Centraliser et normaliser ses logs avec Vector

Bonjour! 😀
Mon nombre de VMs a explosé au cours de ces derniers mois. Je ne m'en plains pas, mais il devient de plus en plus fastidieux d'aller consulter mes logs.
Un autre de mes problèmes est que mon infra est constituée de programmes écrits dans différents langages qui ont chacun leur manière de rédiger leurs logs.
Une autre complication est l'utisation de Docker et Kubernetes qui enrobe les processus et rajoute une couche de complexité dans la compréhension du run des applications.
J'avais tout d'abord commencé à regarder le produit "Syslog" qui a fait ces preuves. Mais celui-ci ne convenait pas à mes besoins car les messages générés contenanaient trop d'informations parasites, ne permettant pas leur exploitation directe.
C'est alors que durant un de mes lives sur twitch l'un de mes spectateurs m'a indiqué l'existence d'un produit nommé Vector.
Installation
Vector est un binaire qui peut-être installé de diverses manières.
Je vais utiliser la méthode de l'installation par package.
|
Principes de fonctionnement
Vector possède une architecture fonctionnelle plutôt directe.
Il peut prendre une ou plusieurs de sources de données, réaliser une suite de transformations sur ces évènements puis les distribuer vers une ou plusieurs sorties.
L'ensemble de ce processus est appelé un pipeline.
Il est décrit dans un fichier de configuration utilisant le langage de description TOML. On peut le faire en YAML et en JSON mais ne parlons pas des sujets qui fâchent. 😁
Sources
Les entrées du pipeline sont appelées des sources.
Vector vous proposent un vaste choix de sources qui vont des plus haut-niveau comme directement se connecter à l'API Docker pour récupérer les logs des containers à des choses bien plus bas-niveau comme la lecture de socket ou de fichiers.
Une source est défini ainsi:
[]
= "type de la source"
Vous pouvez définir autant de sources que vous le désirez.
L'identifiant ma_source est le nom de votre entrée et permettra de l'identifier au sein du pipeline.
Une source a pour sortie un évènement sous la forme d'un message au format JSON. Chaque source possède sa structure de sortie qui est documentée pour chacune d'elle.
Transformations
Chaque source peut bénéficier d'une ou plusieurs transformations. Les transformations sont des opérations qui sont réalisées sur les évènements provenant des sources.
Une transformation peut prendre une ou plusieurs sources.
De même que pour les sources, Vector propose là aussi des transformations déjà existantes.
Une transformation se décrit sous cette forme.
[]
= "type de la transformation"
= ["ma_source_1", "ma_source_2"]
Le champ inputs est la collection de flux d'entrées définis par un ou plusieurs identifiants.
Il est aussi possible de chaîner les transformations pour rafiner les traitements.
[]
= "type de la transformation"
= ["ma_source_1", "ma_source_2"]
[]
= "type de la transformation"
= ["ma_transformation"]
Remap
Dans les transformations, il en existe une qui est plus spéciale que les autres. Il s'agit de la transformation remap.
Celle ci a un format un peu différent qui prend un paramètre source.
Dans celui ci, il est possible de définir des transformations personnalisées au moyen d'un langage de manipulation de données appelé le VRL.
Ce langage est ensuite converti en du Rust, permettant de bénéficier de toutes les garanties concernant le typage des données manipulé ainsi que la faillibilité des appels de fonctions et de routines de traitement.
Le langage est complet et propose tous les outils nécessaire comme l'affectatation de variable, la notion de condition, ainsi que de contextes et de blocs.
Sinks
Dans la terminologie de Vector les sorties de pipelines sont appelés des sinks.
De même une sélection de sinks pré-construits existe.
Un sink prend une collection de flux d'événements et les délivre à sa destination.
Votre pipeline peut posséder autant de sinks que vous désirez et chaque sinks prend autant d'entrées que voulu.
[]
= "type de ma sortie"
= ["ma_source", "ma_transformation"]
Cas pratique
Cahier des charges
Mon cas d'utilisation est le suivant. Je possède une série de VMs qui tournent à l'intérieur d'un réseau.
Chacune de ces VMs possède une stack Docker décrite par un docker-compose.
Le but est de centraliser les logs de toutes ces VMs, en les regroupant par container et par jours.
