partagée à une valeur de $2$
Ici la manière dont le système réagit est complètement différente. Une fois qu'un thread a acquis la possibilité de modifier une variable partagée. les autres threads doivent attendre qu'elle soit libérée avant de pouvoir eux-même l'acquérir.
Cela suppose donc que certain threads vont faire des tours à "blanc" car il ne pourront pas acquérir la propriété en modification de la variable.
Mais par contre, cela règle le soucis de race condition étant donnée que le premier arrivé sera le premier servi et que les suivants attendront bien sagement derrière.
Attention
Si le
thread 1ne libère pas la variable à la fin de son exécution, lethread 2ne pourra plus l'acquérir.Par exemple
thread 1crash avant libération.On nomme ça un DeadLock of the Death.
Et Rust dans tout ça ?
La raison d'être de Rust est de profiter des architecture multi-coeur des CPU modernes et donc de paralléliser tout ce qui peut l'être. C'est aussi ce que fait le Java, mais avec une JVM et tout un tas d'outils qui rendent les choses plus que contraignante et moins "bas niveau" que du C, par exemple.
Sauf que faire de la concurrence en C, et bien c'est un peu la même limonade que de gérer de la mémoire à la main. C'est un enfer, on peut facilement se tromper et souvent c'est sous-optimal lorsque c'est mal fait.
Pour comprendre le besoin, il faut remonter à l'époque où Rust était développé à Mozilla. Ils avaient un besoin. Le moteur de rendu des pages était vieillissant, il était basé sur du code écrit en C/C++ et donc un peu casse-pieds pour être poli à maintenir au niveau du parrallélisme.
C'est alors qu'ils se sont aperçus à Mozilla qu'il y avait un side-project dans un coin qui était plutôt pas mal. La base du langage était de faire un langage compilé qui gère de manière sécurisé la concurrence et la programmation parrallèles.
Oh bah ! Dis donc ! Tiens alors ! S'ti pas exactement le besoin !
Et c'est des prémices de Rust qu'est sorti Servo.
Qu'est ce que Rust a sous le capot niveau parrallèlisme ?
Et bien, le premier exemple avec la race condition est tout simplement impossible à compiler !
Le langage ne permet pas de faire des choses qui pourrait avoir des comportements non déterministes avec la mémoire.
De fait tout une typologie d'erreurs est éliminée d'emblée par le compilateur.
De même le Deadlock bien qu'existant peut également être réparé avec les outils du langage.
Tout cela permet de réaliser du parallélisme sans les inconvénients de la gestion de la mémoire ou de la concurrence qui lui sont associés.
Asynchronisme
J'ai un peut tapé sur Javascript lors de la partie sur le typage. Mais clairement la gestion de la l'asynchronisme est top dans ce langage.
Mais qu'est ce que l'asynchronisme ? 🧐
L'asynchronisme c'est quand on ne sait pas à l'avance quand est-ce que l'on aura la réponse à ce que l'on a demander.
Quand deux personnes discute vocalement, la discussion est synchrone. L'un parle, l'autre répond et le délais entre les répliques est négligeables.
Par contre dans une discussion par mail. L'un peut envoyer un mail et le destinataire répondre 2 jours plus tard. On parle de communication asynchrone.
En gros on ne sait pas quand et même si ça répondra.
C'est pareil en informatique.
Certaines tâches sont considérées comme synchrones, d'autre non.
Faire une addition c'est rapide, aller chercher sur le net le contenu d'une page c'est lent !
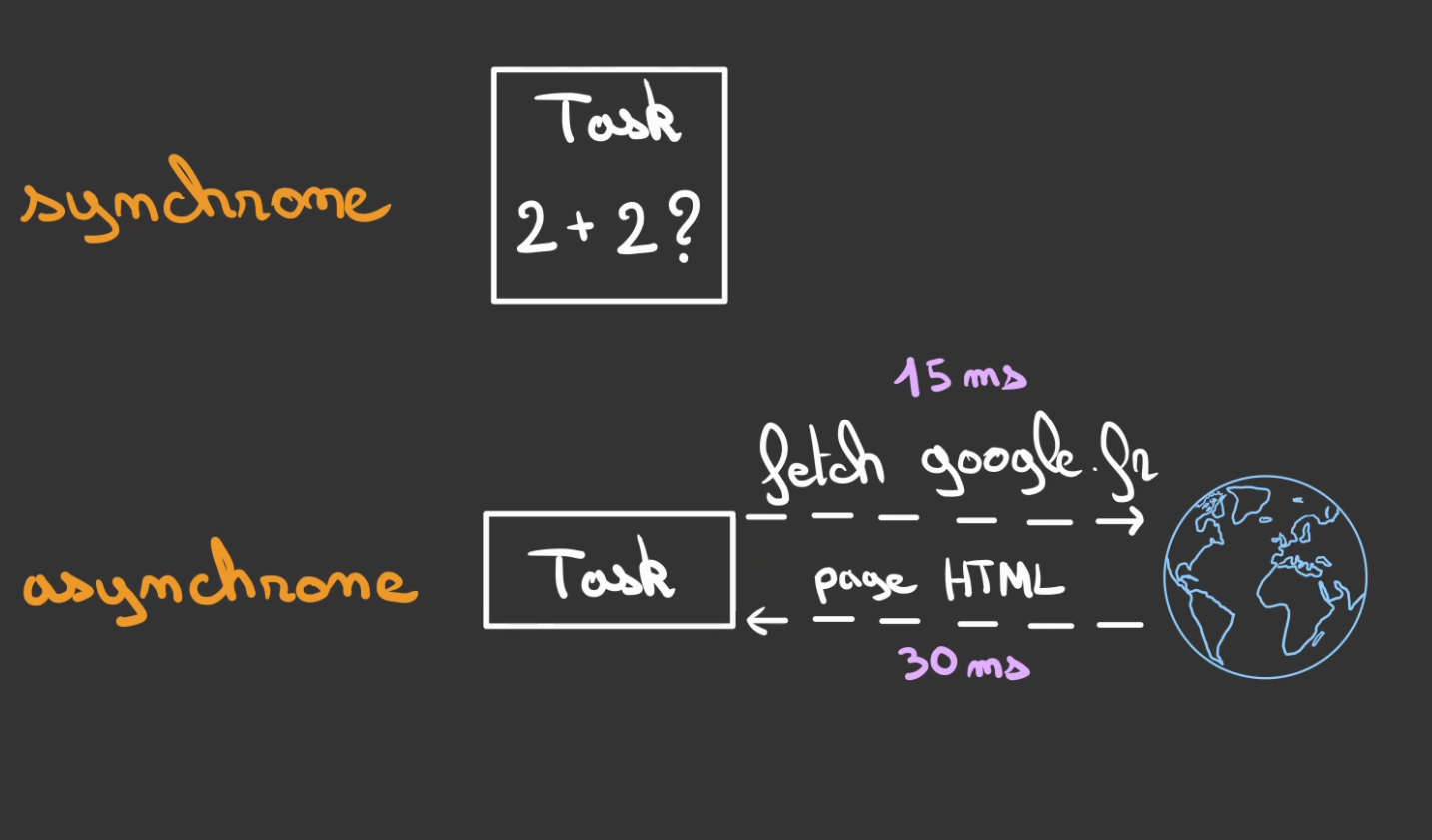
Et du coup qu'est ce qu'on fait en attendant ? Ben rien ! On attend ...
Tâche bloquante
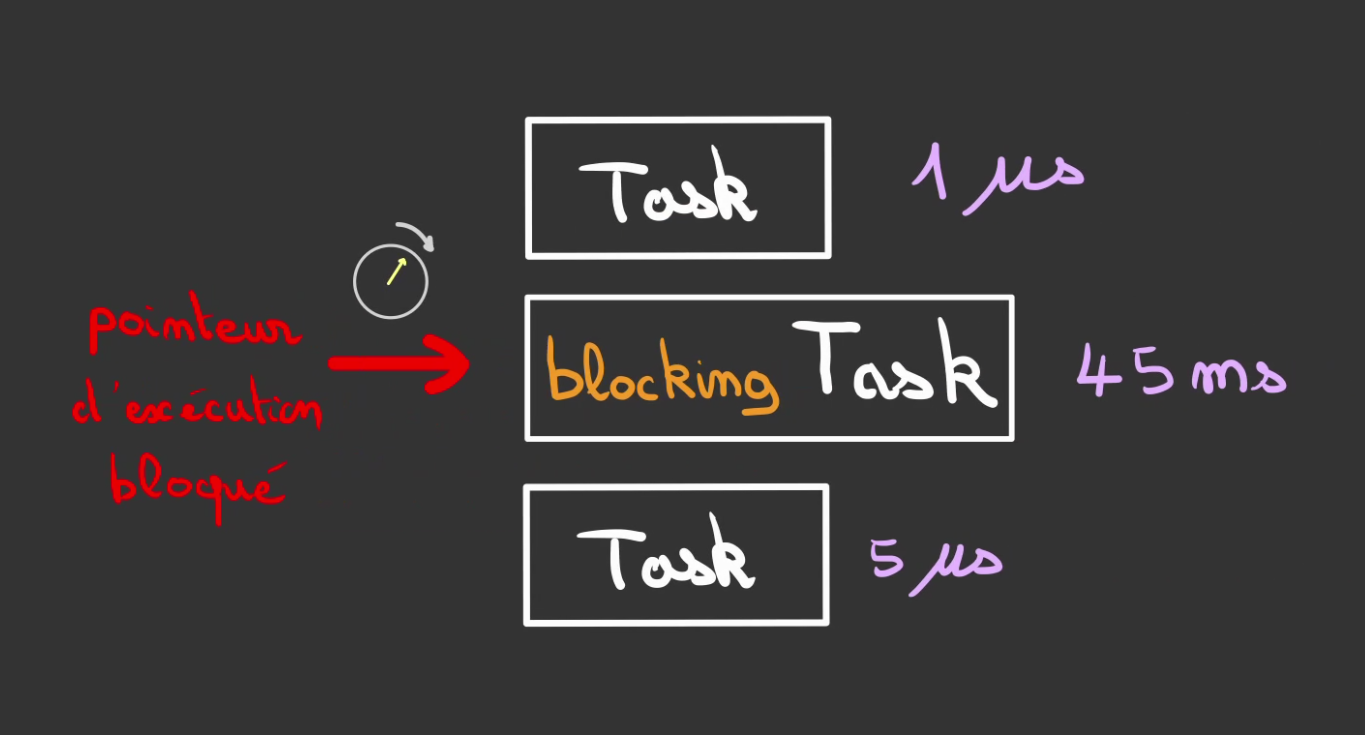
La première tâche est très courte, suffisamment pour que l'utilisateur la considère synchrone.
