Introduction à la Virtualisation (Partie 1)
Bonjour à toutes et tous 🙂
Bienvenue dans un article encore une fois bien trop long.
Ce devait être l'introduction d'un article sur la création d'image disque dans un pipeline Gitlab CI, je vais pas vous le cacher, ça a un peu dérapé... 🤭
Je vous propose un tour d'horizon des concepts de la virtualisation que j'utiliserai par la suite dans l'article prévu au début.
Mais comme je sais pas m'arrêter et que j'aime que n'importe qui puisse comprendre quelque soit son niveau de départ, il y aura de l'extra 😁
Avant de commencer.
D'abord, un grand merci à Samuel Ortez, Julien Durillon et Pierre-Antoine Grégoire pour la présentation que je vais tenter de résumer et compléter sans déformer dans les lignes qui vont suivre.
Prenez une inspiration, on descends ! 🤿
Code Machine et Hardware
Oui, comme ça direct. ^^
Ne vous inquietez pas je vais vous guider.
Code Machine
Premièrement ce qu'il faut savoir, c'est qu'un ordinateur est extrêment idiot, il ne parle ni français ni anglais, il ne connais qu'un langage, le Code Machine, basiquement des 0 et des 1.
Impossible de lui donner à manger du C, du Java ou du JavaScript, il n'est pas fait pour ça.
Dans un ordinateur, ce qui est responsable de comprendre et d'exécuter du code se nomme un CPU (Central Processing Unit).
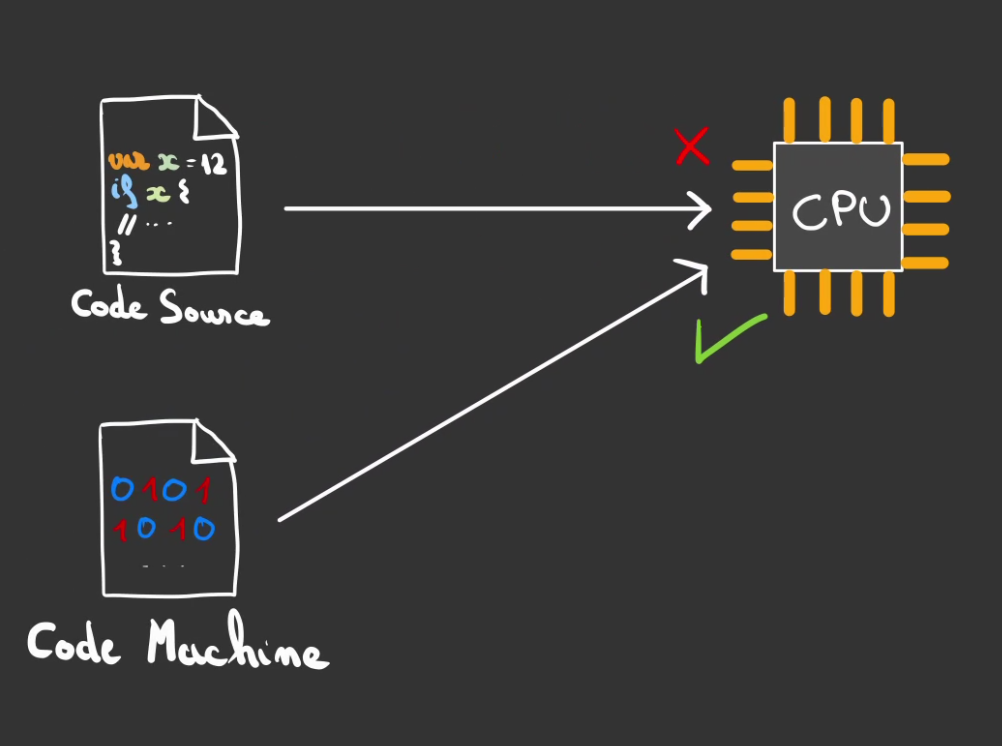
De même, un CPU parle un Code Machine bien spécifique et ne saura comprendre un Code Machine différent.
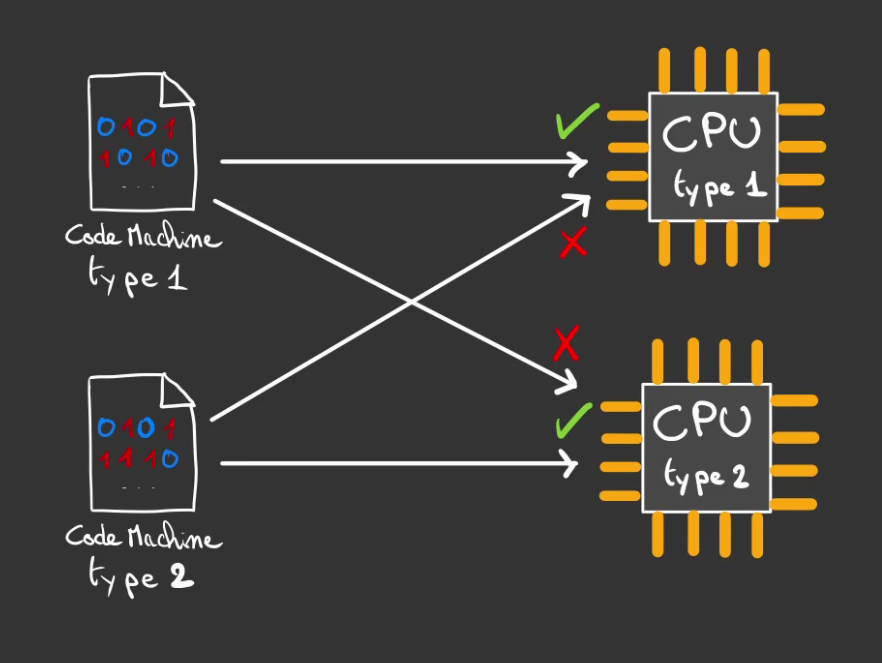
J'ai fait abstraction de l'interprétation et de la semi-compilation, plus de détail dans cet article
CPU
Voyons un peu plus en détail les différents composants d'un ordinateur.
Le premier, nous l'avons déjà nommé est le CPU.
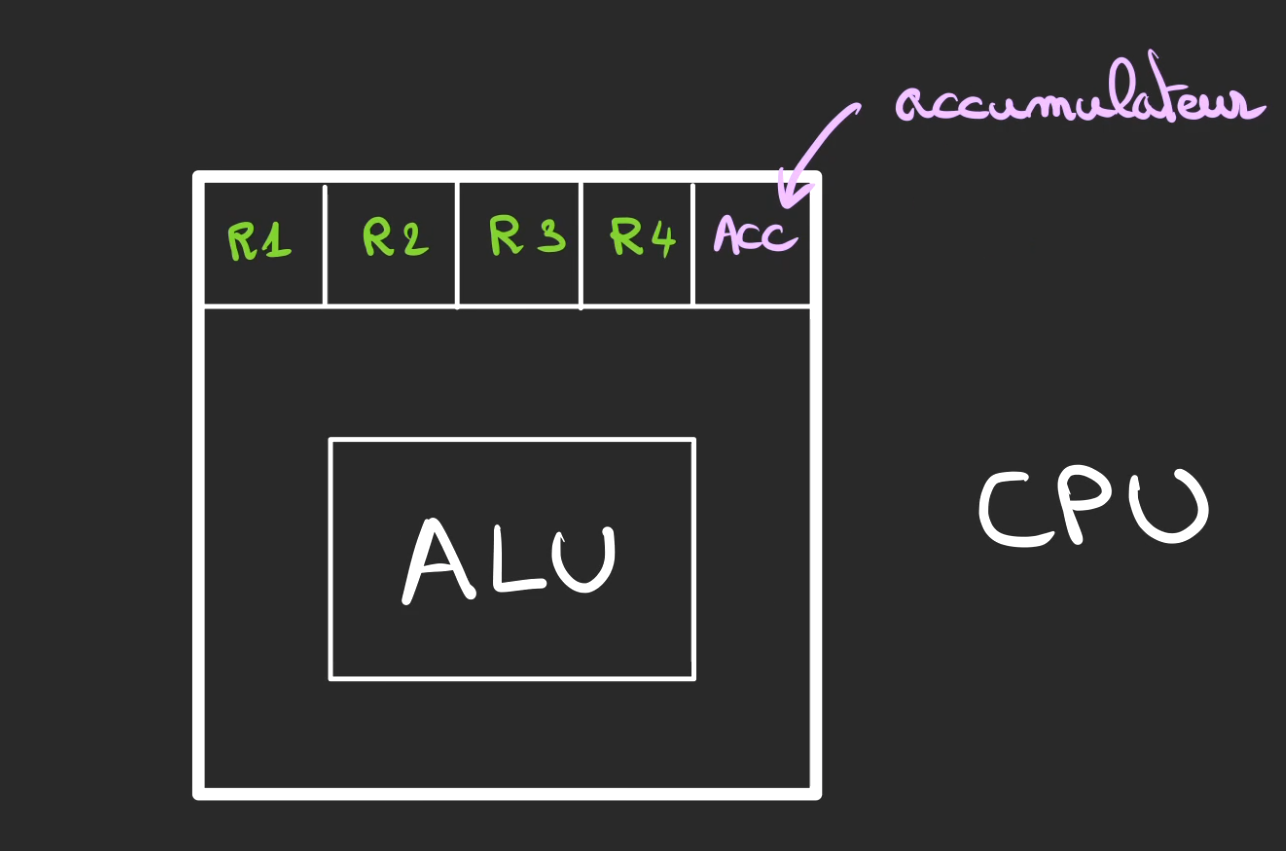
Il est composé de deux parties principales (je fais abstraction de ce qui nous intéresse pas ).
- Les Registres : R1, R2, ... et Acc
- L' Arithmetic Logic Unit ou ALU ou UAL en français (Unité Arithmétique et Logique)
Les Registres sont des petites mémoires qui ne permettent (en simplifiant) que de stocker une valeur.
Plus d'infos dans cet article
Ils sont en quelques sortes l'établi utiliser par un artisan pour poser ses planches avant la découpe.
Dans ces registres, un est un peu spécial et se nomme l'Accumulateur, ici je le représente par un Acc.
Si les registres sont l'établi, alors l'ALU sont les outils de l'artisan, son travail est de manipuler les registres pour faire des opérations mathématique ou des transferts de données.
RAM
Mais je l'ai dit plus haut, un registre ne contient qu'une seule valeur, ici on a 5 registres, donc on peut stocker 5 valeurs, nos programmes vont être courts 🤭
L'idée est alors de stocker ailleurs la donnée, la place sur le CPU étant limitée, on vient stocker dans un autre composant appelé la RAM.
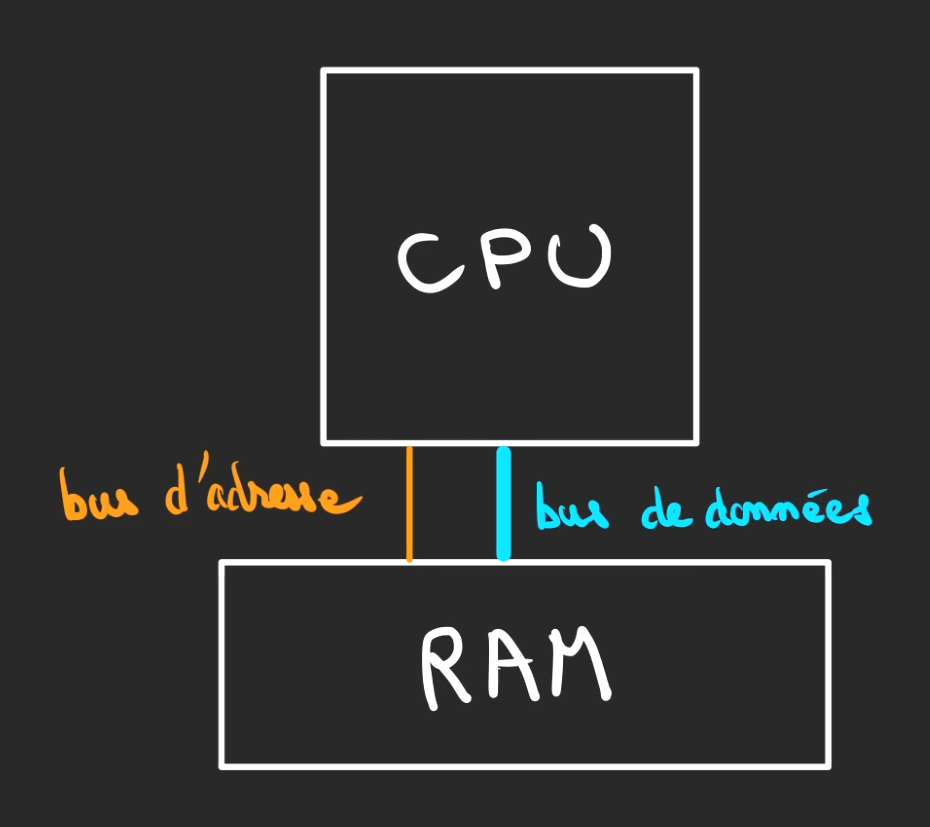
Le CPU communique avec la RAM au moyen de deux canaux :
- bus d'adresse : défini ce que le CPU veut atteindre
- bus de données : transfert les données dans le sens CPU -> RAM ou RAM -> CPU
Ici je fais abstraction du cache CPU, d'ailleurs c'est en partie pour ça que les Apple M1 sont très rapides, ils ont beaucoup de cache ^^
J'assimile toute mémoire de travail à de la RAM pour plus de facilité.
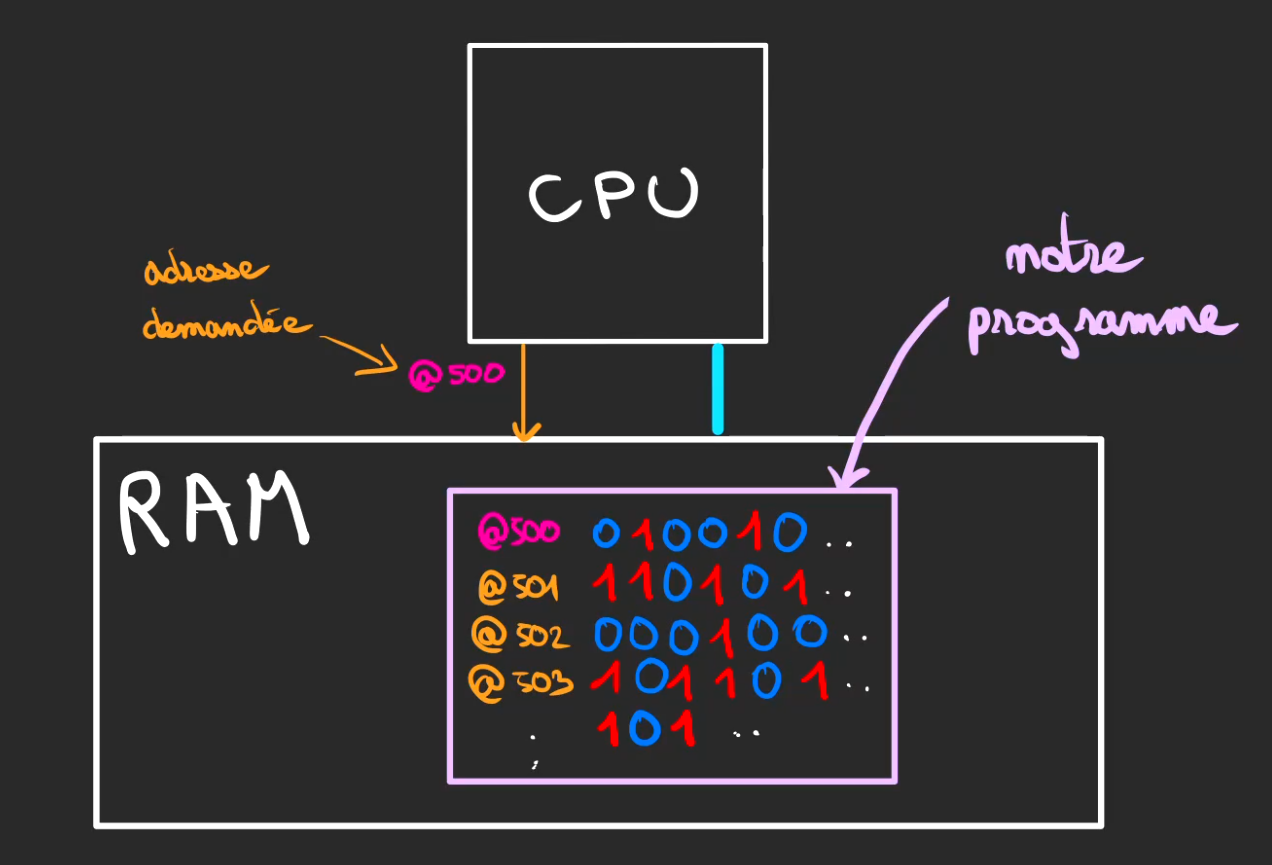
On peut globalement y stocker n'importe quoi, tant que ce sont des 0 et des 1. Et ça tombe bien notre programme est du Code Machine pouvant se représenter par du binaire.