Par exemple si nous avons 2 machines appelées respectivement:
- docker-001
- docker-002
Et possédant chacune le docker-compose suivant:
services:
tomcat:
image: tomcat
jetty:
image: jetty
js:
image: custom-js
Alors l'aborescence de logs finaux devra ressembler à :
logs
└── by-host
├── docker-001
│ └── docker
│ ├── json
│ │ ├── tomcat
│ │ │ ├── 13-09-2021.log
│ │ │ └── 14-09-2021.log
│ │ ├── jetty
│ │ │ ├── 13-09-2021.log
│ │ │ └── 14-09-2021.log
│ │ └── js
│ │ ├── 13-09-2021.log
│ │ └── 14-09-2021.log
│ └── text
│ ├── tomcat
│ │ ├── 13-09-2021.log
│ │ └── 14-09-2021.log
│ ├── jetty
│ │ ├── 13-09-2021.log
│ │ └── 14-09-2021.log
│ └── js
│ ├── 13-09-2021.log
│ └── 14-09-2021.log
└── docker-002
└── docker
├── json
│ ├── tomcat
│ │ ├── 13-09-2021.log
│ │ └── 14-09-2021.log
│ ├── jetty
│ │ ├── 13-09-2021.log
│ │ └── 14-09-2021.log
│ └── js
│ ├── 13-09-2021.log
│ └── 14-09-2021.log
└── text
├── tomcat
│ ├── 13-09-2021.log
│ └── 14-09-2021.log
├── jetty
│ ├── 13-09-2021.log
│ └── 14-09-2021.log
└── js
├── 13-09-2021.log
└── 14-09-2021.log
Notre but va être de construire une topologie de centralisation et de normalisation de logs qui réponde à ce besoin.
Nous utiliseront bien évidemment Vector pour la plupart des opérations.
Descriptif des contraintes
Tomcat et Jetty sont des serveurs HTTP écrits tous les deux en Java mais ne génèrent pas leur logs sous le même format.
Une ligne de log Tomcat ressemblera à :
14-Sep-2021 06:48:31.489 INFO [main] org.apache.catalina.startup.Catalina.start Server startup in [102] milliseconds
Alors que Jetty renverra plutôt des messages de logs ainsi:
2021-09-14 06:48:34.560:INFO:oejs.AbstractConnector:main: Started ServerConnector@11245489{HTTP/1.1, (http/1.1)}{0.0.0.0:8080}
Nous avons aussi dans notre stack une application NodeJs qui possède de même, sa propre façon de créer ses logs.
Vous pouvez retrouvez dans ce projet les sources de l'image NodeJS.
Cette image écrira ses logs sous cette forme:
2021-09-14T06:52:52.480Z [main] info: Application started
Comme vous pouvez le voir chacun de ces logs signifie que l'application a démarré mais aucune de ces lignes n'est identique d'un container à un autre, ce qui complexifie grandement le traitement des logs de notre stack Docker.
Nous allons devoir normaliser tout ça! 😀
Une autre contrainte est que les stacks Docker sont séparées les unes des autres dans des VMs pour des raisons de sécurité et scalabilité.
Il va donc falloir rappatrier ces logs normalisés au niveau d'un point unique qui se chargera de leur aggrégation.
Topologie
Une des règles que nous allons essayer de nous astreindre est de ne pas générer inutilement de SPOF.
Ceci signifie que la stack Docker doit-être à même de fonctionner lorsque le pipeline de logs est defectueux.
Donc avant d'être poussé vers l'aggrégateur, les logs normalisés seront conservés sur les VMs et régulièrement effacés par un logrotate.
Récupérer les logs de ses containers
La première difficulté à laquelle nous allons être confronté, est de pouvoir récupérer les logs qui sont générés par les applications encapsulées dans les containers.
Vector possède une source Docker mais de l'aveu même de la documentation, il est fortement déconseillé de l'utiliser.
Nous allons donc devoir trouver une manière détournée de récupérer ces logs.
Heureusement, Docker nous fourni une série de manières de réaliser cette extraction.
Notre cahier des charges nous impose plusieurs contraintes. Il ne faut pas qu'un défaut dans le système de pipeline de logs n'interdise le fonctionnement de la stack Docker.