La seconde par contre est de l'ordre de la milliseconde. On nomme ceci une tâche bloquante.
En imaginant que la tâche 3 est la mise à jour de l'affichage du curseur de la souris.
Nous nous retrouvons avec la souris bloquée le temps que la page web ne charge ... 😥
Pire si elle ne charge jamais, c'est finito, le programme est bloqué éternellement.
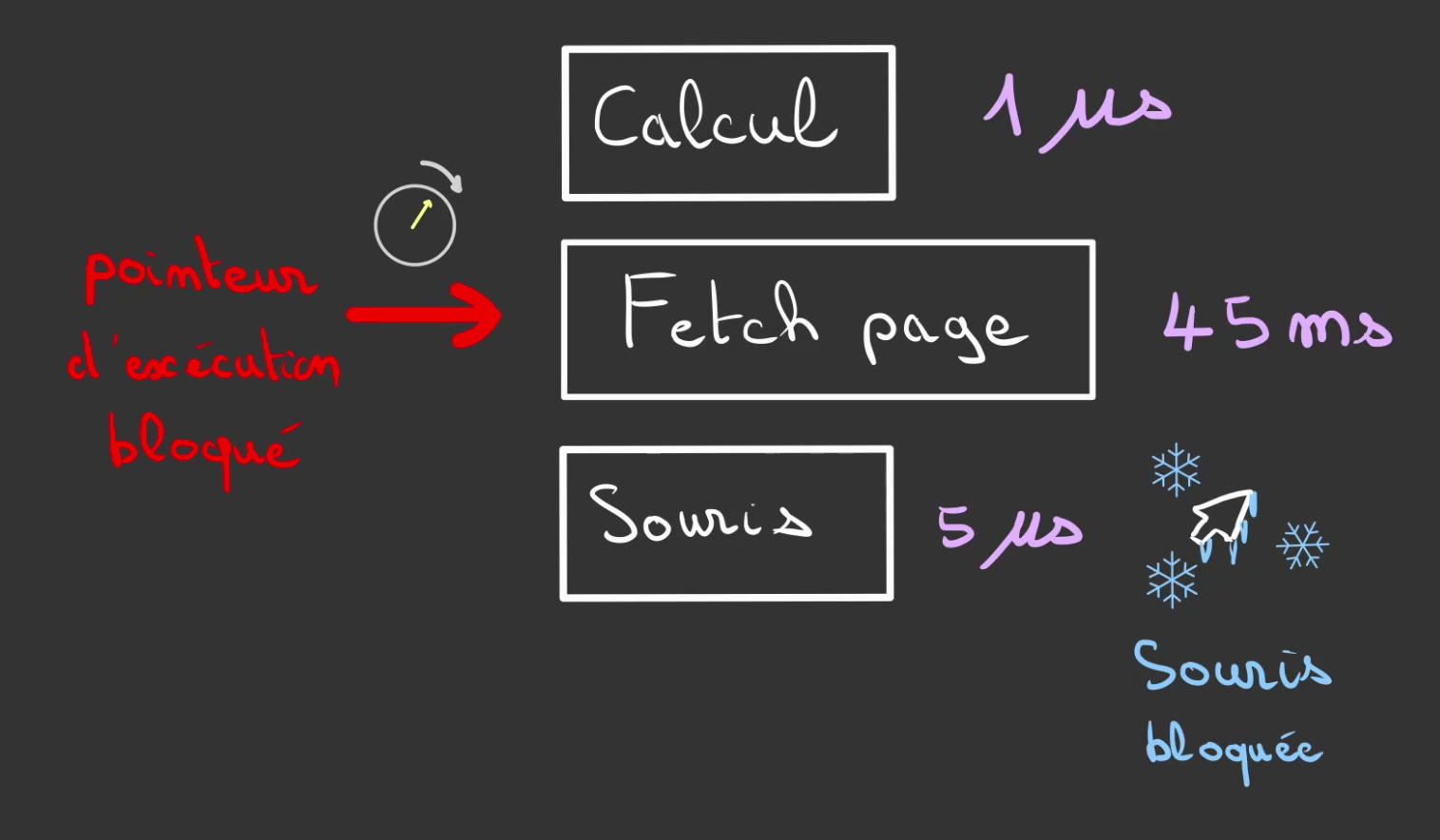
L'idée est donc d'utiliser ce que l'on a appris précédemment. Les threads !
On met un premier thread à réaliser en boucle la mise à jour du pointeur de la souris.
Et dans un second le fetch de la page.
Ainsi la souris n'est jamais bloquée, même si la page ne charge jamais.

Donc victoire, non ?
Sur le papier, oui...

Le javascript est mono-threadé. Autrement dit, il n'est pas possible d'avoir plus d'un thread.
Event loop
De fait on se retrouve dans une situation similaire à ne pas avoir de thread du tout (même si c'est plus compliqué que ça ...).
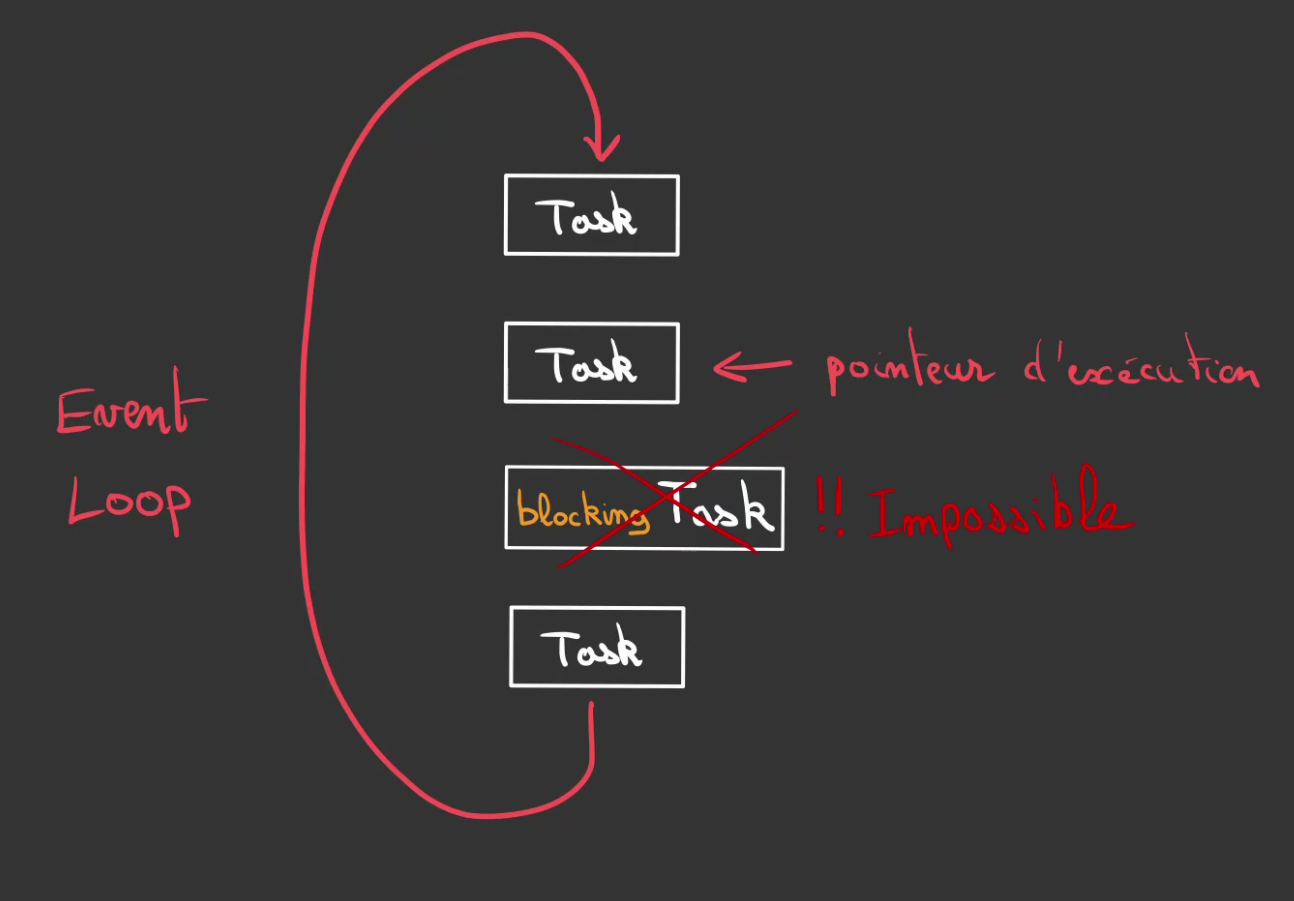
On ne peut pas avoir de tâche blocante dans notre boucle d'évènement ou Event Loop.
Comme l'on ne peut pas déporter le travail dans un autre thread. Il faut que l'on trouve une autre manière de déporter la travail.