Chaque donnée est adressée par un nombre.
Dans cet exemple le CPU demande le contenu de l'adresse @500 à la RAM.
Chouette on peut stocker plus de 5 valeurs. 🙂
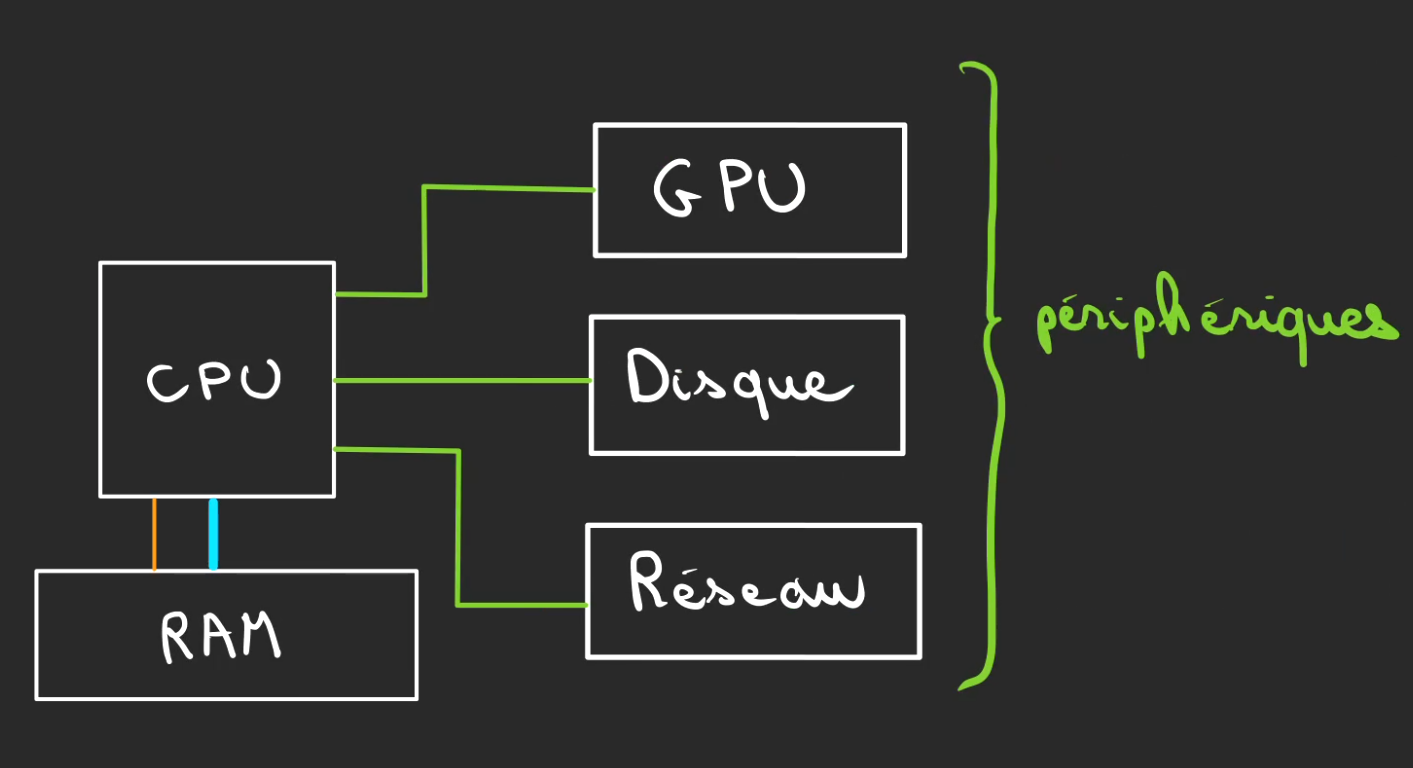
Périphériques
Mais le CPU à part faire des calculs, il ne sert pas à grand chose, il faut au moins une imprimante comme dans l'ancien temps pour lire le résultat.

C'est pour cela que l'on a inventé les Périphériques. Ceux-ci peuvent être n'importe quoi: un disque dur, la carte graphique, la carte réseau, l'imprimante qui marche jamais quand vous en avez besoin, etc ...
Assembleur et Instructions
C'est bien beau tout ça mais le binaire et l'esprit humain cela fait 2 (sans mauvais jeu de mots ^^'), c'est pour cela que l'on ne manipule pas directement les 0 et les 1.
On le remplace par une sorte de langage qui est transcriptible en 0 et 1.
Assembleur
Ce langage se nomme de l'Assembleur ou ASM
Il existe autant d'assembleur qu'il y a de de Code Machine différents et plusieurs Assembleur différents peuvent mener au même Code Machine.
Cet assembleur est la première abstraction créé par l'Humain pour l'aider à parler le Machine sans devenir fou!
Un exemple d'assembleur (rassurez-vous on détaille après 🙂).
LOD @5
Va être transcrit en utilisant le Code Machine de notre CPU fictif en 0101010
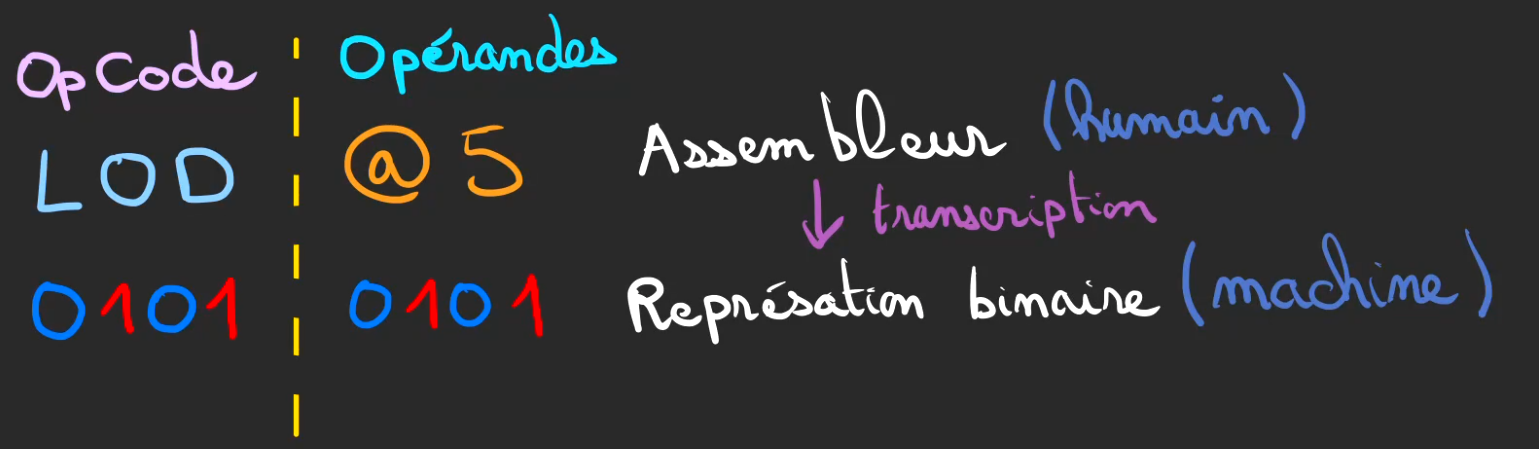
Notre ligne de programme en Assembleur peut alors se décomposer en deux parties
- OpCode : ce que l'on doit faire
- Opérandes : avec quoi ?
Un autre exemple d'instruction
STD @5
Qui devient

On voit ici que le OpCode change la transcription binaire, il aurait été de même si l'opérande avait également évolué.
La langue du Code Machine est appelé un set d'instructions.
Instructions
Nous avons l'alphabet attaquons-nous aux mots.
La langue du CPU est décomposé en instructions, voici celle de notre CPU fictif.
| OpCode | Operande 1 | Operande 2 | Signification |
|---|---|---|---|
| MOV | RX | D | Déplace la valeur D vers le registre RX, D peut être un autre registre |
| LOD | RX | @A | Charge la valeur à l'adresse @A depuis la RAM vers le registre RX |
| STD | RX | @A | Stocke la valeur contenu dans le registre RX à l'adresse @A de la RAM |
| ADD | X | Ajoute la valeur X à Acc, X peut être un registre | |
| OUT | X | #VX | Ecrire X sur le périphérique #VX |
| JMP | @A | Sauter à l'instruction à l'adresse @A | |
| JNZ | RX | @A | Sauter à l'instruction à l'adresse @A, si la valeur dans le registre RX n'est pas 0 |
| HLT | Stop le CPU et met fin au programme |
Maintenant que nous avons des mots, nous allons pouvoir faire des phrases.
Exécution d'un programme
Ces phrases vont être notre programme.
Je vous propose celui-ci.
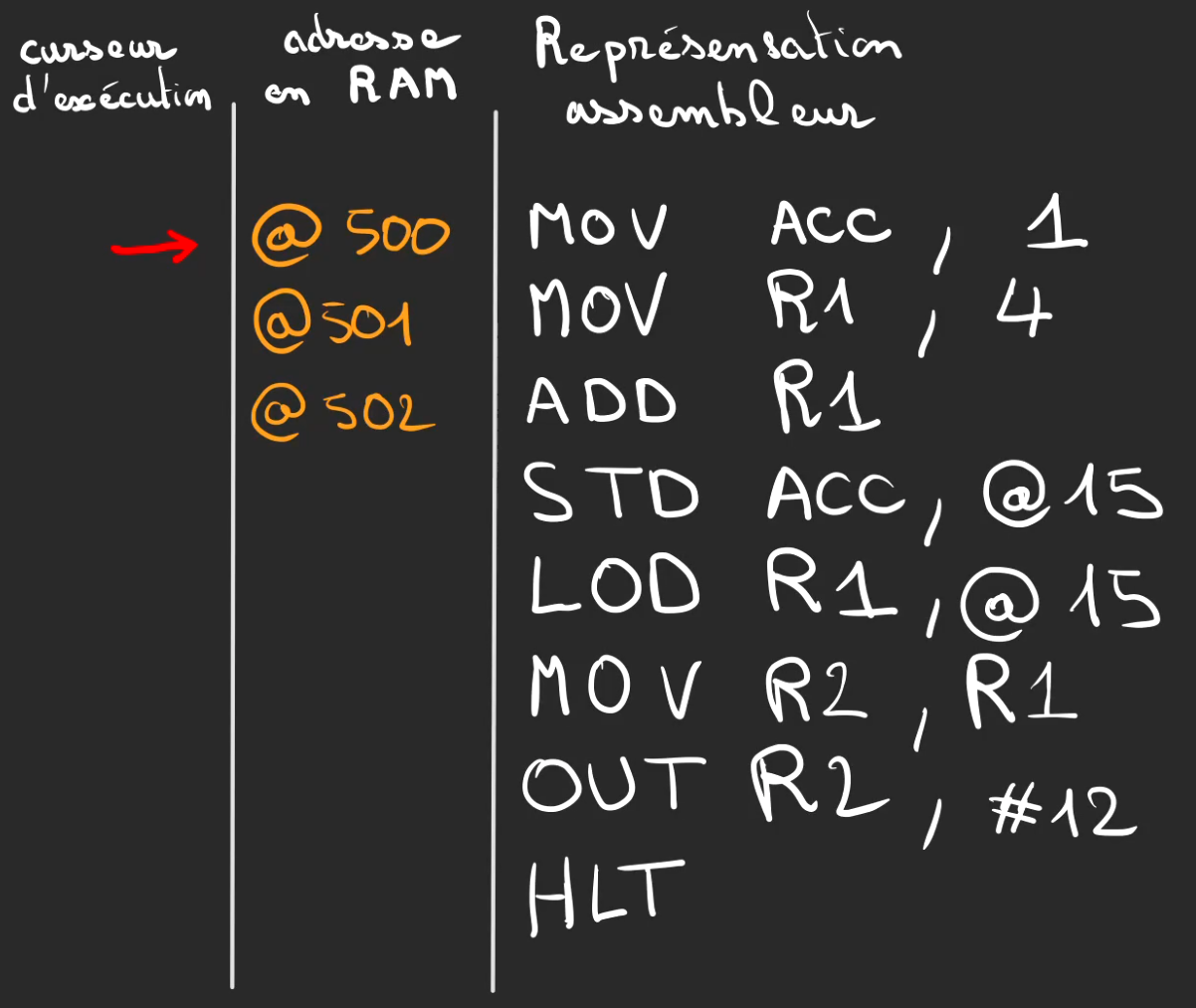
Chaque ligne du programme est stockée à une adresse, ici on débute à l'adresse @500, biensûr c'est la représentation binaire qui est stockée et non l'assembleur.
Nous avons donc 3 questions à résoudre :
- La ligne du programme est dans la RAM, comment la transmettre au CPU ?
- Une fois dans le CPU, comment fait-il pour comprendre la ligne ?
- Que se passe-t-il à l'exécution de la ligne ?