Cette difficulté exclut d'emblée tous les systèmes d'envoie de logs par protocole réseau. En effet si le pipeline décède ou est innacessible, les containers ne démarreront pas.
Les éliminés sont donc:
- syslog en réseau
- fluentd
- splunk en réseau
- graylog
- logentries

On peut aussi sortir les drivers spécifiques au GAFAM: AWS et GCP.
ETW étant pour windows, il ne nous aidera pas non plus sur le coup.
Il nous reste les stockages de logs locaux:
- local
- json-file
- journald
Local est trop simple et ne permet pas de gérer les métadata. Et le stockage JSON ne permet pas une recherche efficace en local.
Nous allons donc nous tourner vers un stockage de logs en utilisant journald.
Pour plus d'informations:
- https://guillaume.fenollar.fr/blog/journald-tutoriel-journald-journalctl
- https://www.freedesktop.org/software/systemd/man/journalctl.html
Comme expliqué dans ces ressources, la grande force de journald est de permettre le stockage des méta-données des messages à des fins de filtrages.
Examinons tout d'abord ce que nous fourni le driver de logging journald de Docker.
En plus du message, nous avons accès à plusieurs meta-data, dont:
CONTAINER_IDSYSLOG_IDENTIFIERouCONTAINER_TAGIMAGE_NAMEnon documenté mais présent dans mes expérimentations
Ceci constituera nos logs brutes.
En plus de ces méta-data propres au driver docker. Il existe une série de méta-datas constitutive du protocole journald dont la liste exhaustive est définie dans l'exemple suivant.
Ceux qui vont particulièrement nous intéresser sont:
hosttimestamp__REALTIME_TIMESTAMP, le timestamp en microsecondes
Configurons nos container pour envoyer leur logs vers journald.
version: '3.7'
services:
tomcat:
image: tomcat
logging:
driver: journald
options:
tag: "java"
jetty:
image: jetty
logging:
driver: journald
options:
tag: "java"
js:
image: custom-js
logging:
driver: journald
options:
tag: "js"
Nous rajoutons un tag qui nous permettra de traiter les messages plus facilement. Cette valeur sera définie dans la méta-donnée SYSLOG_IDENTIFIER.
Nous pouvons maintenant commencer la création de notre pipeline 😁
Pour cela crée un fichier docker_logs_pipeline_normalization.toml
[]
= "journald"
= ["docker"]
= "${PWD}/data"
journald_docker_unit sera l'identifiant de notre source. Puis on définit cette source comme étant du type journald.
On filtre par seulement l'unit docker et on défini un dossier qui contiendra le checkpoint de lecture du journal.
Ceci permet de ne pas retraiter plusieurs fois les même logs.
Normaliser les évènements
Nous allons normaliser cet évènement pour le rendre moins spécifique à docker. Ceci nous permettra dans l'avenir de plus facilement gérer d'autres sources.
Pour cela nous allons utiliser notre première transformation.
[]
= ["journald_docker_unit"]
= "remap"
= '''
service_identifier = .IMAGE_NAME+"/"+.CONTAINER_ID ?? "unknown"
. = {
"message" : .message,
"timestamp": .timestamp,
"unix_timestamp" : .__REALTIME_TIMESTAMP,
"hostname" : .host,
"meta" : {
"type" : "docker",
"image" : .IMAGE_NAME,
"container_id" : .CONTAINER_ID,
"log_topology" : .SYSLOG_IDENTIFIER
}
}
.service_identifier = service_identifier
'''
Cette transformation prend un évènement du type:
Et le transforme en un document de ce type:
De cette manière les logs peuvent venir de n'importe quel service on ne conserve, les traces de docker que dans les méta-données de l'évènement.
Router les messages
En fonction du type d'application qui produit le log, nous devons effectuer des traitements différents.
Pour se faire, nous allons diviser le flux de messages en fonction qu'il vienne d'une application Java ou NodeJs.
Nous allons utiliser une autre transformation: le routing.
[]
= "route"
= ["normalized_journald_docker_events"]
[]
= '.meta.log_topology == "js"'
= '.meta.log_topology == "java"'
Cette transformation créé deux flux, un contenant tous les messages qui ont comme identifiant le tag java et un autre avec le tag js.
Extraire les données des messages de logs
Pour le moment nos messages de logs sont trop bruts pour pouvoir être exploités par un système automatisé.