Cela tombe bien, un programme en JS ne trourne pas seul, on peut demander à quelqu'un d'autre de faire le travail à notre place.
Ce quelqu'un se nomme un Kernel.
Mais pour cela encore un peu d'architecture système pour bien comprendre.
Le navigateur internet n'est pas le seul programme qui tourne sur un ordinateur, si plusieurs programmes ont besoin en même temps d'accéder à la carte réseau. Il faut un chef d'orchestre. Ce chef d'orchestre est le Kernel.
Il est le seul à pouvoir discuter avec les périphériques (carte réseau, écrans, imprimantes, disques, ...).
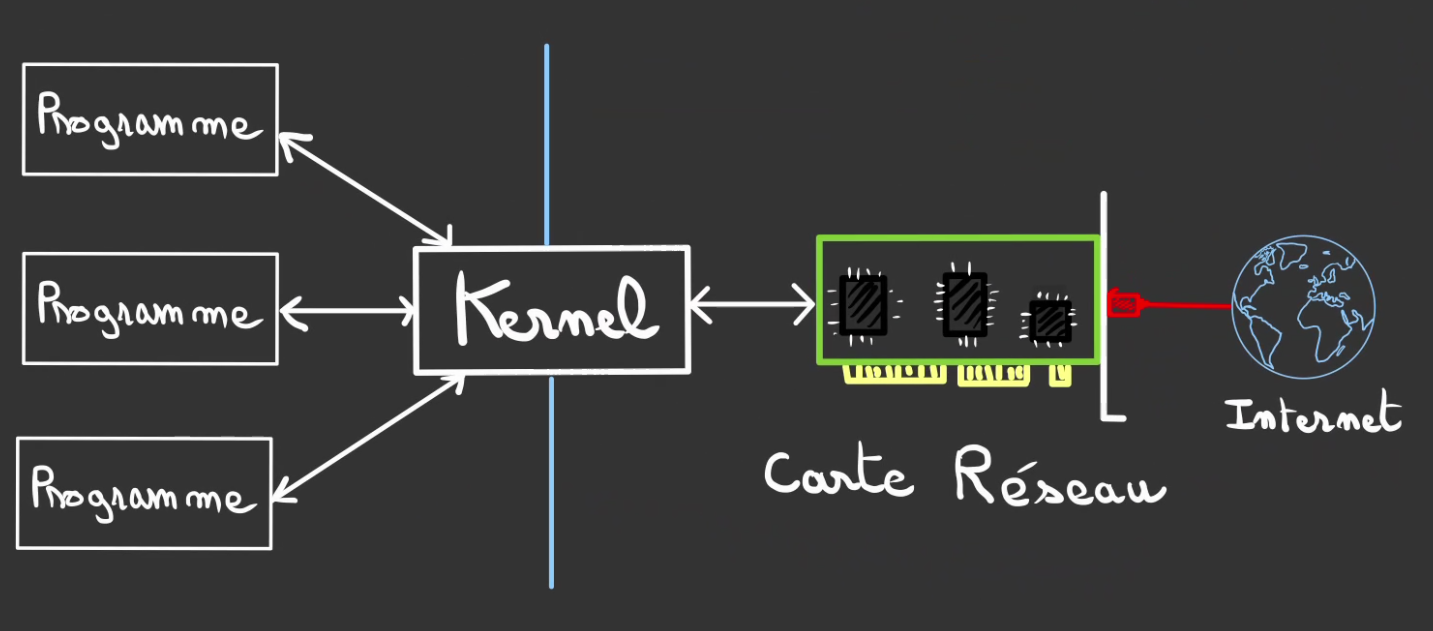
Le javascript ne peut pas parler directement avec la carte réseau.
- Le kernel l'en empêche
- Le JS ne parle pas la langue de la carte réseau
Et en autre chose, nous pouvons gentillement lui demander d'aller chercher la page à notre place.
Cette demande est instannée, par contre le Kernel fera la vraie demande quand il aura le temps.
Il nous dit alors, "quand j'aurai fini, tu pourras trouver la réponse à cet emplacement".
Ainsi le fait de demander au Kernel est synchrone et non bloquant.
Par contre le fait d'attendre est asynchrone et bloquant.
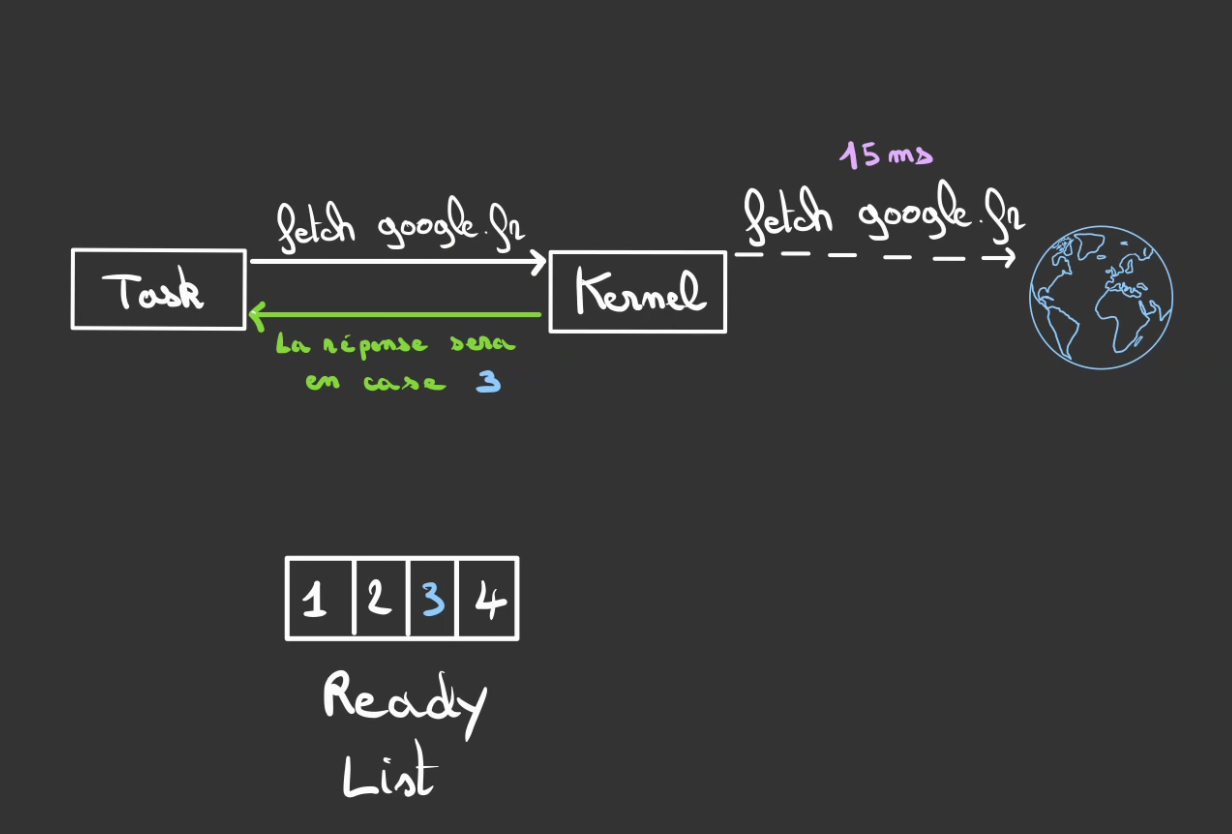
Serait-on dans la même situation que précédemment ? Au lieu d'attendre la page, on attend maintenant le Kernel ?
Que nenni !
Nous allons placer notre tâche dans une boucle et lui demander de surveiller la case où le résultat se trouvera.
Tant que les données ne sont pas là, il continue de surveiller, on dit qu'on poll.
Ce poll est une opération synchrone et suffisamment rapide pour être non blocante.