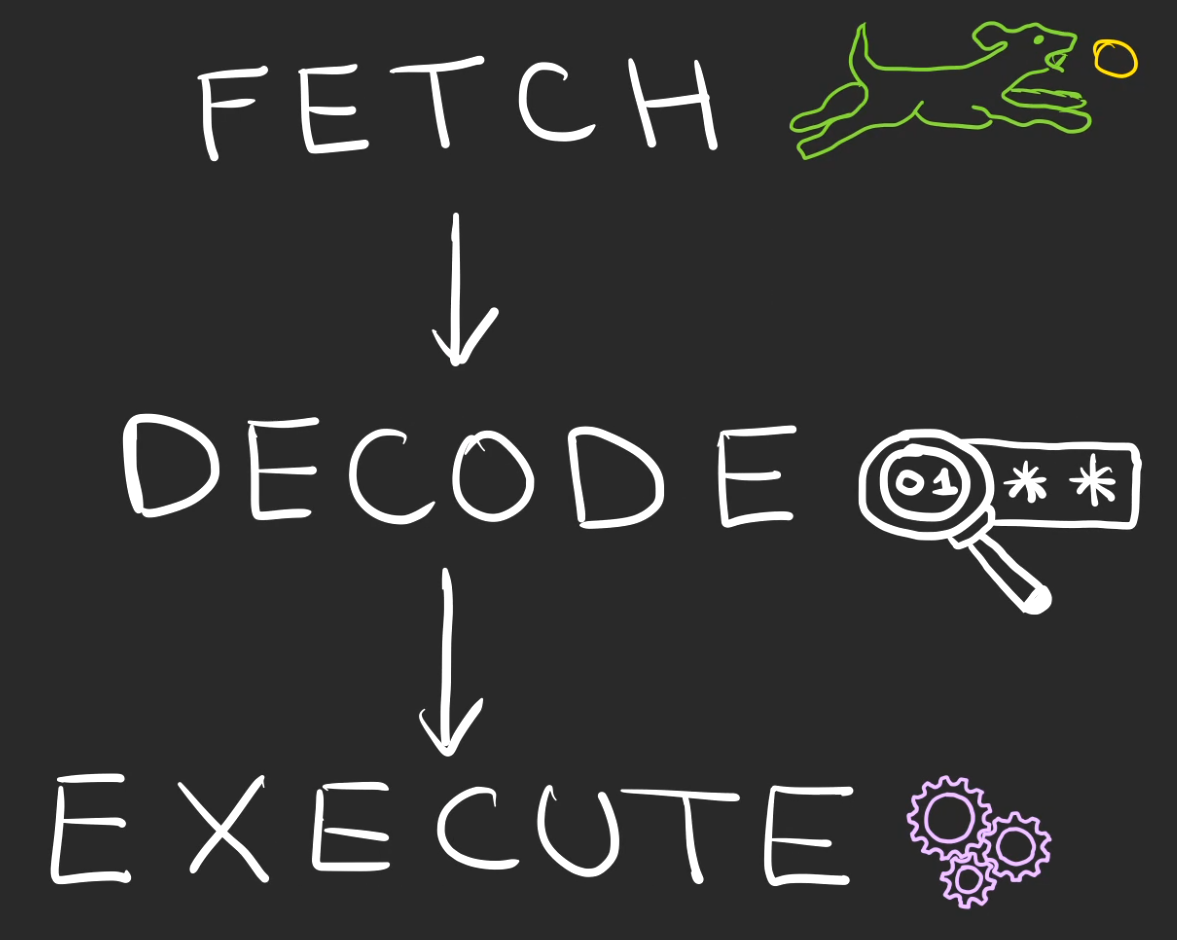
Pour cela, nous allons introduire 3 notions:
- Fetch
- Decode
- Exec
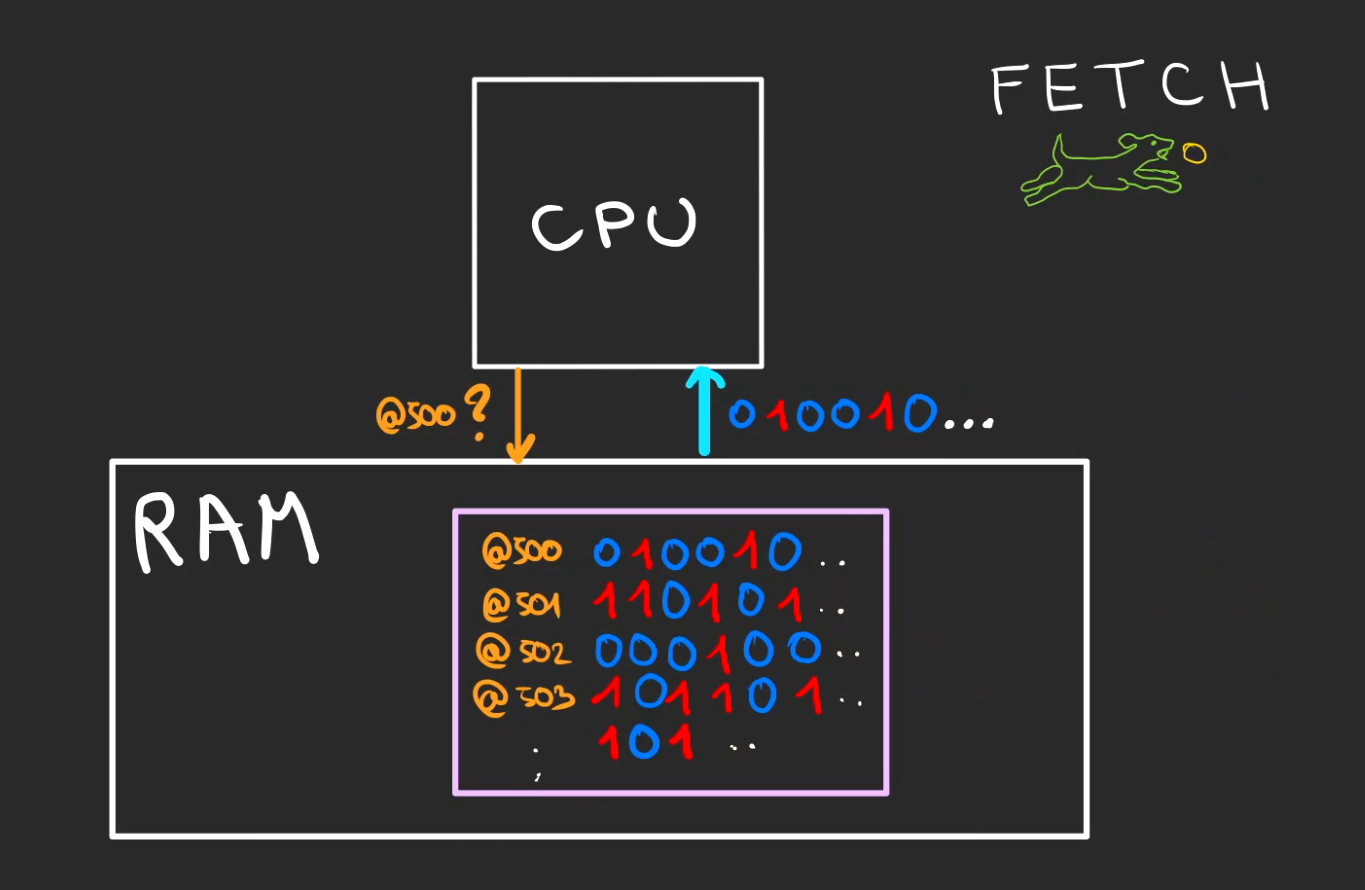
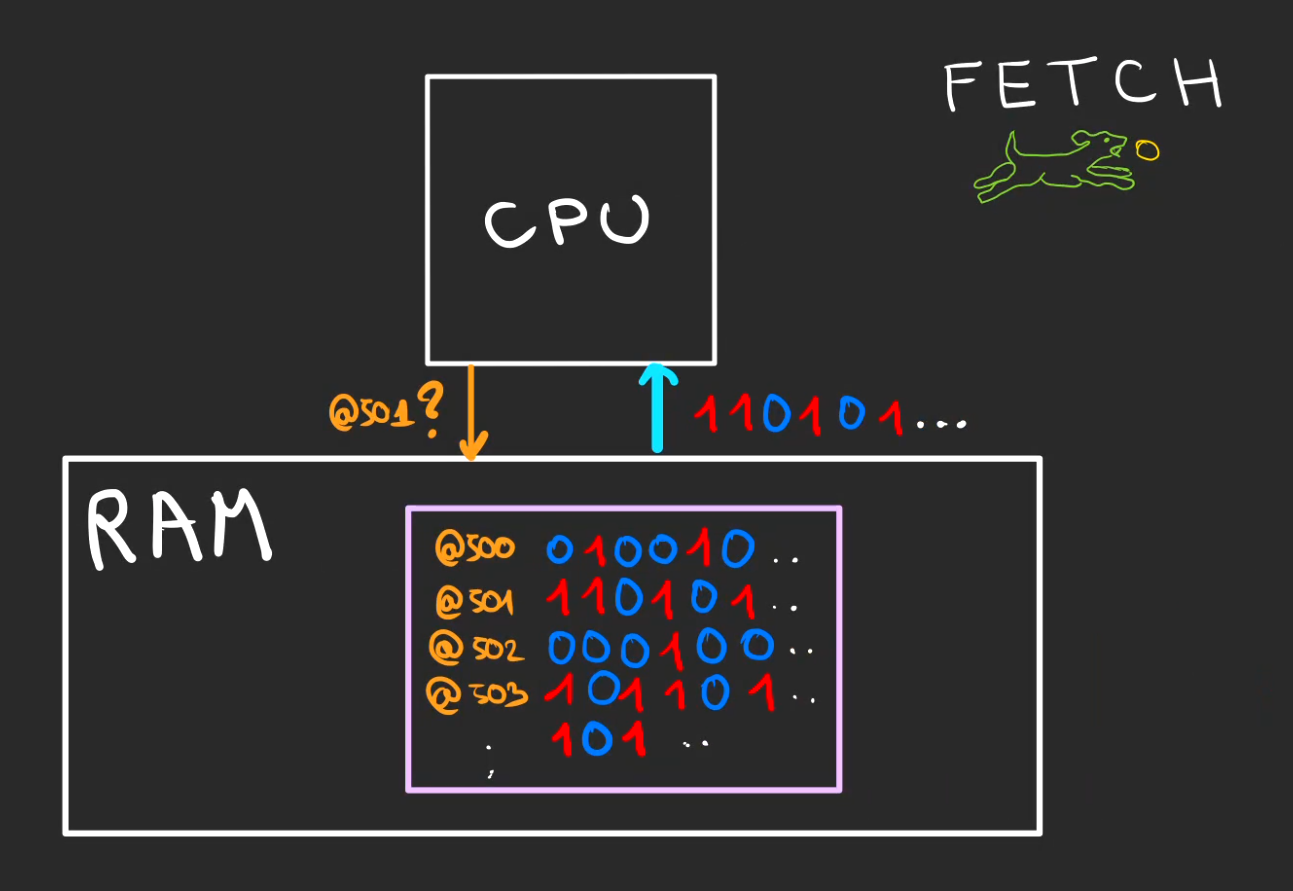
Notre curseur d'exécution est à l'adresse @500, ce qui veut dire que la ligne d'instruction à rechercher dans la RAM est à l'adresse @500.
Le CPU demande donc le contenu de l'adresse @500 à la RAM au travers du bus d'adresses, la RAM lui renvoie ce contenu.
Cette opération est appelée le Fetch.
Une fois le contenu binaire de l'adresse @500 en main, celui-ci est décodé.
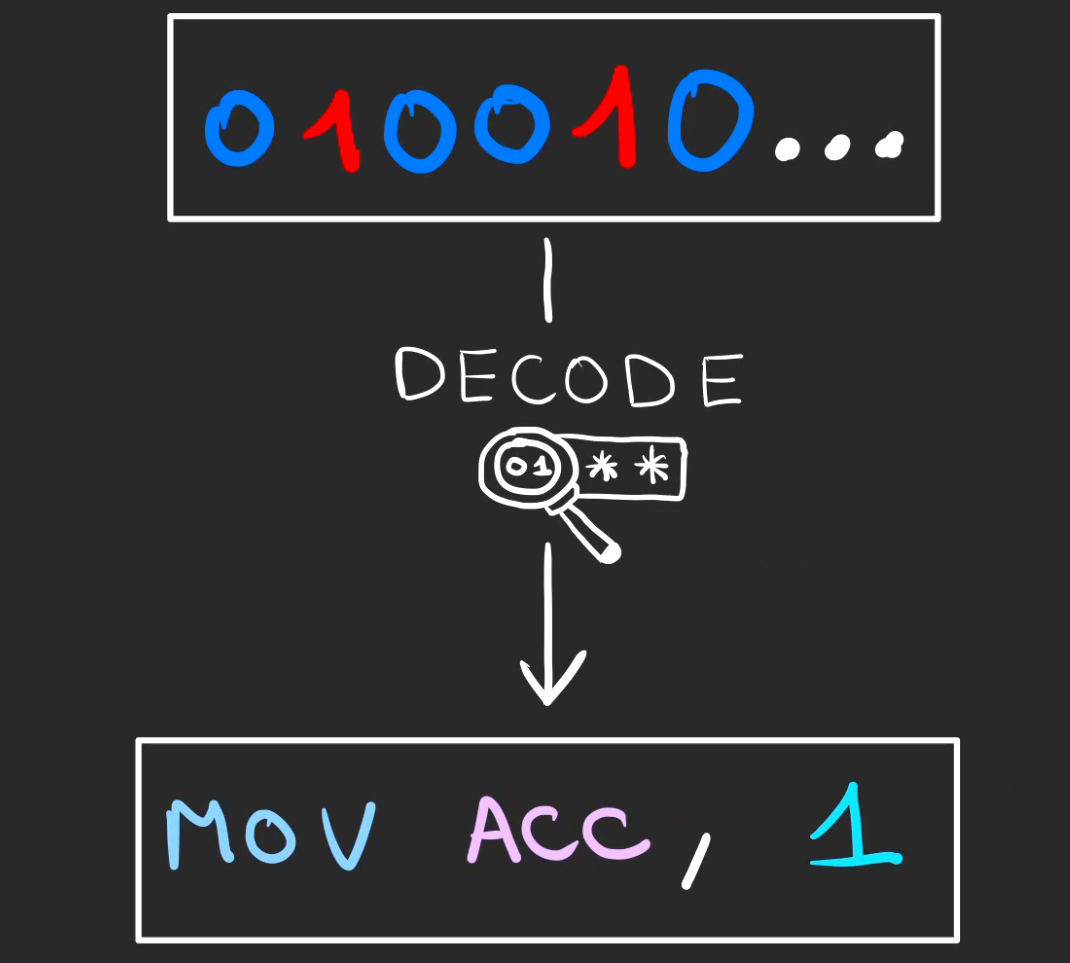
Ici le décodage nous annonce que l'opération à réaliser de mettre la valeur 1 dans le registre Acc.
MOV ACC, 1
Maintenant que le CPU, sait quoi faire, il va pouvoir l'exécuter.