Il faut extraire les informations de celui-ci.
Généralement les bibilothèques de log dans les différents langages de programmation permettent de définir la sévérité des messages (INFO, WARN, ERROR, FATAL) ainsi que la partie de code qui a produit ce log.
Nous allons tenter d'extraire ces données.
Les logs Java
Nous avons deux types de containers; du Jetty et du Tomcat. Chacun d'eux à sa façon propre de gérer ses logs.
Une ligne de log Tomcat ressemblera à:
13-Sep-2021 05:47:49.513 INFO [main] org.apache.coyote.AbstractProtocol.init Initializing ProtocolHandler ["http-nio-8080"]
Alors que Jetty générera plutôt ceci:
2021-09-13 05:47:47.584:INFO:oejs.AbstractConnector:main: Started ServerConnector@41dddee8{HTTP/1.1, (http/1.1)}{0.0.0.0:8080}
Nous allons utiliser une autre transformation remap pour réaliser ce travail. Le VRL propose tout une série de parsers déjà intégrés.
Malheureusement, aucun d'eux n'est adapté aux logs tel que définis par mes containers.
Il faut donc se rabattre sur nos bonne vieilles regexp. 😛
Voici la transformation que je vous propose, il y aurait surement des axes d'améliorations possibles.
[]
= ["split_stream_by_log_topology.java"]
= "remap"
= '''
structured = parse_regex(.message, r'^\d{2}-\w{3}-\d{4}\s(?:\d{2}:){2}\d{2}.\d{3}\s(?P<severity>\w+)\s\[[\w-]+\]\s(?P<path>[^\s]+)\s(?P<message>.*)$') ??
parse_regex(.message, r'^\d{4}-\d{2}-\d{2}\s(?:\d{2}:){2}\d{2}.\d{3}:(?P<severity>\w+):(?P<path>[\w\.-]+):(?P<section>[\w-]+):\s(?P<message>.*)$') ??
{ "message": .message }
.message_extracted = structured.message
.path = structured.path
.severity = "info"
if is_string(.severity) {
.severity = downcase(.severity)
}
'''
Un mot sur la création de la variable structured. Elle est constituée de plusieurs parties.
Si on schématise cela donne:
structured = A ?? B ?? default
A et B sont appelés des fonctions faillibles, cela signifie que lorsque qu'elle échoue une action doit être entreprise.
Il existe plusieurs moyen de gérer la faillibilité d'une fonction.
La première est de la rendre infaillible en ajoutant un !.
structured = A!
Dans ce cas si une erreur survient, le message est abandonné et ne continuera pas dans le pipeline. C'est la manière la plus rapide de gérer les erreurs mais la plus propre. c'est l'équivalant de lever une exception dans le code.
Une deuxième solution est de traiter l'erreur à la manière de Golang en analysant l'erreur retournée.
structured, err = A
if err != null {
# on traite l'erreur
}
Le VRL possède son propre système de codes d'erreur.
La troisième et dernière solution qui est à mon avis la plus propre, est la coalescence, il s'agit d'un opérateur qui permet de chaîner des fonctions faillibles.
structured = A ?? B ?? default
Ici, si A échoue alors on éxécute B et si B échoue alors on prend la valeur de default. default doit absolument être infaillible sinon ça ne compilera pas.
Dans notre cas l'idée est d'essayer de parser le corps du message en supposant qu'il s'agit d'un message Tomcat. Si la regex ne match pas, la fonction parse_regex échoue et l'on passe au parse de message Jetty. Et si ça échoue aussi on créé un document par défaut qui ne contient que le message.
Nous allons utiliser ce système de gestion d'erreurs pour gérer plusieurs types de formats de logs au sein d'une même transformation.
13-Sep-2021 05:47:49.513 INFO [main] org.apache.coyote.AbstractProtocol.init Initializing ProtocolHandler ["http-nio-8080"]
2021-09-13 05:47:47.584:INFO:oejs.AbstractConnector:main: Started ServerConnector@41dddee8{HTTP/1.1, (http/1.1)}{0.0.0.0:8080}
Vont respectivement donner ces valeurs à la variable structured:
On en profite pour normaliser la sévérité du log. Mais on doit prendre quelques précautions. En effet, toutes les lignes ne posséderont pas de sévérité. Or la méthode VRL downcase prend exclusivement des chaîne de caractères comme paramètre d'entrée.