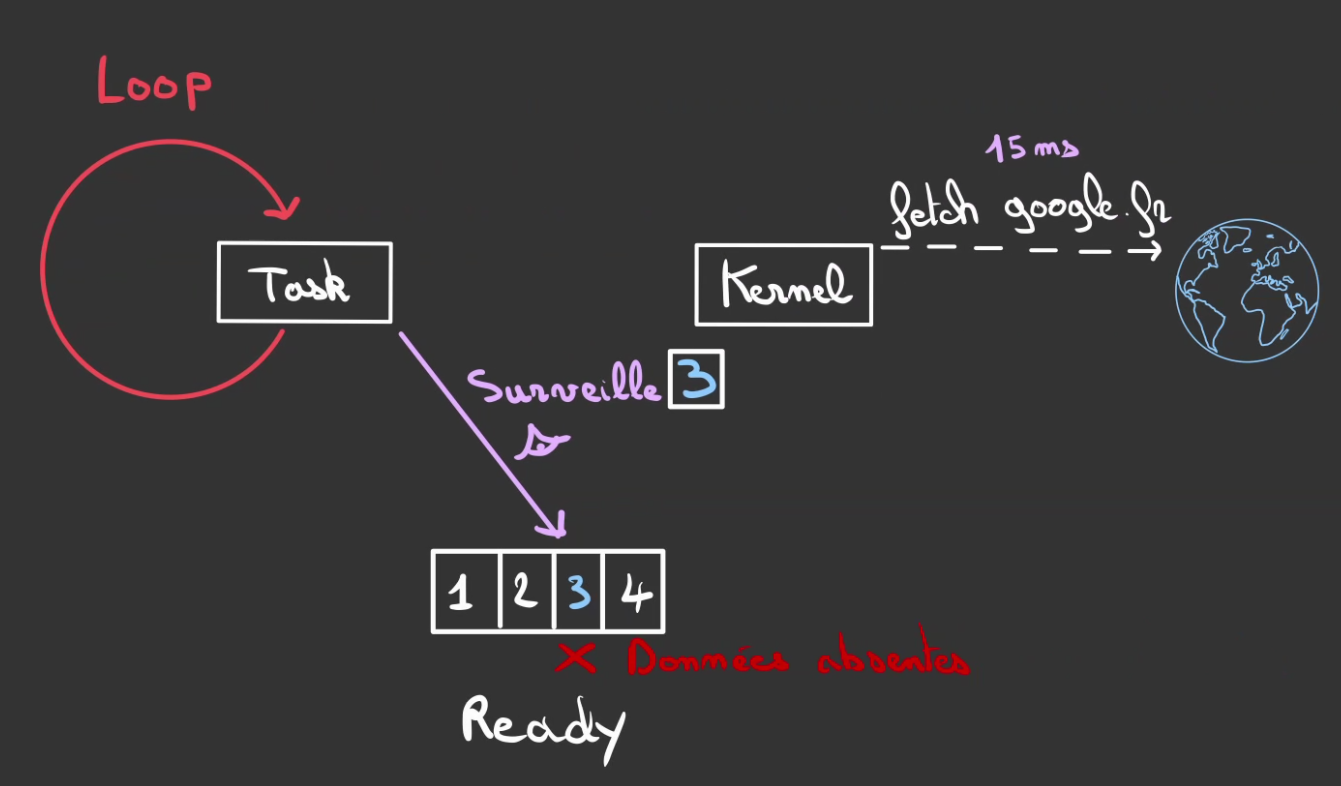
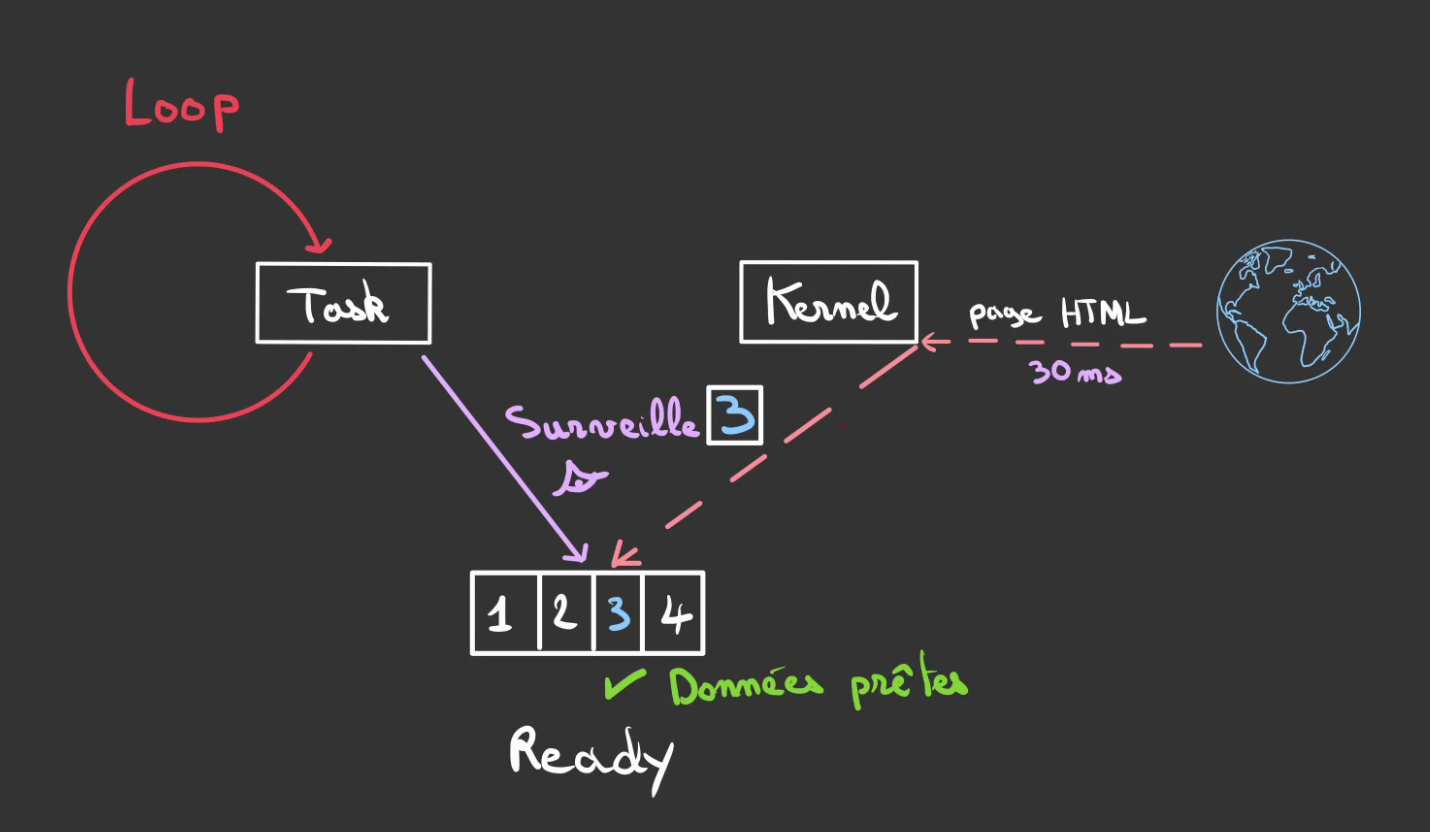
Lorsque finalement, les données sont enfin là.
Le Kernel, l'indique.
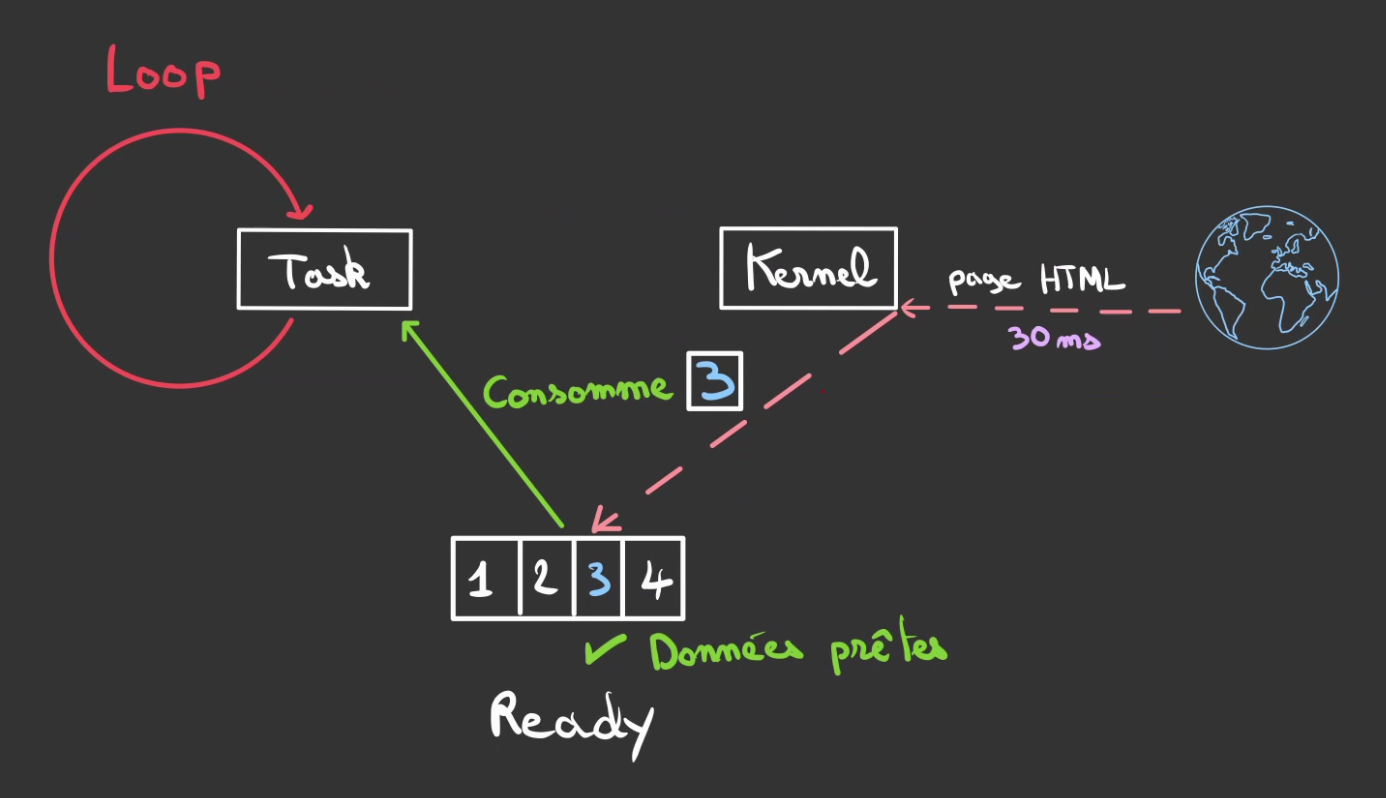
Lorsque la tâche détecte que les données sont prêtes.
Elle se met à consommer.
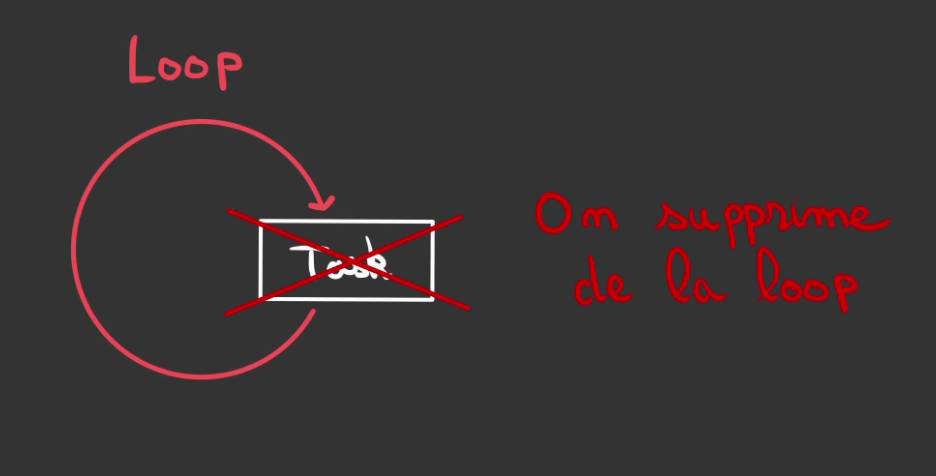
Et une fois que la tâche est terminée, on la retire de la boucle.