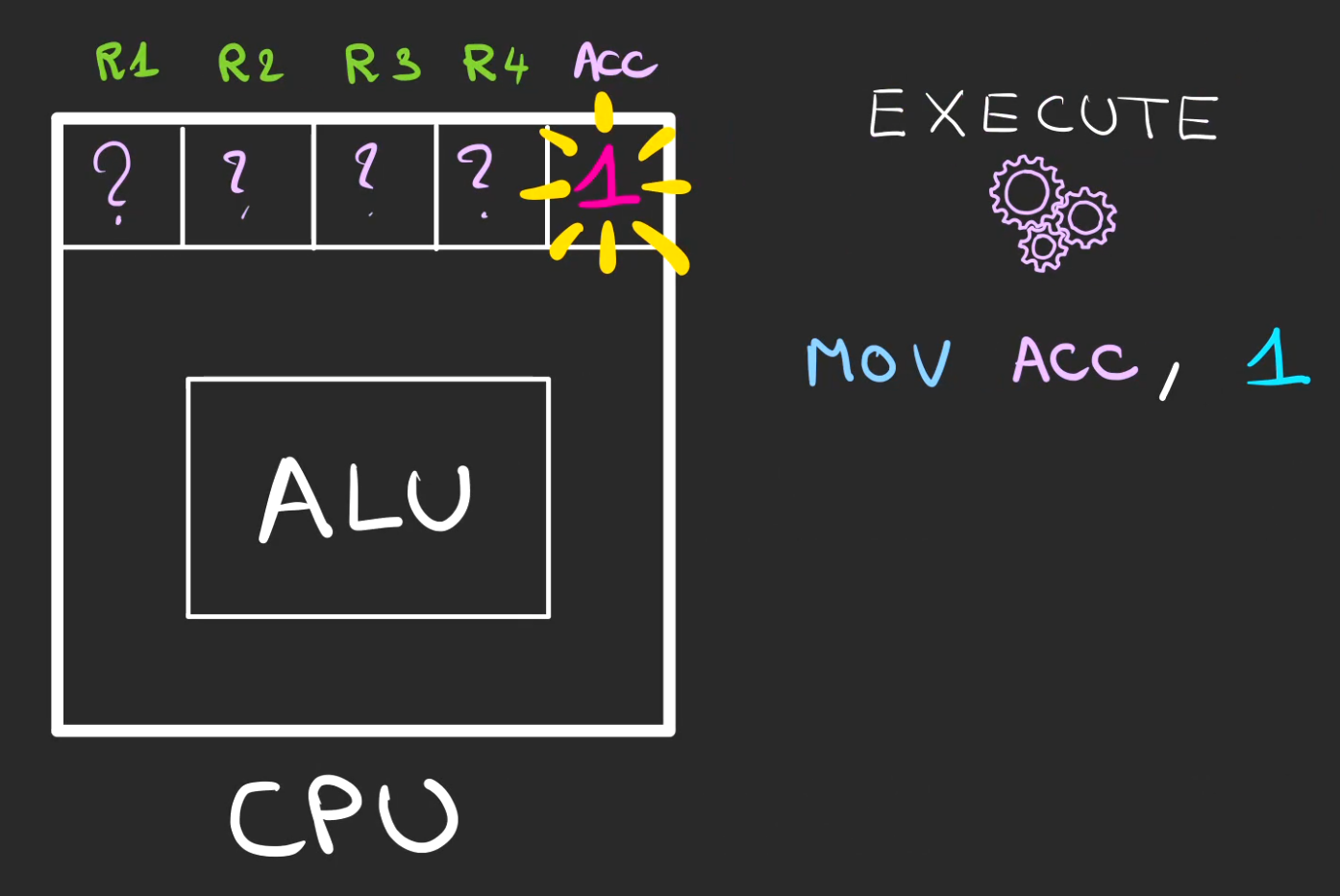
Dans le cas présent, mettre un 1 dans le registre Acc.
On passe alors à la ligne suivante en incrémentant le curseur d'exécution.
Et du coup, fetch de l'adresse @501 cette fois-ci.
Décodage
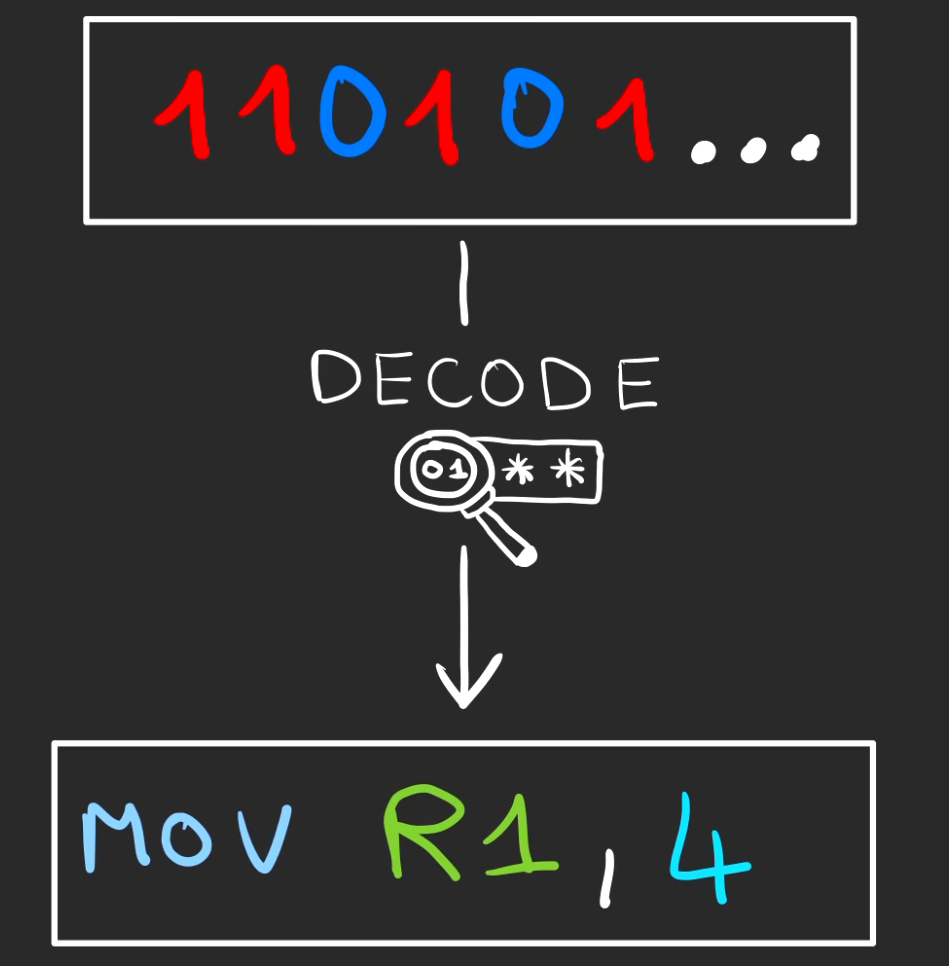
en
MOV R1, 4
Puis exécution
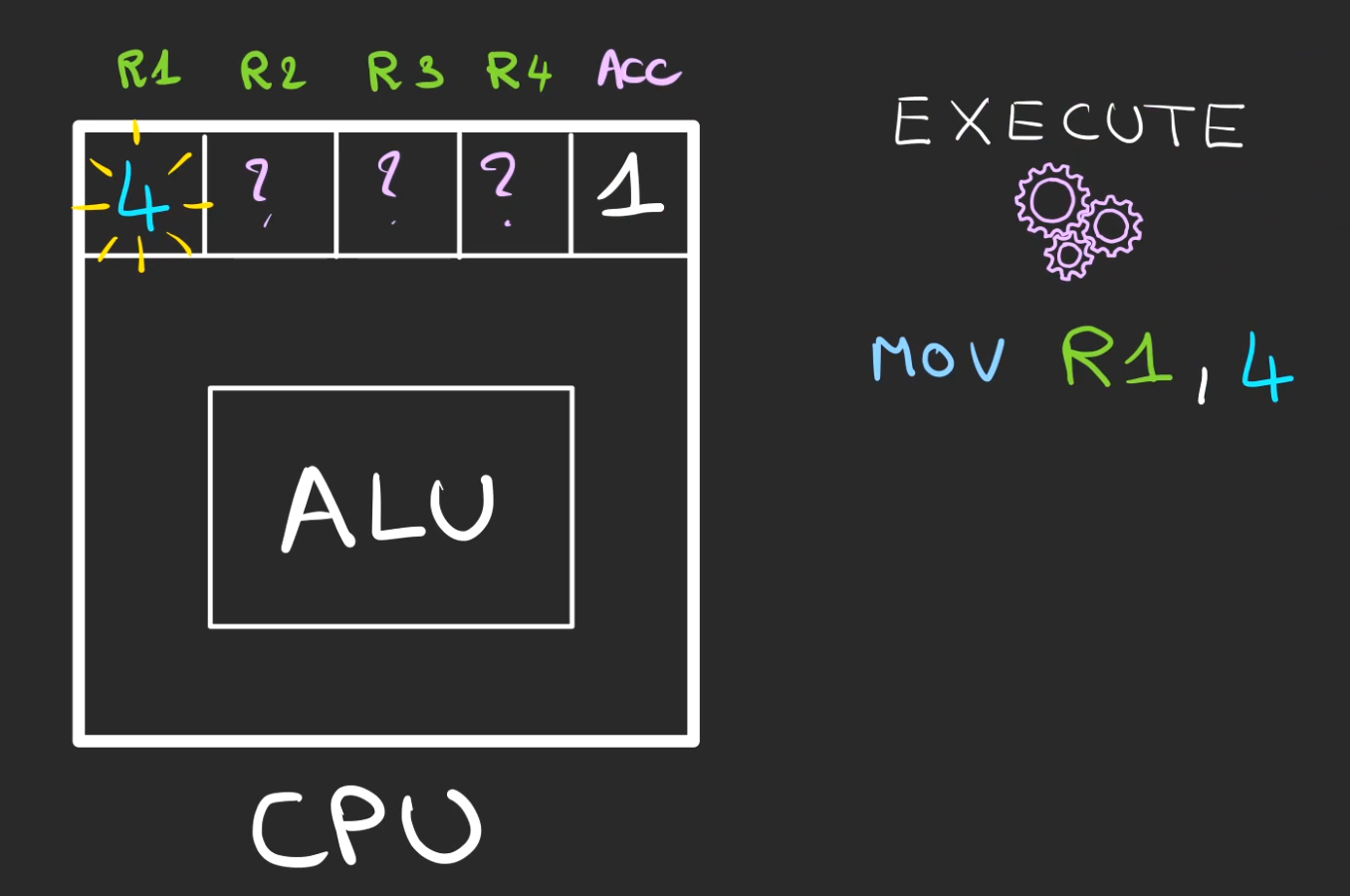
Nous avons maintenant un 1 dans l'accumulateur et un 4 dans le registre R1.
On déroule le programme.
Celui-ci nous demande d'additionner le contenu de l'accumulateur avec le contenu du registre R1 et de mettre le résultat dans l'accumulateur.
ADD R1
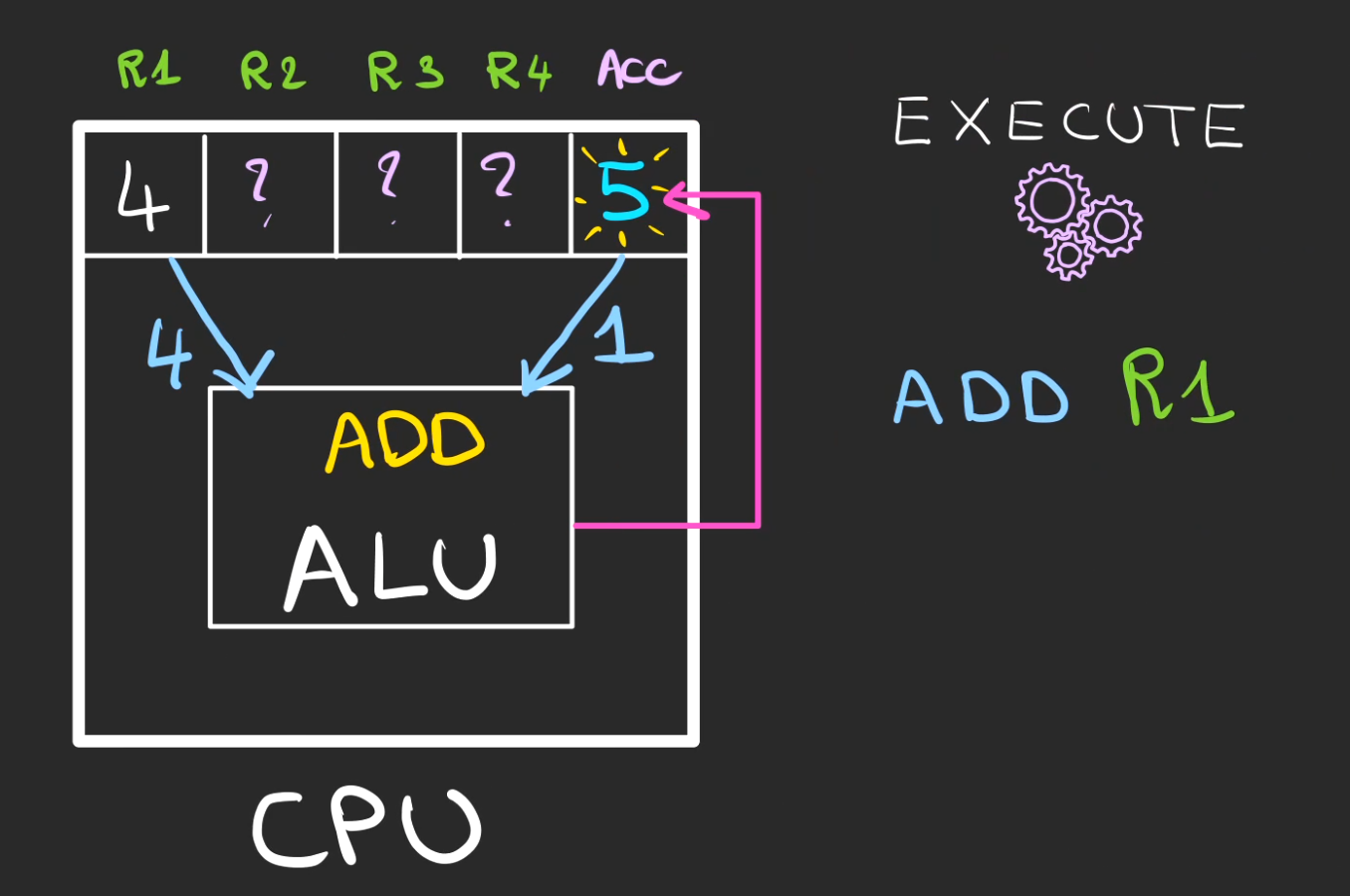
Nous avons maintenant 5 dans l'accumulateur.
On continue.
Plus compliqué, on nous demande de stocker le contenu de l'accumulateur dans la RAM à l'adresse @15.