Comme on peut le voir les données sont extraites et normalisées sous une forme commune qui facilite leur traitement ultérieur.
Finalement la sortie finale sera:
Les logs NodeJs
De la même manière que pour les logs venant des containers java. Nous allons utiliser une transformation qui va venir extraire les données venant de nos lignes de logs.
[]
= "remap"
= ["split_stream_by_log_topology.js"]
= '''
structured = parse_regex(.message, r'^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}.\d{3}Z\s\[(?P<path>[\w_/-]+)\]\s(?P<severity>\w+):\s(?P<message>.*)$') ??
{ "message": .message }
.message_extracted = structured.message
.path = structured.path
.severity = "info"
if is_string(.severity) {
.severity = downcase(.severity)
}
'''
Pour rappel un log NodeJs de notre application ressemble à:
2021-09-14T06:52:52.480Z [main] info: Application started
Après transformation:
On a ici aussi fait en sorte que les messages aient des topologies identiques. Nous pourrons désormais traiter de manière unique les logs venant du Java et du NodeJS.
Exporter nos logs normalisés vers l'aggrégateur
Jusqu'à présent nous avons normalisé nos logs mais il reste toujours sur notre machine, nous ne résolvons toujours pas le souci de la centralisation des logs.
Nous allons devoir les exporter vers une destination qui se chargera de leur aggrégation.
Et quoi de mieux que d'envoyer vers un autre pipeline Vector! 😀
Ce choix technique nous permettra de pouvoir réaliser tous les post-traitements voulus. Au contraire de les envoyer directement dans un store comme Elasticsearch ou autre.
Pour cela nous allons utiliser un sink Vector.
Sur la machine contenant la stack docker dont on veut extraire les logs,
on rajoute au pipeline:
[]
= "vector"
= ["parse_message_body_java", "parse_message_body_js"]
= "192.168.9.63:9000"
= "1"
Nous allons cette fois-ci prendre 2 flux en entrée, les messages java et NodeJs extraits et normalisés.
En suite on définit l'addresse de notre instance Vector qui sert d'aggrégateur.
Et c'est tout 😁
Vous pouvez désormais envoyer d'une multitude de noeuds vos logs vers un point central.
Définition du pipeline d'aggrégation
Je vous ai dit que nous allions pousser nos logs vers un autre Vector, lui aussi va avoir besoin d'une configuration.
Créons un fichier aggregator.toml
Tout d'abord la source, une source Vector.
[]
= "vector"
= "0.0.0.0:9000"
= "1"
On écoute sur le port 9000.
Étant donné qu'il s'agit juste de démontrer la faisabilité de la centralisation des logs. Nous allons nous contenter d'une simple sortie fichier. Mais il est bien évidemment possible de faire des choses bien plus complexes, incluant des transformations, des aggrégations et des réductions.
Déclarons donc un sink File.
[]
= ["vector_server"]
= "file"
= "ndjson"
= "./logs/by-host/{{ hostname }}/{{ meta.type }}/json/{{ service_identifier }}/%Y-%m-%d.log"
Nous allons définir un autre sinks, qui nous permettra de lire les logs comme si nous étions dans le stdout/err de l'application.
[]
= ["vector_server"]
= "file"
= "text"
= "./logs/by-host/{{ hostname }}/{{ meta.type }}/text/{{ service_identifier }}/%Y-%m-%d.log"
Lift-off ! 🚀
On a tous nos pipelines! Il est temps de lancer tout ça! 😁
Tout d'abord, installez Vector sur tout vos serveurs, aussi bien ceux qui contiendront les stack dont on veut récupérer les logs que le noeud d'aggrégation.
Copiez y respectivement les fichiers docker_logs_pipeline_normalization.toml et aggregator.toml.
Lancez dans l'ordre
Puis
vector --config docker_logs_pipeline_normalization.toml
Si vous faites l'inverse vous aurez une erreur car le pipeline d'extraction de logs essaie de se connecter au port 9000. Or celui n'est pas encore en écoute.
Ceci me permet de vous prévenir que si votre réseau n'est pas suffisamment stable, il se peut que des problèmes de connectivité apparaissent et des erreurs surviennent.