Plusieurs tâches asynchrones
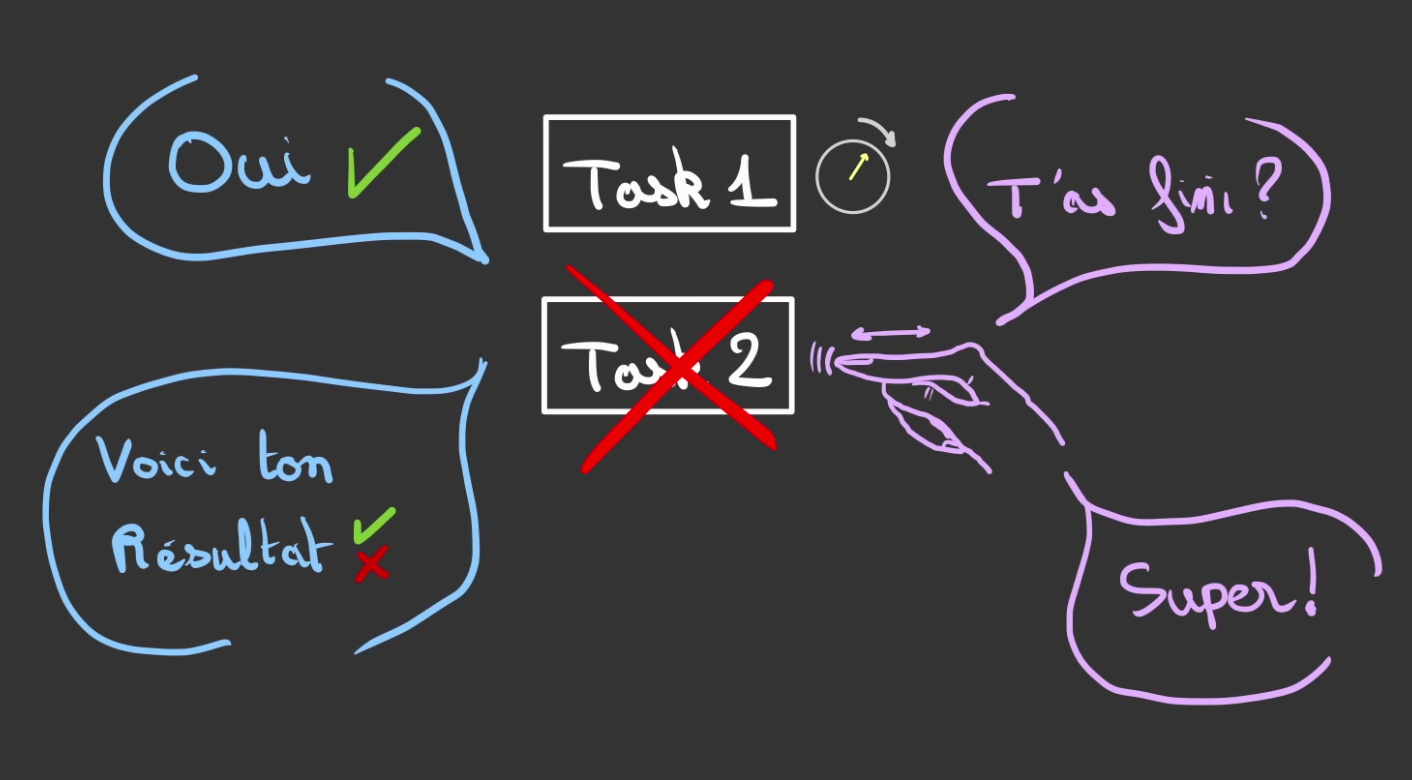
A partir du moment où l'on est capable de gérer une tâche, on peut en gérer plusieurs.
L'Exécuteur est l'entité qui est chargé de réveiller périodiquement les tâches pour qu'elles vérifient si ce qu'elles ont demandés au Kernel est prêt ou non.
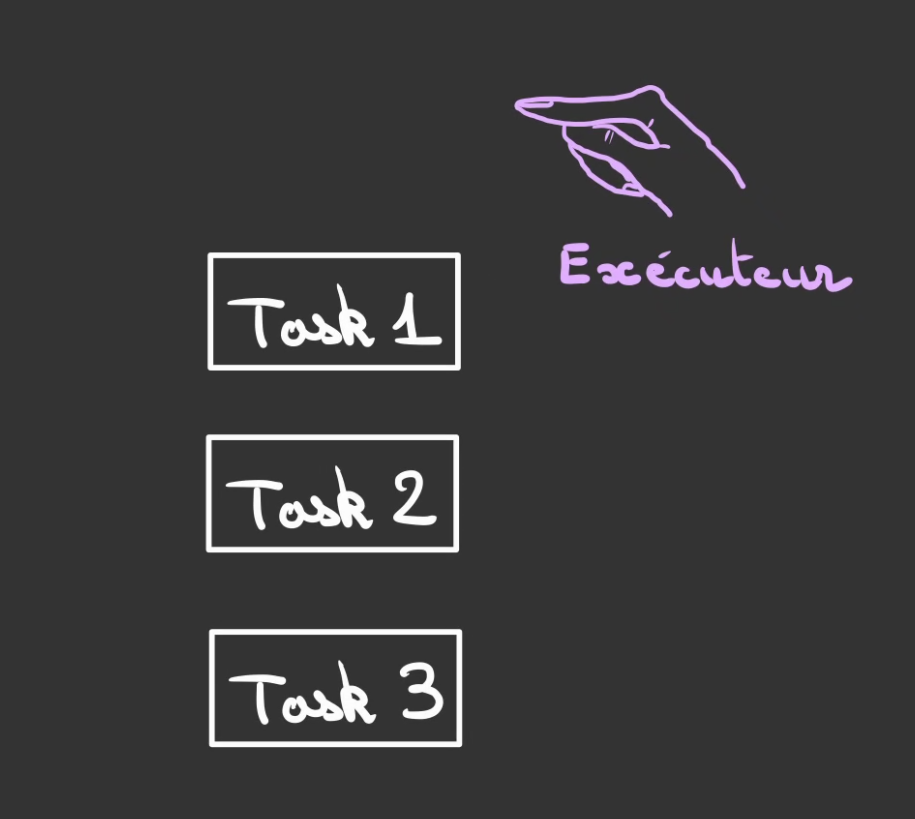
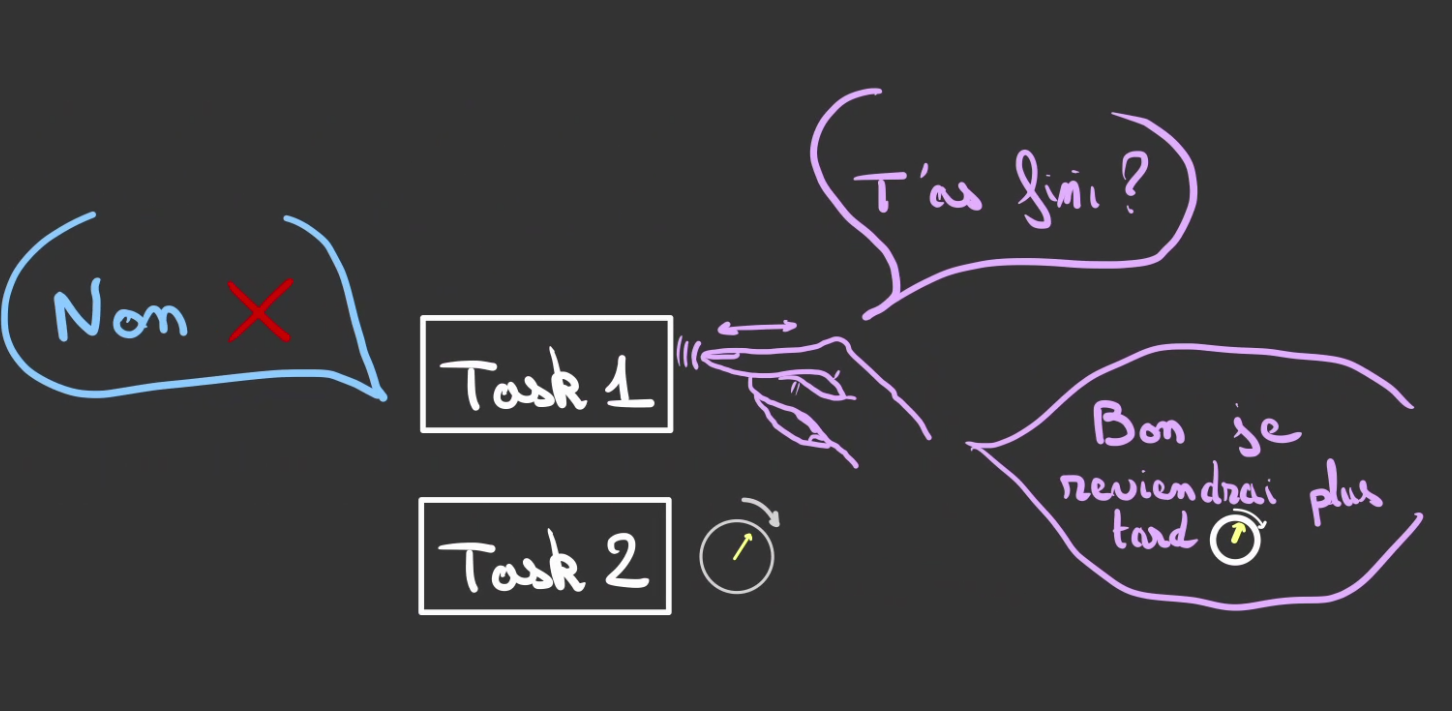
L'Exécuteur va alors passer sur chaque tâche et demander "t'as fini ?".