STD ACC, @15
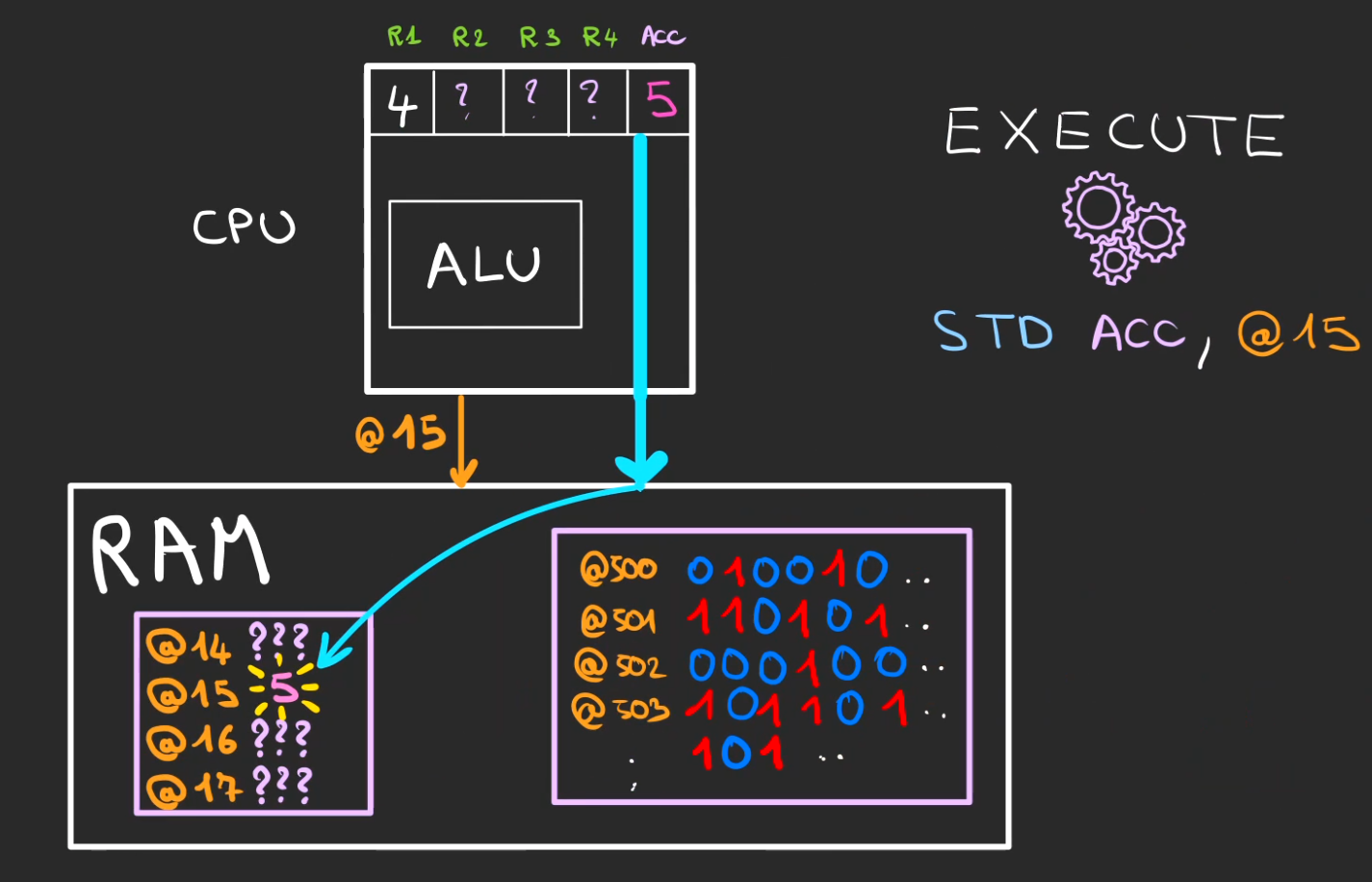
Le CPU va adresser la RAM pour que la valeur 5 contenue dans l'accumulateur soit stockée à l'adresse @15.
Ligne suivante, on fait le chemin inverse, on demande de charger le contenu de l'adresse @15 dans le registre R1.
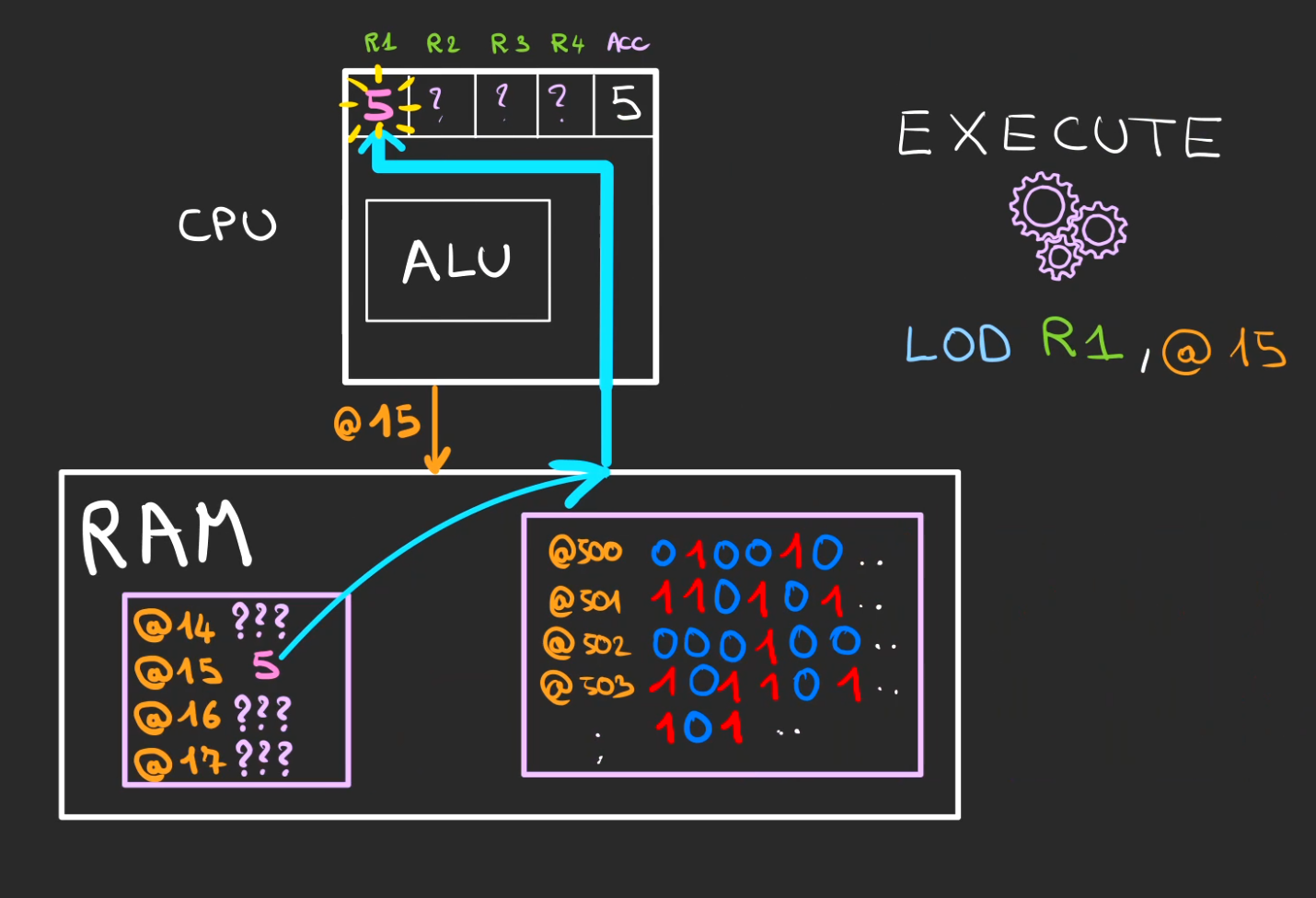
Nous avons maintenant 5 à la place de 1 dans le registre R1
On déroule.
Nous devons déplacer ce qui est dans R1 dans R2. Facile.
MOV R2, R1
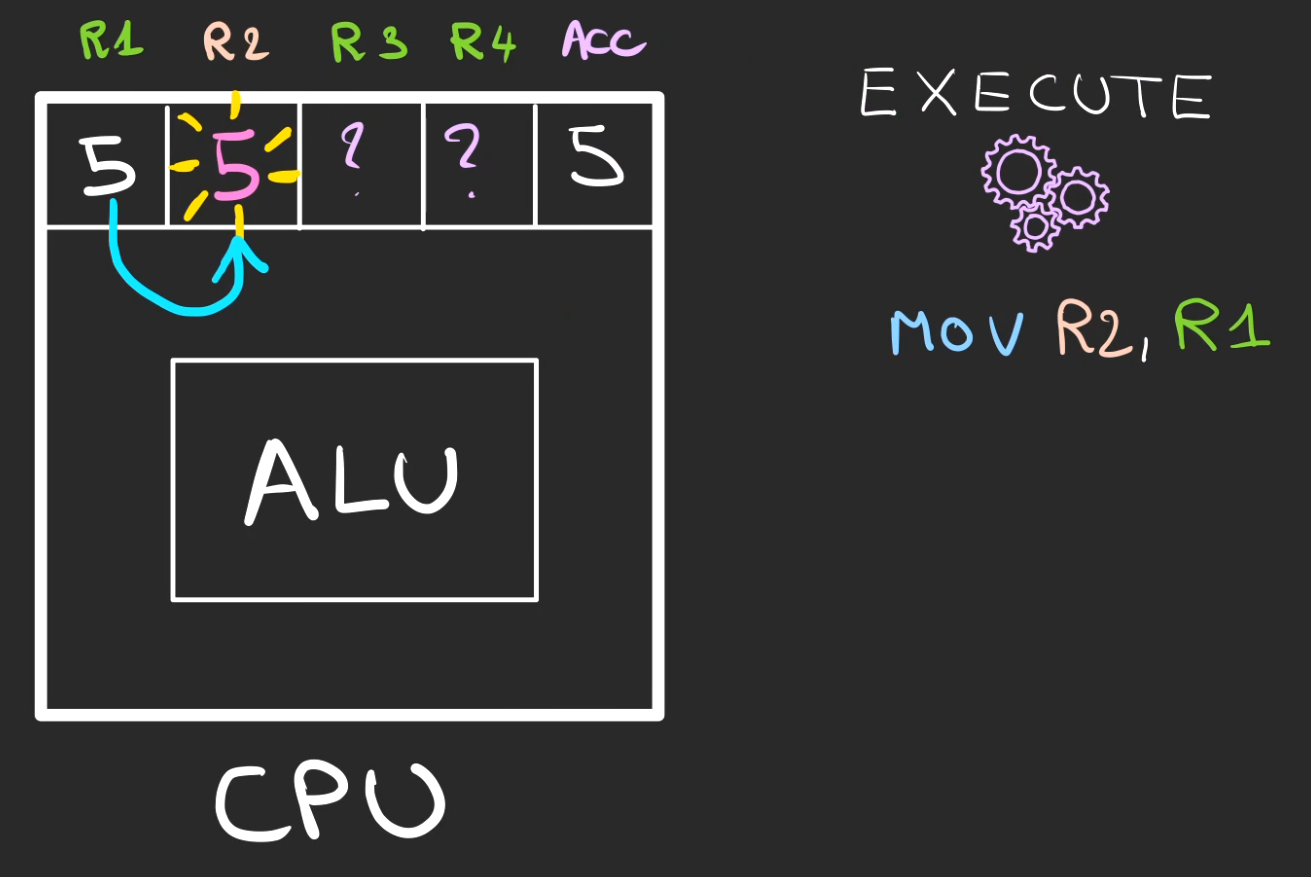
Nous avons maintenant 5 dans le registre R2.
Plus difficile, nous avons utilisé les registres, l'ALU, la RAM, mais pas encore les périphériques.
Nous allons demander d'écrire le contenu du registre R2 sur le périphérique #12.
Ici, nous allons dire que c'est du disque dur.
Chaque périphérique est un micro ordinateur, qui possède également des registres.
OUT R2, #12
Vient écrire sur le périphérique en voie 1 dans le registre X2, la valeur contenue par le registre R2.
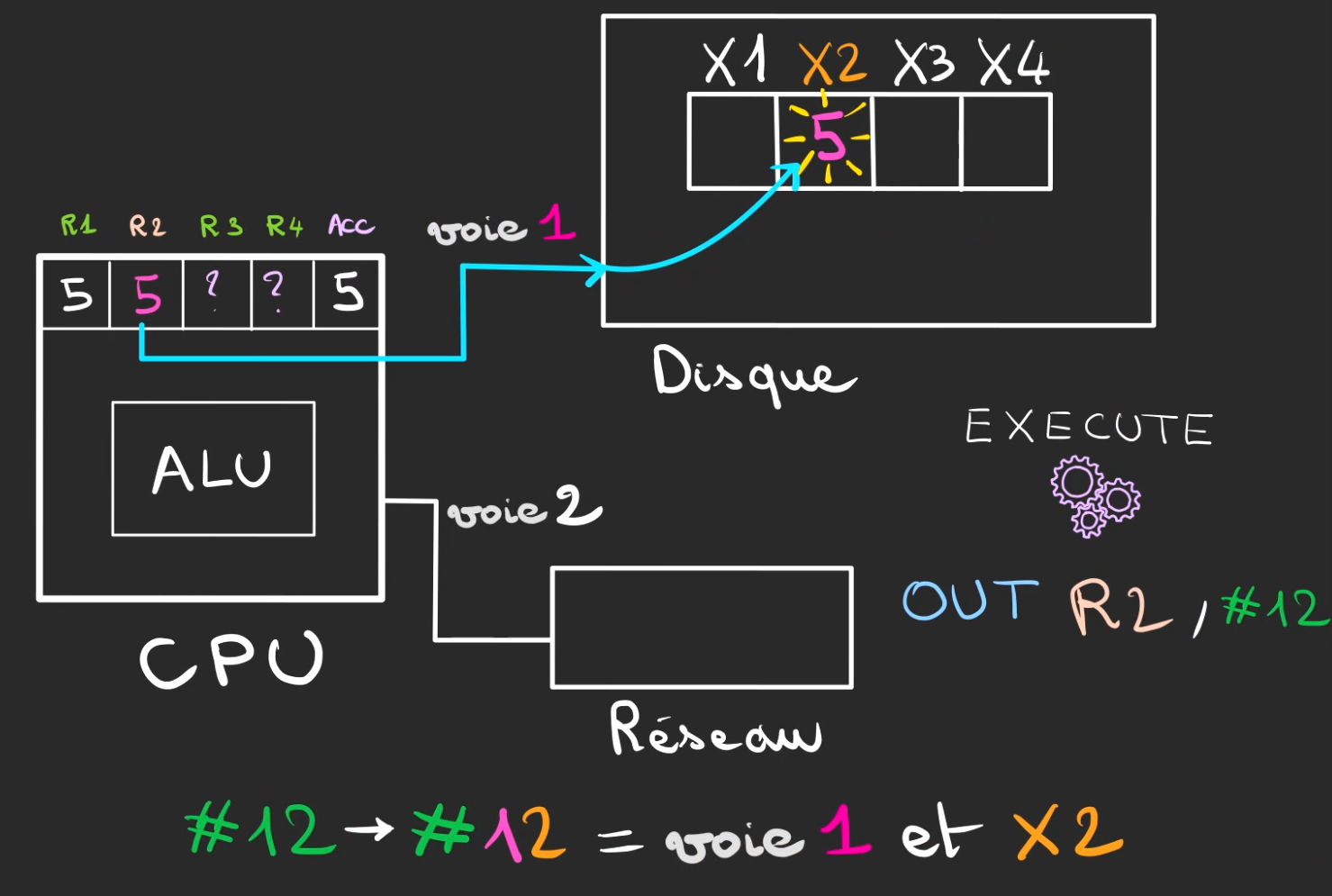
5 est maintenant écrit dans le registre, le disque viendra alors faire quelque chose avec cette valeur, mais ceci est hors scope de notre article.
La dernière instruction, éteint le CPU.
HLT
Multi-Processus
Race condition
Généralement, nous n'avons pas qu'un seul programme qui tourne sur un ordinateur.
Chacun de ces programmes sont stockés dans la RAM à des addresses différentes.