Ceci avait motivé notre choix dès le début de confier la gestion des logs en premier lieu à journald puis à Vector. Si Vector tombe les logs ne seront pas perdu et la stack Docker continuera de tourner comme si de rien n'était.
D'une manière général, un couplage faible entre systèmes est toujours a préféré lorsque que les contraintes le permettent. Ici par exemple nous avons perdu en réactivité mais gagné en résillience. Tout est une histoire de balance entre performance et sécurité, c'est un peu la définition de l'ingéniérie. 😁
Maintenant si vous lancez vos docker-compose up, vous devriez voir les fichiers de logs apparaître sur votre noeud d'aggrégation.
On résume
Il est temps de faire le bilan.
On possède deux pipelines:
docker_logs_pipeline_normalization.toml
[]
= "journald"
= ["docker"]
= "${PWD}/data"
[]
= ["journald_docker_unit"]
= "remap"
= '''
service_identifier = .IMAGE_NAME+"/"+.CONTAINER_ID ?? "unknown"
. = {
"message" : .message,
"timestamp": .timestamp,
"unix_timestamp" : .__REALTIME_TIMESTAMP,
"hostname" : .host,
"meta" : {
"type" : "docker",
"image" : .IMAGE_NAME,
"container_id" : .CONTAINER_ID,
"log_topology" : .SYSLOG_IDENTIFIER
}
}
.service_identifier = service_identifier
'''
[]
= "route"
= ["normalized_journald_docker_events"]
[]
= '.meta.log_topology == "js"'
= '.meta.log_topology == "java"'
[]
= ["split_stream_by_log_topology.java"]
= "remap"
= '''
structured = parse_regex(.message, r'^\d{2}-\w{3}-\d{4}\s(?:\d{2}:){2}\d{2}.\d{3}\s(?P<severity>\w+)\s\[[\w-]+\]\s(?P<path>[^\s]+)\s(?P<message>.*)$') ??
parse_regex(.message, r'^\d{4}-\d{2}-\d{2}\s(?:\d{2}:){2}\d{2}.\d{3}:(?P<severity>\w+):(?P<path>[\w\.-]+):(?P<section>[\w-]+):\s(?P<message>.*)$') ??
{ "message": .message }
.message_extracted = structured.message
.path = structured.path
.severity = "info"
if is_string(.severity) {
.severity = downcase(.severity)
}
'''
[]
= "remap"
= ["split_stream_by_log_topology.js"]
= '''
structured = parse_regex(.message, r'^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}.\d{3}Z\s\[(?P<path>[\w_/-]+)\]\s(?P<severity>\w+):\s(?P<message>.*)$') ??
{ "message": .message }
.message_extracted = structured.message
.path = structured.path
.severity = "info"
if is_string(.severity) {
.severity = downcase(.severity)
}
'''
[]
= "vector"
= ["parse_message_body_java", "parse_message_body_js"]
= "192.168.9.63:9000"
= "1"
Et
aggregator.toml
[]
= "vector"
= "0.0.0.0:9000"
= "1"
[]
= ["vector_server"]
= "file"
= "ndjson"
= "./logs/by-host/{{ hostname }}/{{ meta.type }}/json/{{ meta.type }}/{{ service_identifier }}/%Y-%m-%d.log"
[]
= ["vector_server"]
= "file"
= "text"
= "./logs/by-host/{{ hostname }}/{{ meta.type }}/text/{{ service_identifier }}/%Y-%m-%d.log"
L'intégralité des sources peut-être retrouvé sur le projet.