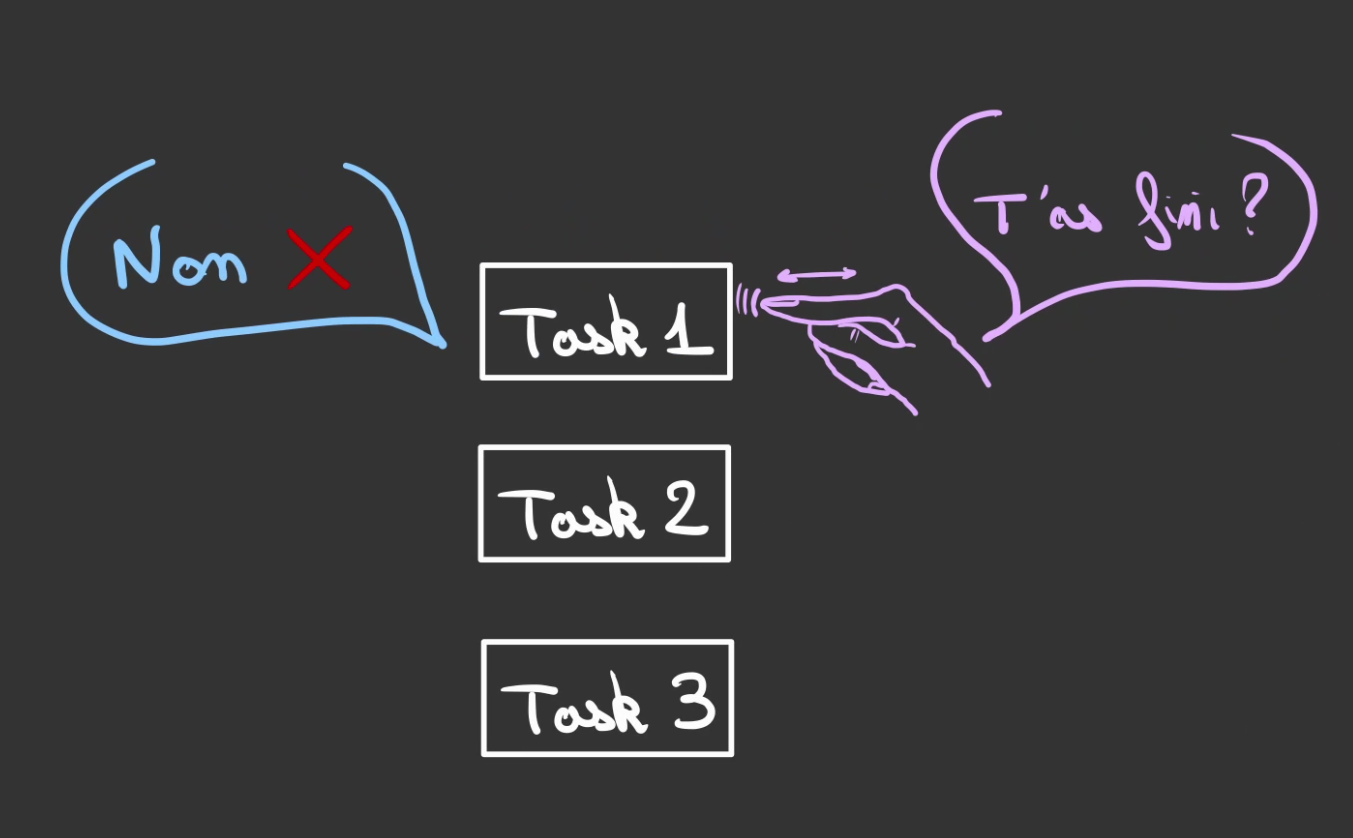
Si la réponse est négative, l'Executeur ne fait rien et passe au suivant.
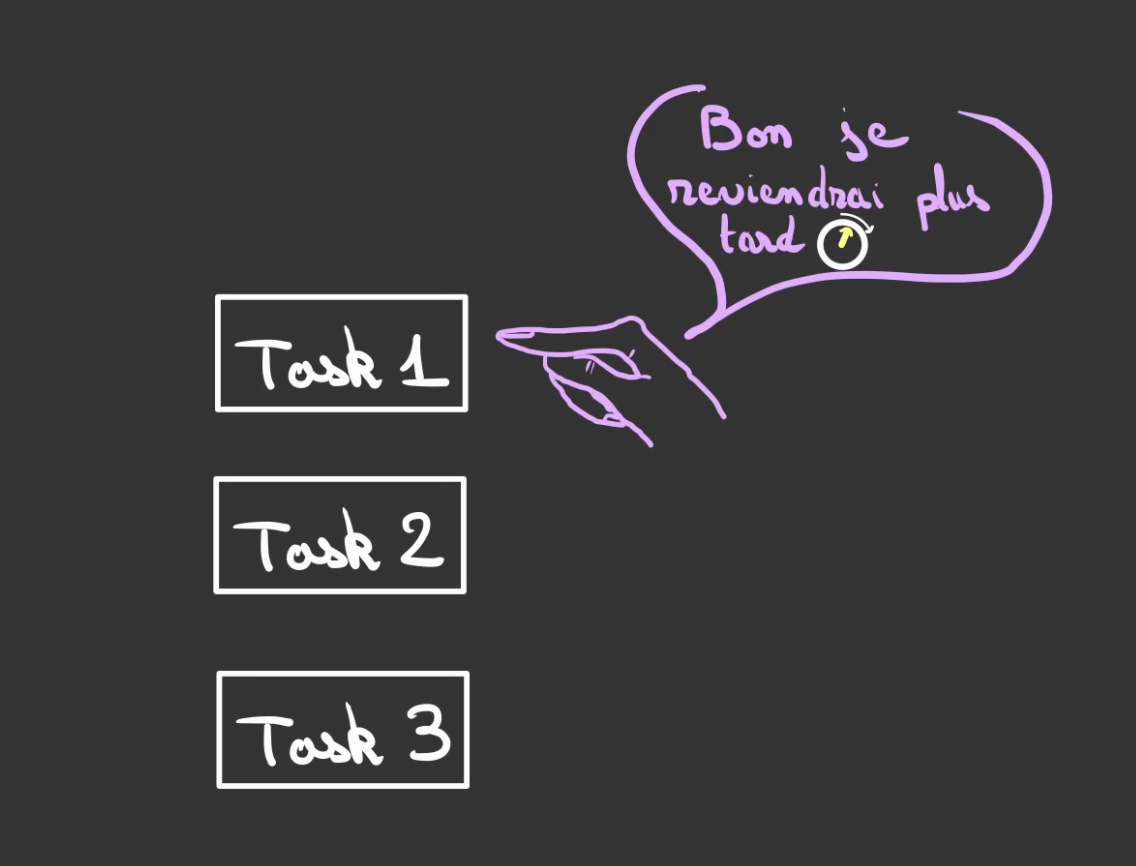
Ré-itérant l'opération.
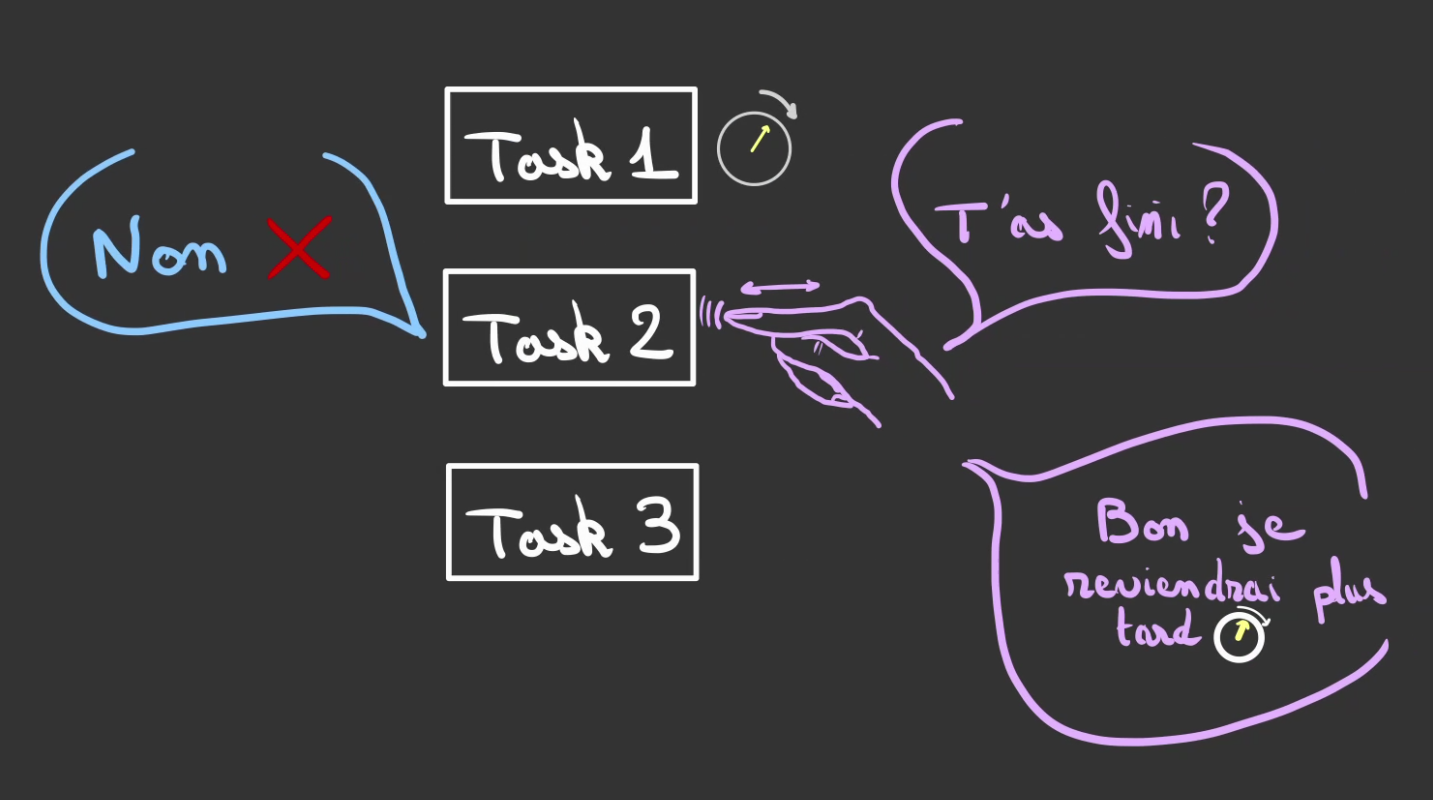
Si la réponse est positive.