- Notre programme 1 débute à l'adresse
@126 - Tandis que le programme 2 à l'adresse
@500
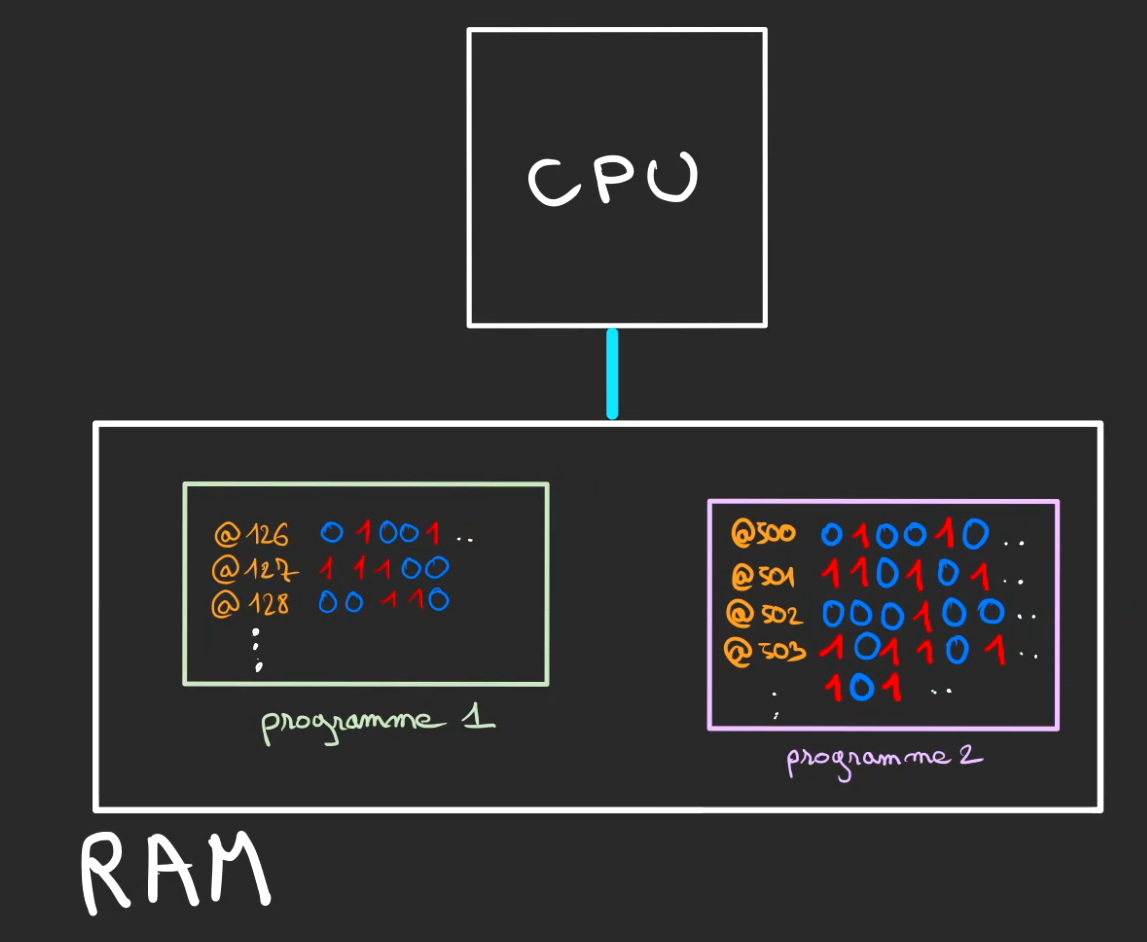
Comme nous n'avons qu'un seul CPU, et qu'il ne peut pas faire deux choses en même temps, il faut faire les choses de manière séquentielle.
Nous allons départager le temps que nous passons dans chaque programme.
D'ailleurs lorsqu'un programme tourne, nous allons l'appeler un processus.
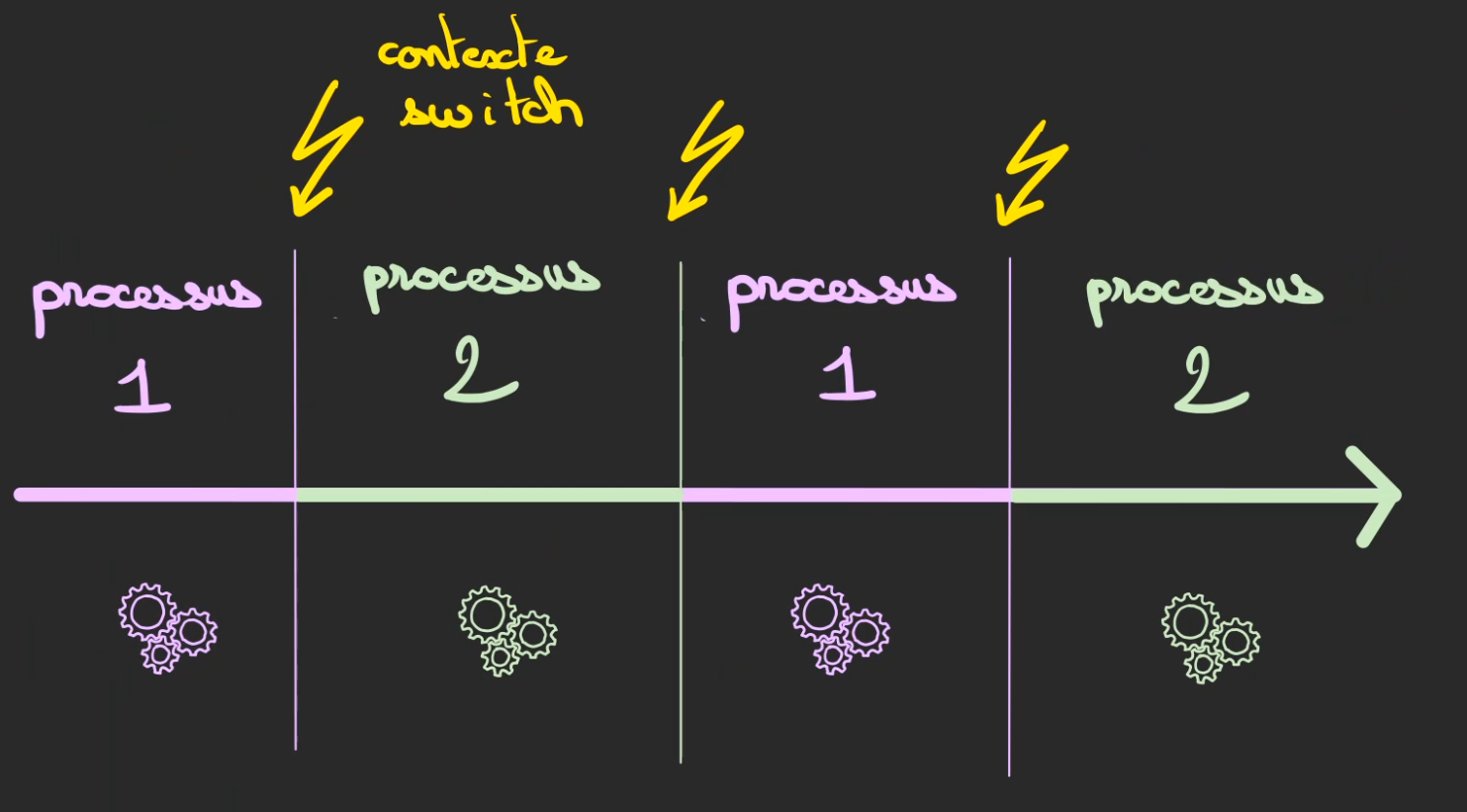
Chaque passage entre processus sera appelé un context switch, on verra par la suite de quoi il en retourne.
Voici les deux programmes en questions.
Maintenant expert en assembleur, vous devriez les comprendre. ^^

On accélère la montre pour se placer à l'instruction
STD ACC, @15
du programme 1, celle-ci écrit comme tout à l'heure la valeur 5 à l'adresse @15.
C'est alors qu'intervient le context switch, le processus 1 doit laisser la main au processus 2.
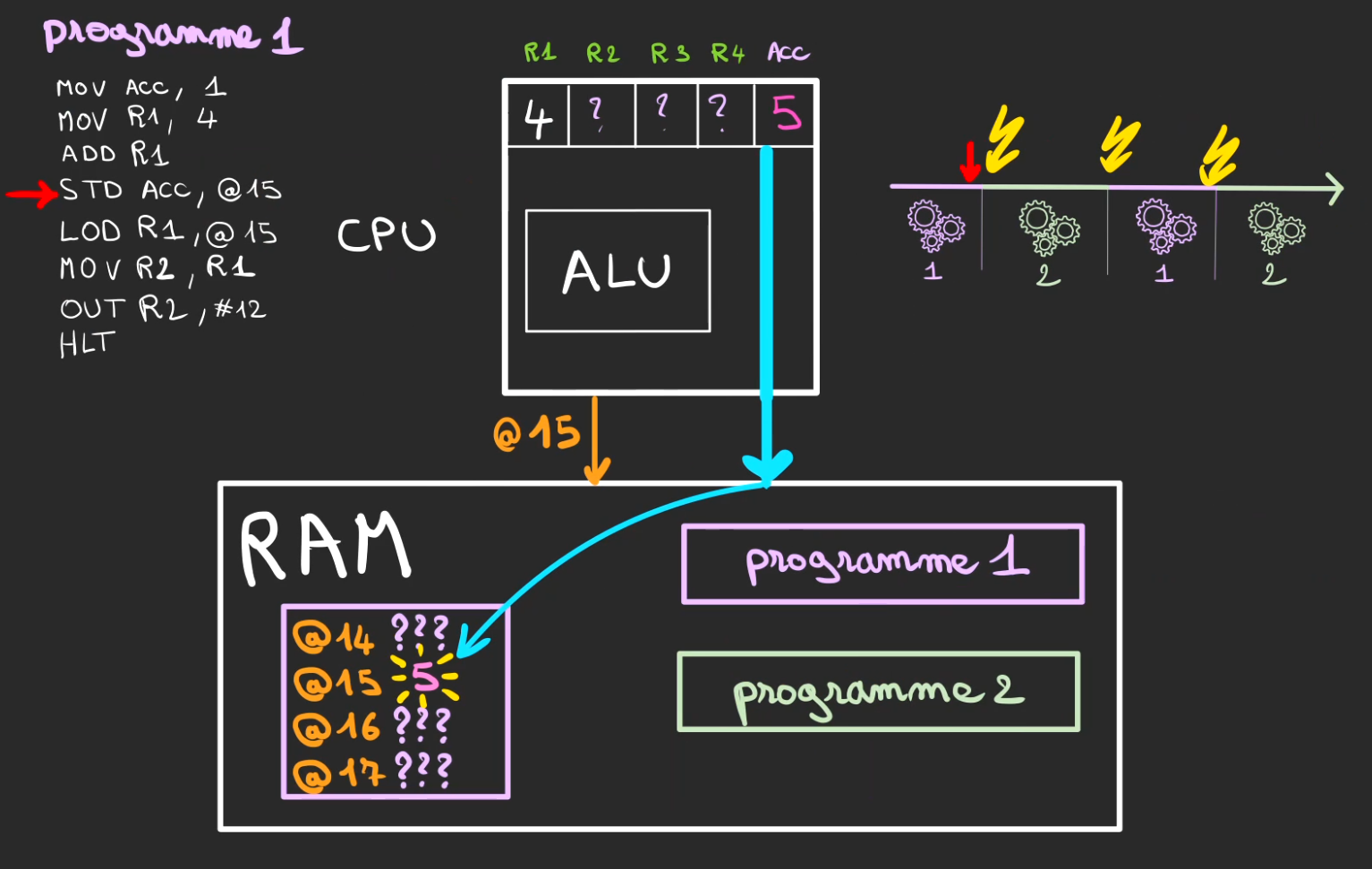
Nous sommes juste avant le début du programme 2, le switch de contexte ne peut pas faire grand chose, il est sensé remettre les valeurs du contexte d'exécution du processus 2.
Mais comme le programme n'a jamais tourné, c'est plus du bruit qui est défini ou bien les valeurs précédentes restent inchangées.
En tout cas, en l'état le processus 2, ne sait pas ce qu'il y a dans les registres.
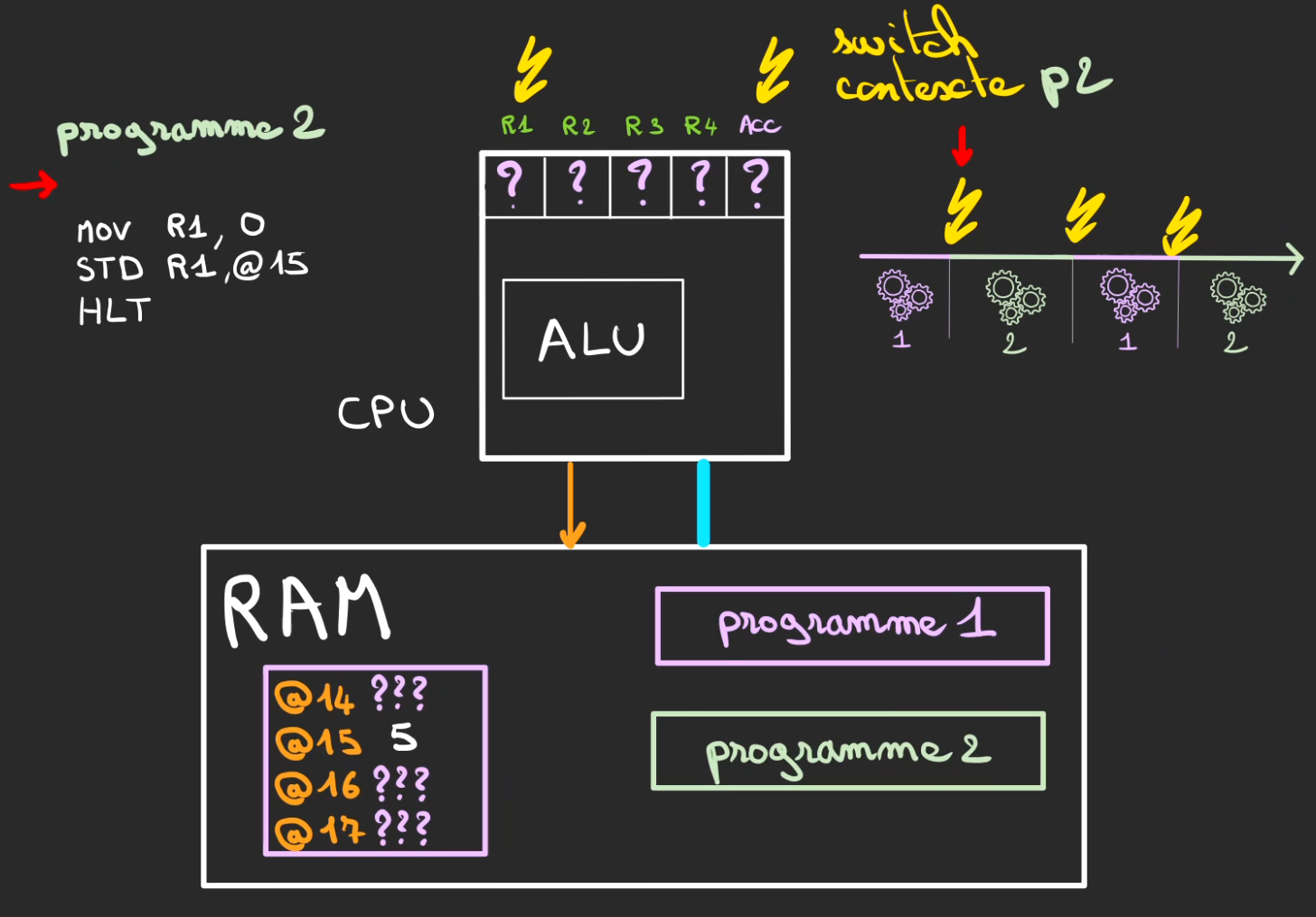
Le programme 2 se déroule et atteint une instruction étrangement familière.