Petits dessins parce que c'est cool les dessins. 😉
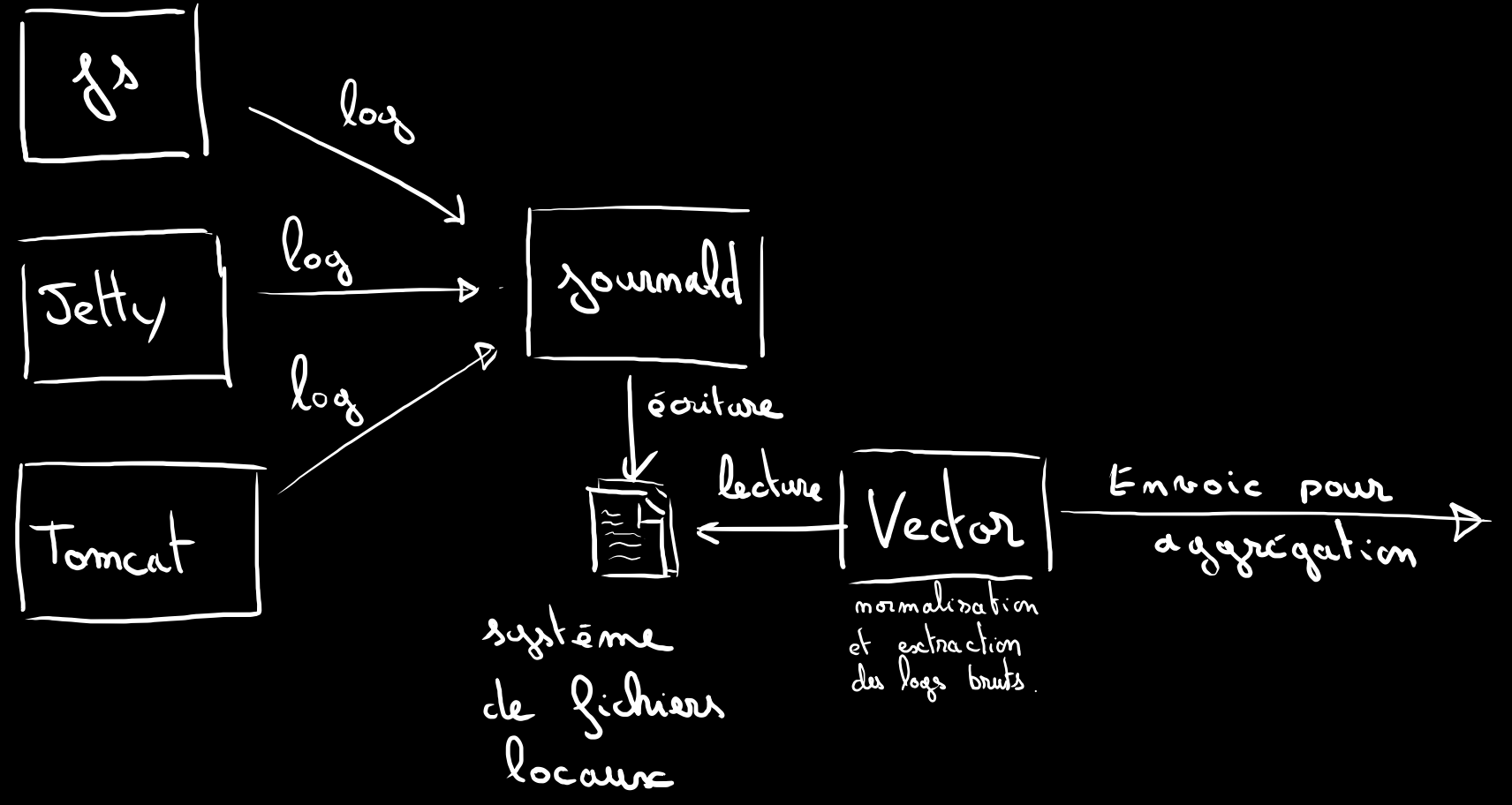
Voici ce qui se passe schématiquement sur un noeud.
Les applications crachent leurs logs sur journald.
Vector vient lire journald pour en extraire les lignes de logs.
Normalise et extrait les informations pertinentes puis retransmet par réseau à un autre Vector.