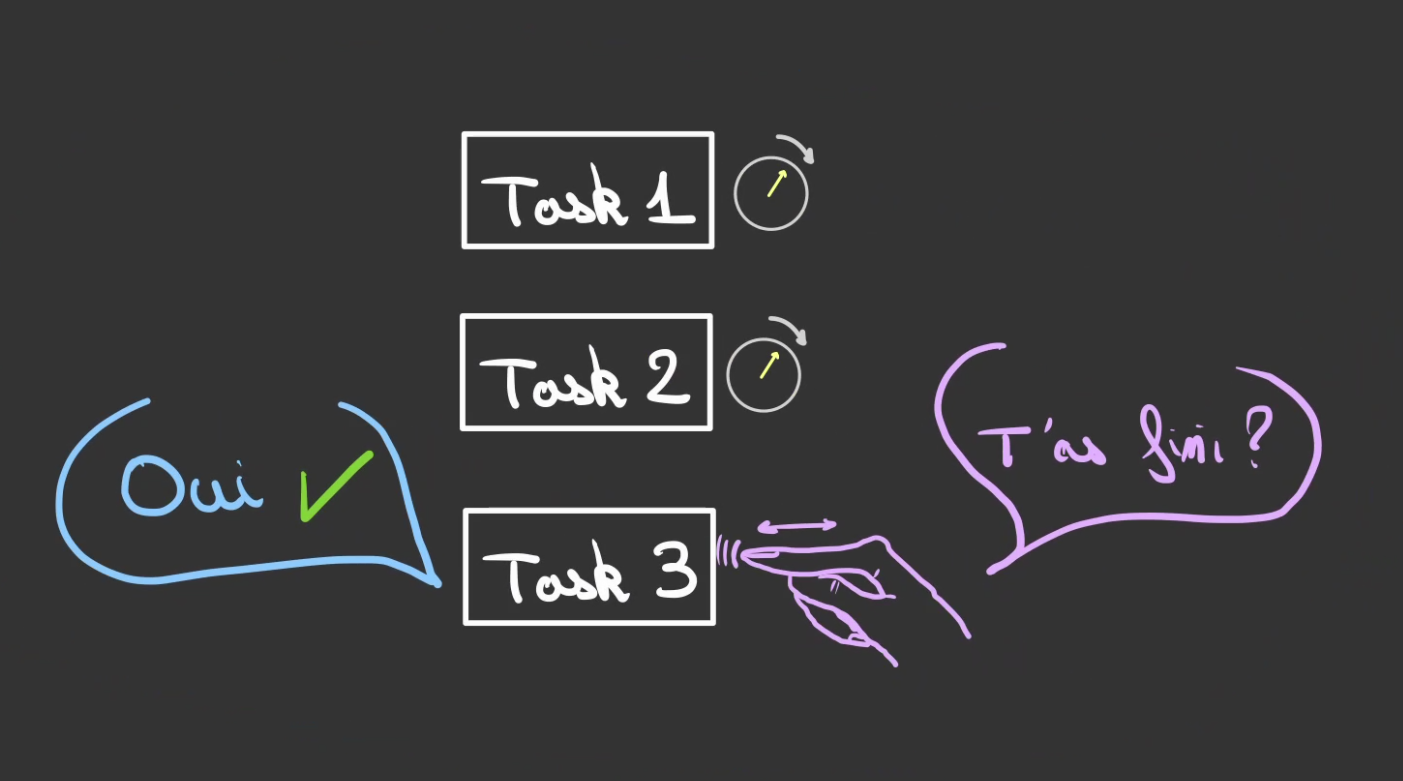
Alors l'Executeur, consomme le résultat de la tâche.
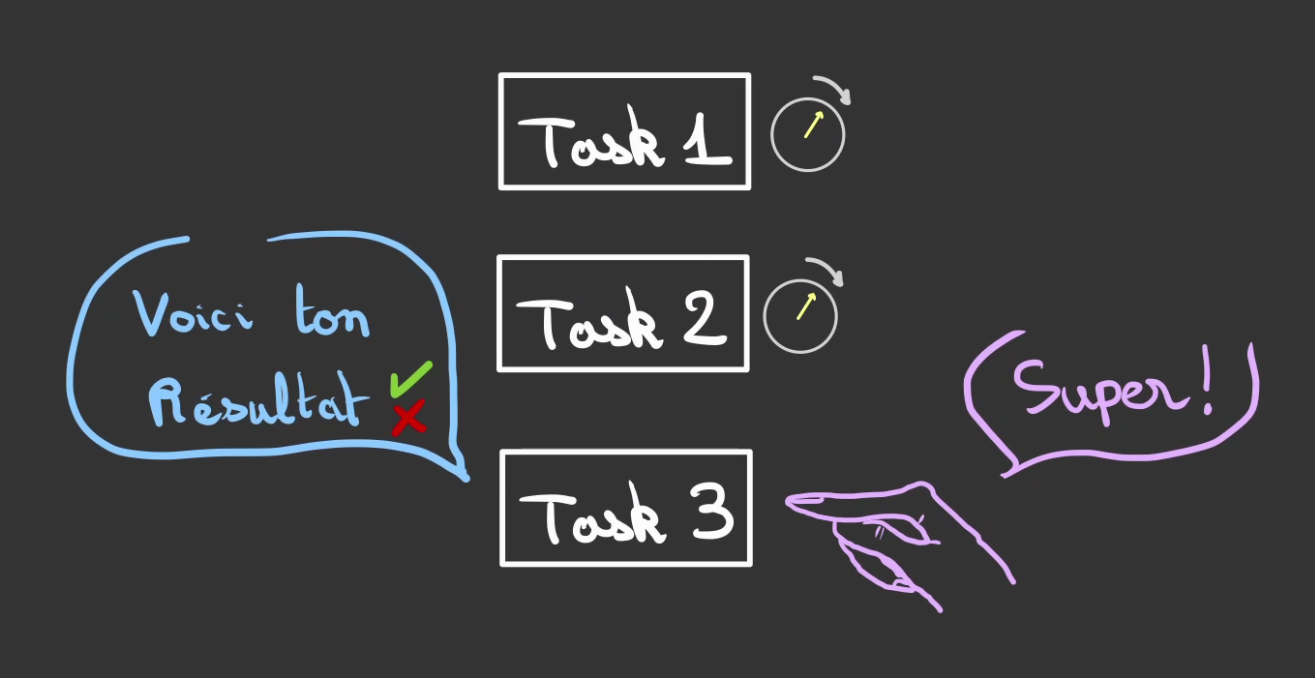
Puis désenregistre la tâche terminée.
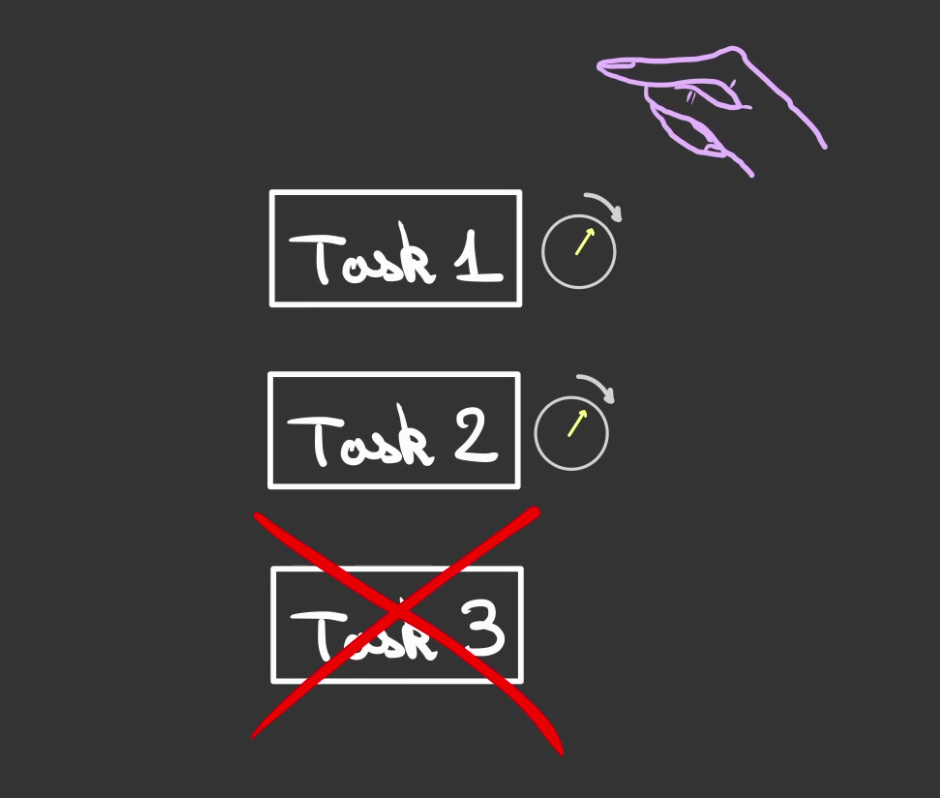
Le cycle alors recommence.