STD R1, @15
Comme un ordinateur est déterministe, une même action, provoque le même résultat.
A ceci prêt que l'opération précédente avait défini la valeur de R1 comme étant 0
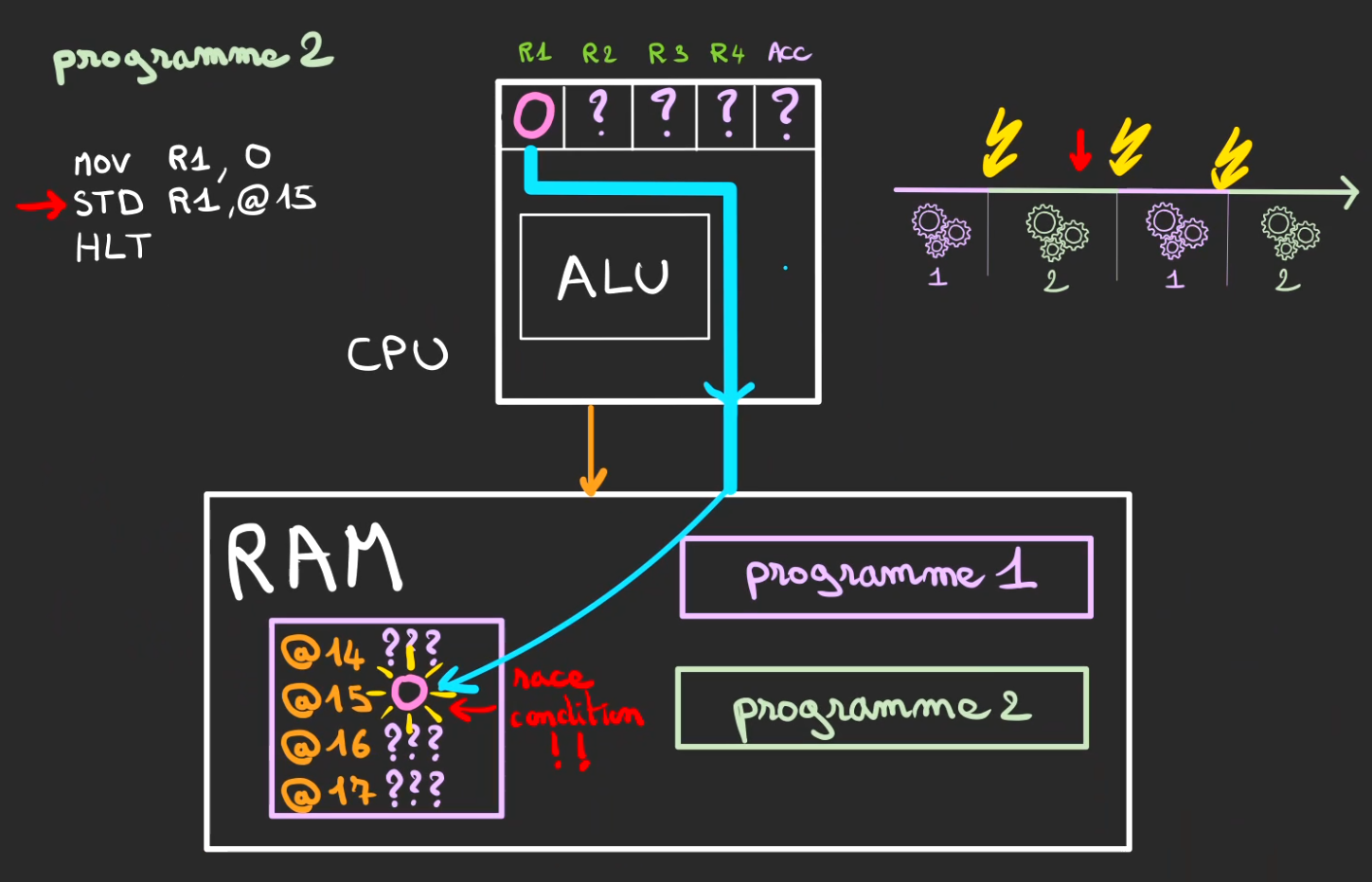
Donc maintenant l'adresse @15 vaut 0 !!!
Nous venons de créer une race condition : deux acteurs qui utilisent la même ressources sans se synchroniser sur l'écriture.
Temps écoulé pour le processus 2, il passe la main.
Le context switch restaure les états des registres pour que le processus 1 puisse de nouveau travailler.
On remet :
- 4 dans le registre R1
- 5 dans l'accumulateur
On restaure également le pointeur d'exécution.
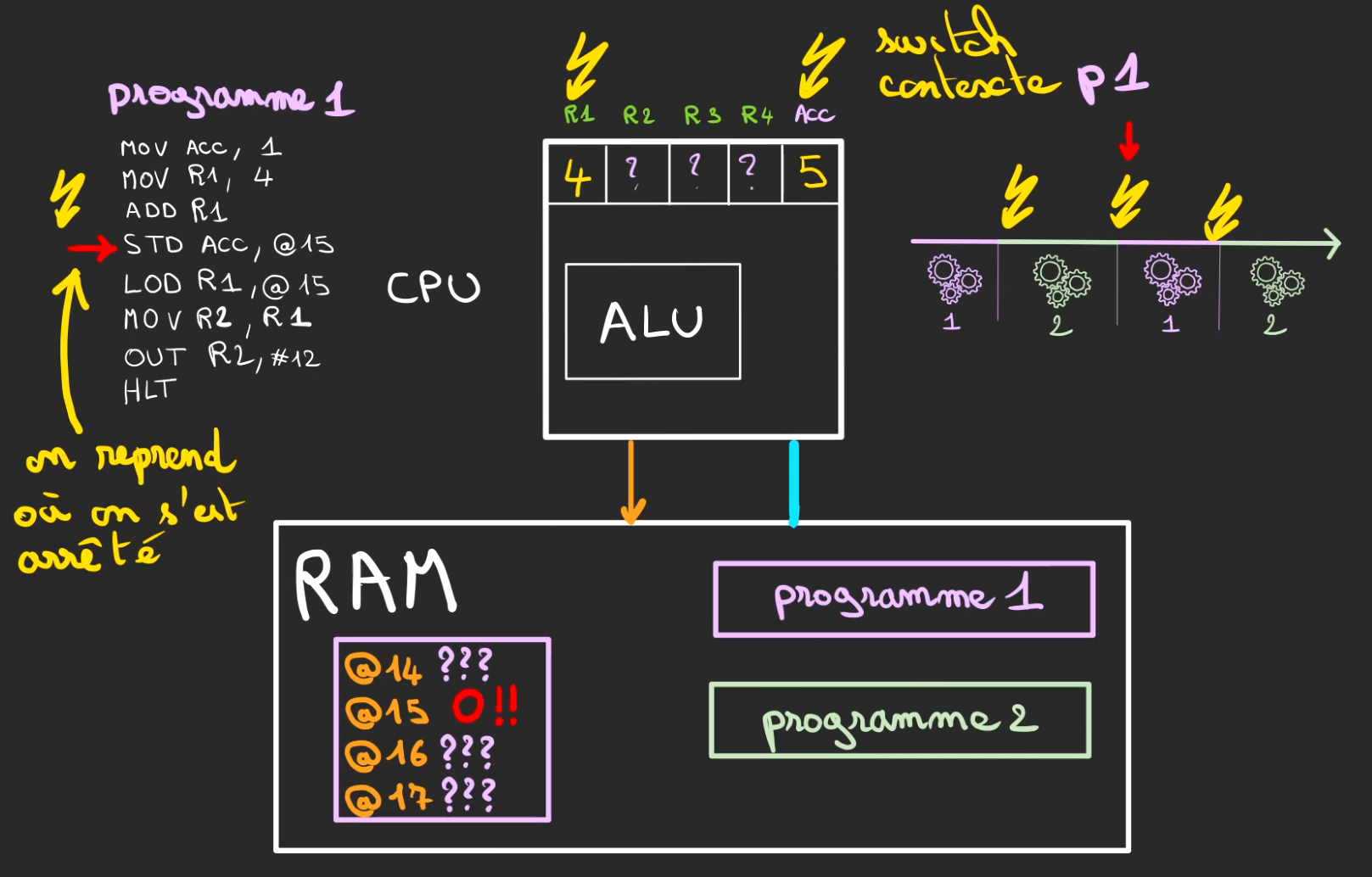
On incrémente le curseur d'exécution.
LOD R1, @15
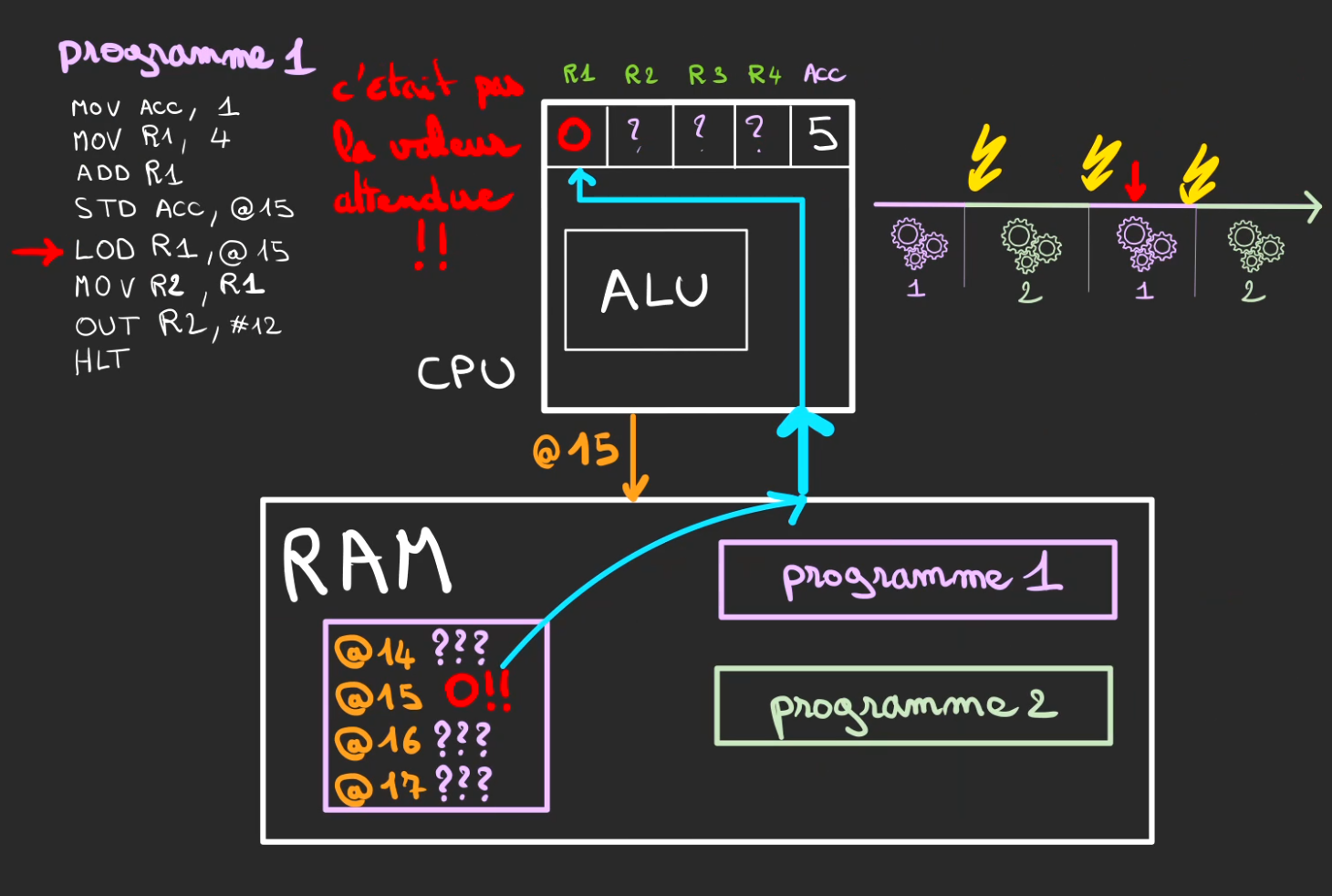
Ah bah oui, mais non ...
Le 5 n'est plus là. Il a été précédemment remplacé.
Le programme 1, n'est désormais plus déterministe, il est capable de faire n'importe quoi.
Echec et mat !
Sommes-nous condamner à n'exécuter qu'un seul programme par CPU.
Non, biensûr que non.
Mais pour ça, nous allons avoir besoin de plus de choses.
Kernel et MMU
Il va nous falloir un chef de gare pour gérer un peu la discipline dans les rangs.
Je vous le présente, il s'agit du Kernel.

Son rôle va être de gérer les processus et de les empêcher de faire n'importe quoi.
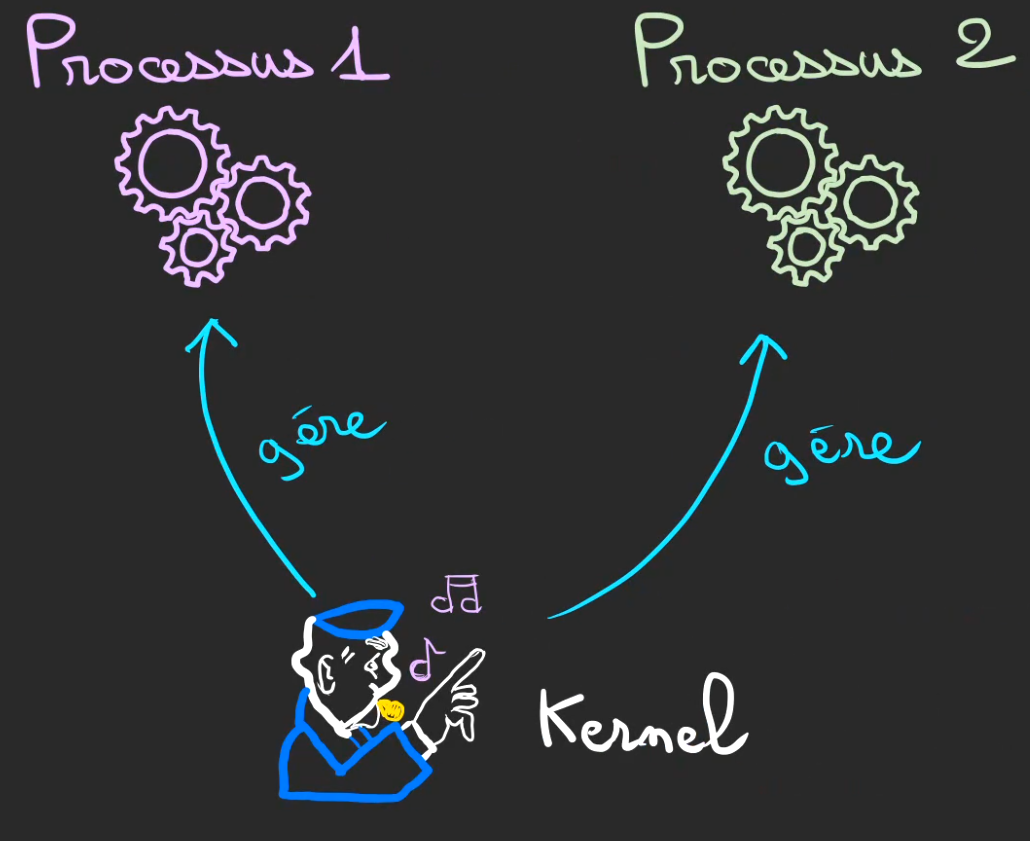
Et par n'importe quoi, je veux dire écrire n'importe où dans la mémoire.