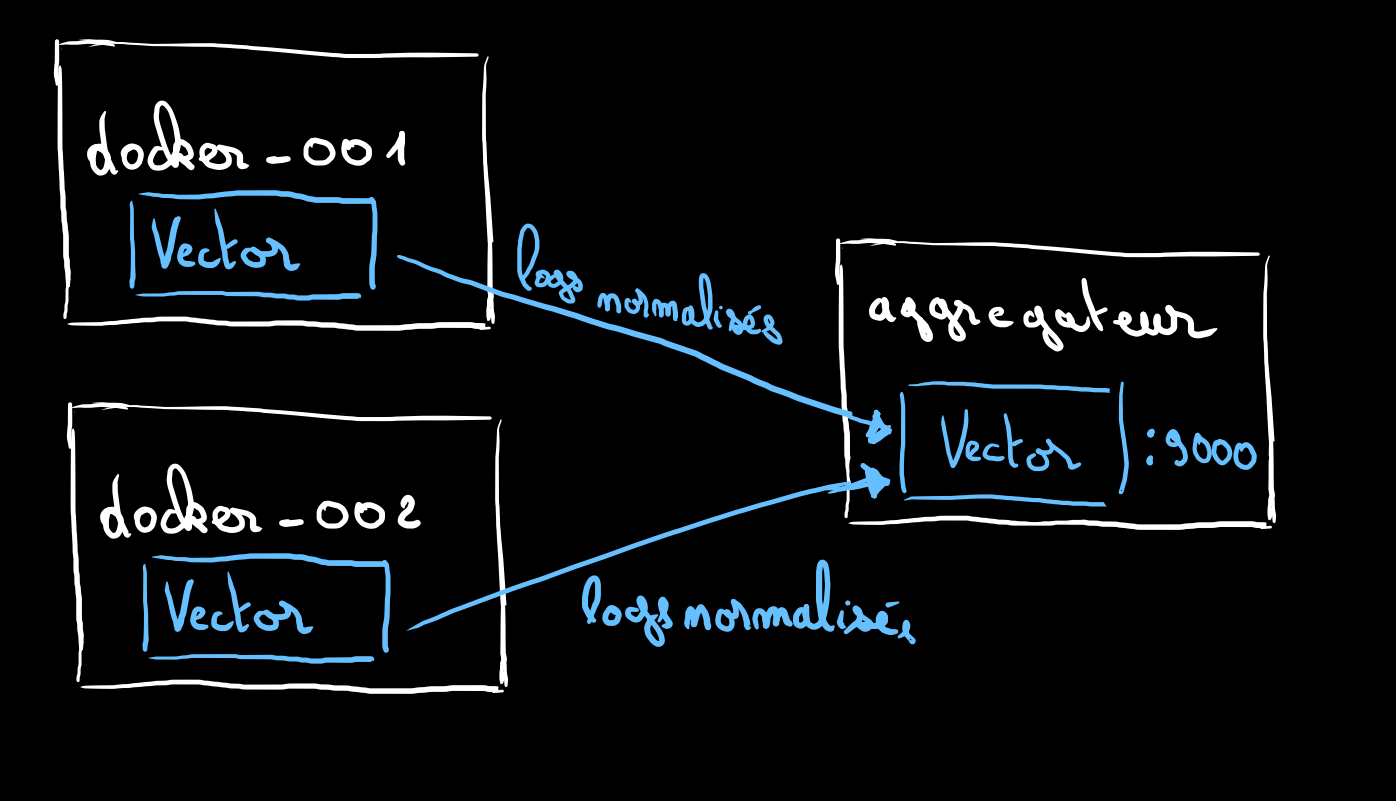 .
.
Les logs normalisés des différents noeuds transitent par réseau vers notre aggrégateur.
Nous pouvous tout à fait créer des docker-003, 004, ou 100. La topologie restera la même.
Tant que votre réseau tient le traffic et que votre noeud d'aggrégation aussi il n'y aura pas de souci.
Si votre trafic devient trop important, il faudra peut-être penser à une topologie différente qui fera apparaitre un broker de messages qui tiendra lieu de buffer pour gérer la back-pressure de votre traffic de logs.
Conclusion
Cet article est le premier d'une série sur l'Observabilité, une discipline de l'informatique qui se base sur plusieurs concepts dont la gestion des logs.
Nous avons fait que la moitié du chemin concernant l'étude de nos logs, nous les avons normalisés et centralisés mais pas encore traités et rendus intelligents.
Dans la suite des articles, nous tenteront de définir une logique de recherche de logs permettant la détection et la résolution de bugs.
Je n'ai pas encore décidé de la technologie qui sera mis en place mais peut-être un couple Elasticsearch-Kibana ou des produits plus exotiques comme Loki.
J'espère que cette petite présentation des bases de la réalisation d'un système de pipeline de logs vous a plu et l'on se dit à plus tard pour la suite de nos aventures dans le monde merveilleux normalisé et automatisé de l'Observabilité! 🤩
Merci de m'avoir lu! 💖
Ce travail est sous licence CC BY-NC-SA 4.0.