Jusqu'à ce qu'il n'y ait plus rien à faire.
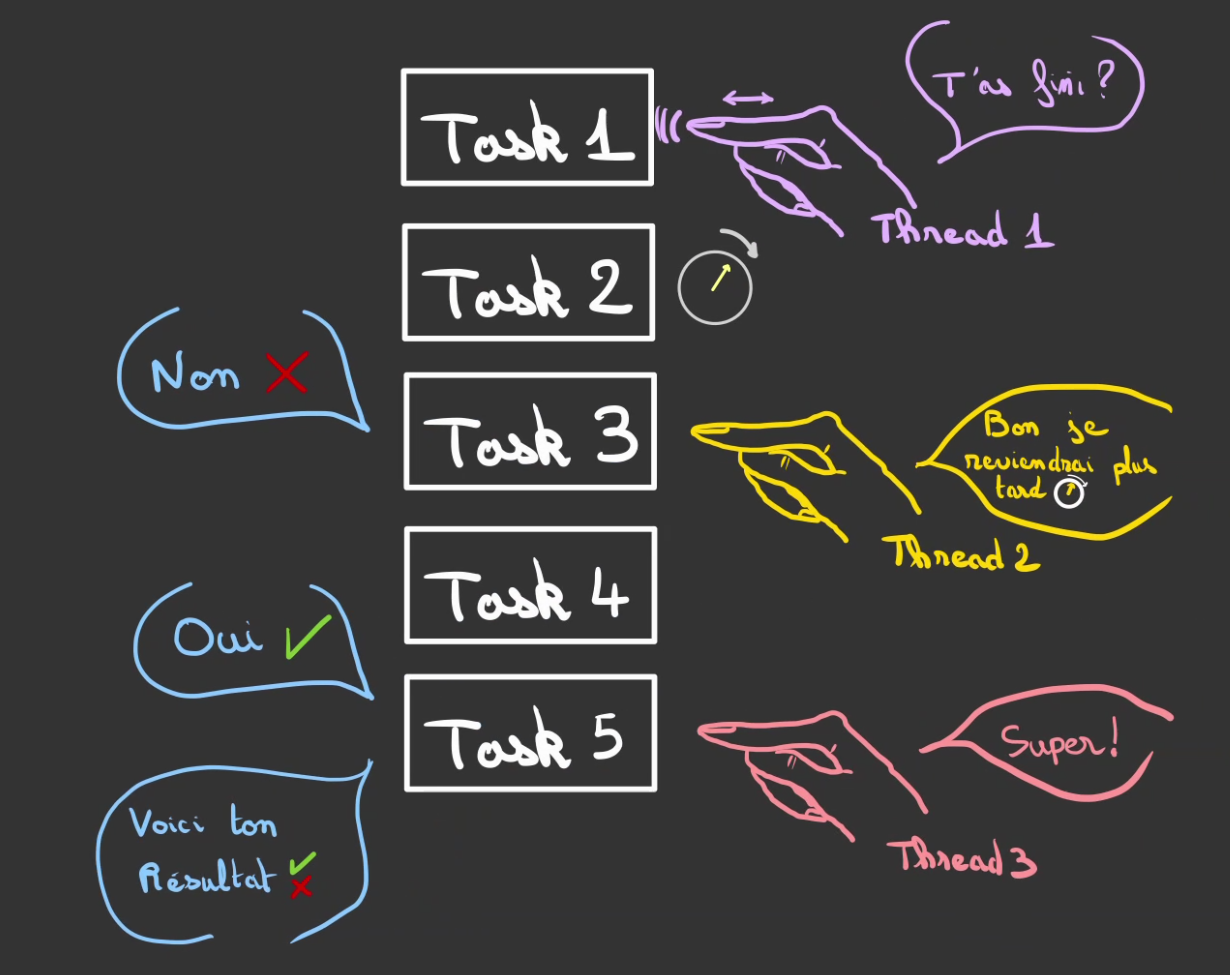
Chose intéressante. Il est possible quand le langage le permet de combiner les deux:
- les tâches asynchrones
- les threads
En effet, on peut três bien avoir plusieurs exécution en simultanné dans des threads différents.
Et donc gérer bien plus de tâches en parrallèles.
En Javascript
Le javascript a la plus belle API d'asynchronisme. Cette APi ayant été développée très tôt dans la vie du langage pour régler le problème du mono-threading.
Par exemple, si l'on veut attendre 1 seconde avant de réaliser un travail.
On utilise alors la fonction setTimeout du langage, qui prend deux paramètres:
- la fonction a exécuter lorsque le temps est écoulé
- le nombre de millisecondes à attendre
, 1000;
"maintenant";
Cela affichera dans la console
maintenant
// une pause
1 seconde après
On a bien le bon comportement, on fait la requête d'attendre 1 seconde, ce qui est synchrone et non bloquant. Ce qui permet de passer instannément à la tâche suivant d'écriture de "maintenant".
Il est possible de créer ses propres fonctions aynchrones.
Pour cela, nous utilisons un outil du langage appélé les promesses ou Promise.
La Promise prend en argument une fonction, que l'on nomme resolver.
Lorsque le timeout est terminé (qui est lui même une Promise). La méthode resolve est appelée avec le résultat de la promesse.
Cela a pour conséquence d'appeler la méthode then qui possède le résultat en paramètre. Et finalement exécuter le console.log.
new Promise
Ici encore la console affiche instannément
register
end register
Promise
Mais marque un temps d'attente de au moins 1 seconde avant d'afficher
1 seconde après
Ce qui est le résultat attendu.
Petite remarque sur le Promise {<pending>}.
Ceci est le résultat du new Promise, c'est une promesse mais pas encore réalisée d'où le <pending>.
Si vous voulez un tour d'horizon plus complet, la doc est ici. 😀
Maintenant on peut également vouloir temporiser le démarrage du timeout.
Et ainsi pouvoir faire:
1000;
Ok, les promesses c'est cool mais est ce qu'on peut faire mieux ?
Oui biensûr !
Le javascript moderne introduit une syntaxe basée sur les mot clefs:
- async : définit une fonction comme asynchrone (définie une Promise)
- await : permet d'attendre la résolution d'une fonction asynchrone (comme then)
;
Ce qui affiche:
maintenant
Promise
1 seconde après
Par cette technique, on est capable de rendre synchrone des tâches pour attendre des résultats asynchrones.
Mais comme tout est asynchrone en réalité, les tâches bloquées ne bloque pas l'ensemble des tâches, ce qui donne une expérience développeur des plus intéressntes.
Il se passent une foultitude de choses en arrière plan mais pour le développeur tout devient simple.
;
data.id;
Il est possible de capturer les erreurs
err
En Rust
Rust possède également son API asynchrone.
use ;
async
Lien vers le playground.
Contrairement à JS, le Rust a choisi de découpler la grammaire du langage de son utilisation.
Ainsi l'Exécuteur n'est pas directement disponible. Il faut utiliser une lib qui en fourni un, ici tokio, mais il en existe d'autres.
Le but de cette partie n'est pas d'expliquer l'asynchronisme en Rust, il aura son article dédié !!
Je voudrai juste vous attirer l'attention sur la similarité d'API avec le JS.
async
La différence avec le JS, c'est qu'au lieu d'avoir:
await
en Rust nous faisons
task.await;
Discussion sur l'asynchronisme et le threading
L'intérêt principal de l'asynchronisme par rapport au multi-threading est que c'est le programme qui défini et gère le cycle de vie des tâches.
Contrairement au multi-threading où l'on est totalement dépendant du bon vouloir du système, qui peut arrêter une tâche et la relancer quand bon lui semble.
Les threads sont adaptés à des tâches longues et peu nombreuses.
Tandis que les jobs asynchrones sont préférés pour des tâches courtes et nombreuses.
C'est au développeur de penser son application en fonction des besoins à remplir.
Rust fourni les outils à la fois pour manipuler les threads mais aussi les jobs.
Ce qui en fait un langage adapté aux contraintes modernes des développements d'applications asynchrones et sur des architectures multi-coeurs.
Conclusion
En résumé.
- Rust est un langage compilé ce qui lui permet de se passer d'interpréteur ou de VM, facilitant son déploiement
- Par son aspect compilé, il peut s'adapter à une vaste catégorie d'usages (programmation système, web, moteur 3D, WASM, ....)
- Son typage très évolué permet de manipuler en toute sécurité. Très utile lors d'une refactorisation
- Ce typage permet de détecter très tôt dans le processus de développement de potentielles erreurs
- L'absence de Garbage Collector et l'analyse statique à la compilation en font un langage extrêment performant
- Rust a été construit pour les architectures multi-coeur modernes, et permet donc de manipuler en toute sécurité les primitives de threading et de job asynchrones. Ceci permettant de gérer la concurrence sans peur.
Par contre
- Rust est un langage exigeant qui demandera au développeur ou à la développeuse de respecter un certain nombre de règles contraignantes
- Le code Rust compilé est plus lourd en terme de taille sur le disque que du code C compilé qui fait la même choses
Ce travail est sous licence CC BY-NC-SA 4.0.