Le but étant d'éviter la race condition, mais plus généralement que chaque processus reste chez lui et ne puisse pas aller taper de la mémoire qui ne lui appartient pas ou qui est déjà utilisée.
Il a encore un milliard de rôles différents supplémentaires, mais on reste simple, c'est de la vulgarisation, pas un cours.
Pour l'aider dans sa tâche de cloisonnement, le Kernel peut faire appel à un outil.
Celui-ci se nomme la Memory Management Unit.

Il s'agit globalement d'une liste d'adresse virtuelles qui pointent sur des adresses physique.
Pourquoi virtuelle ? Parce qu'elles n'ont aucune existence physique, elle n'existent pas dans la RAM, au contraire de l'adresse physique, qui est et bien physiquement présente dans le silicium.
Pour permettre de s'y retrouver et aussi d'avoir plusieurs fois la même adresse virtuelle pour deux adresses physiques différentes, on découpe la MMU en tables.
Ici par exemple on a deux tables, dans ces deux tables l'adresses virtuelle 15 existe, mais ne pointe pas vers la même adresse physique.

Dans la table 1
$$15 \Rightarrow 1005$$
Dans la table 2
$$15 \Rightarrow 22$$
La MMU est un composant physique à la différence du Kernel qui est du logicielle.
La MMU en action
Nous allons utiliser cette propriété pour résoudre notre problème de tout à l'heure.
Revenons dans le temps.
Nous sommes dans le processus 1, juste avant le stockage de la valeur en RAM.
Nous allons interposer la MMU sur le chemin du bus d'adressage.
Le CPU fait ce qu'il faisait avant, demander de stocker à l'adresse @15, mais la MMU est configurée par le Kernel pour utiliser la table p1.
Ainsi, l'adresse subit la modification suivante:
$$15 \Rightarrow 1013$$
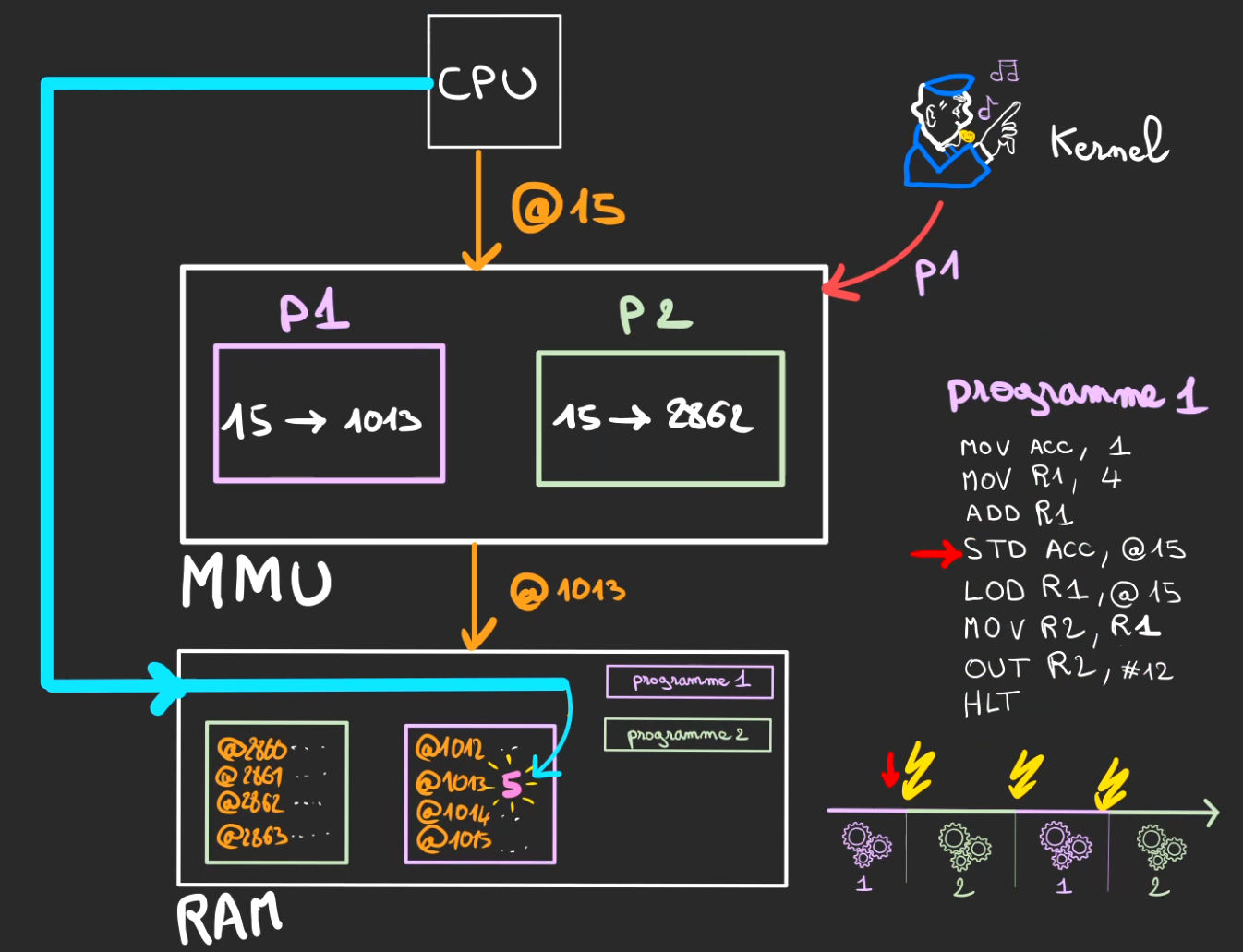
Notre 5 est alors stocké à l'adresse physique @1013 et non @15.
Cette fois-ci, c'est au processus 2 de vouloir stocker son 0 à l'adresse @15.
Mais même principe, le Kernel défini la table de la MMU sur p2.
Ainsi, l'adresse réellement utilisée devient
$$15 \Rightarrow 2862$$
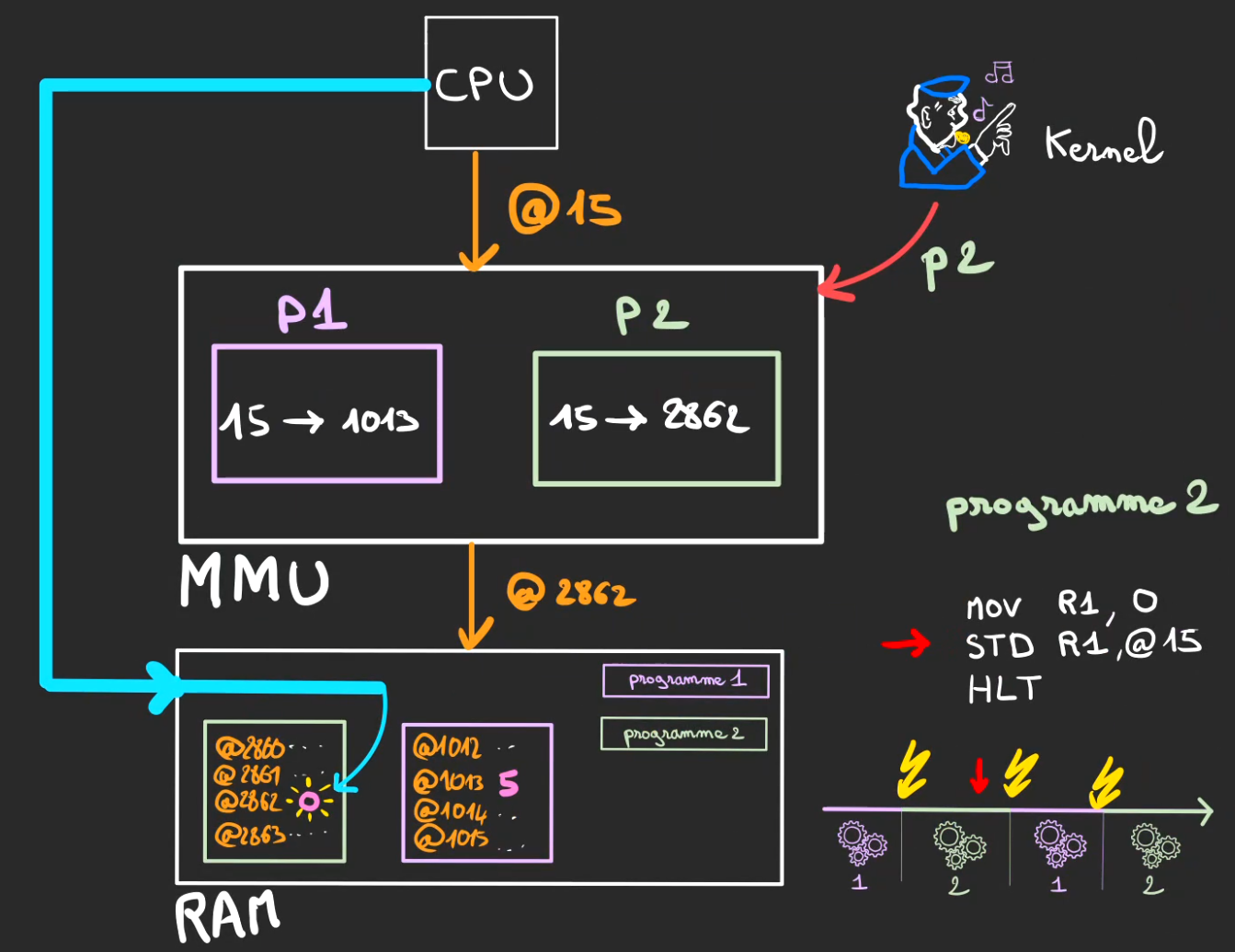
Son 0 est alors stocké à l'adresse physique @2862 et non @15.
Lorsque le processus 1 revient à la vie.
Il va lors du chargement de l'adresse @15, là aussi passer par le MMU.
Ainsi ce n'est pas @15 mais à nouveau @1013 qui est utilisé pour adresser la RAM.
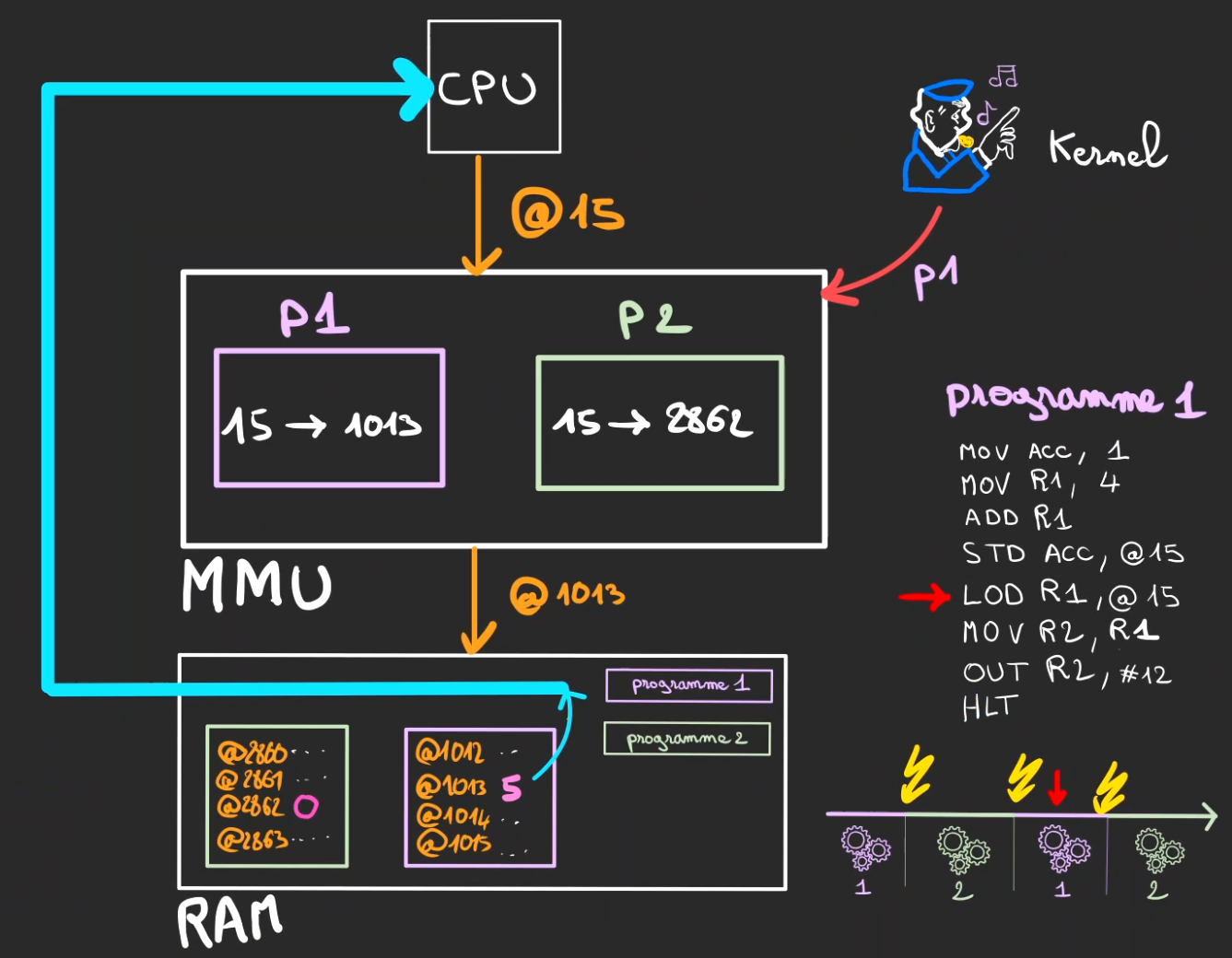
Et donc c'est bien un 5 et non un 0 qui est désormais stocké dans le registre R1.
Le programme peut de nouveau continuer. 🌞
La MMU est un composant physique.
La MMU est une partie essentielle de la sécurité d'un ordinateur, sans lui un programme malveillant ou mal conçu pourrait réécrire la mémoire d'un autre programme ou même le programme lui-même.
Du fait que l'isolation soit matérielle, cela rend très difficile le contournement de la sécurité.
Syscall
De la même manière que nous ne voulons pas qu'un processus prenne la main sur la mémoire de ses petits camarades, nous allons isoler nos processus de l'accès direct aux ressources physiques.
Pour 2 raisons:
- Un programme ne sait pas forcément parler "Disque dur"
- On veut pas qu'il puisse effacer ce qu'il veut le Kernel compris (oui les programmes sont sur disque avant d'arriver dans la RAM ^^)
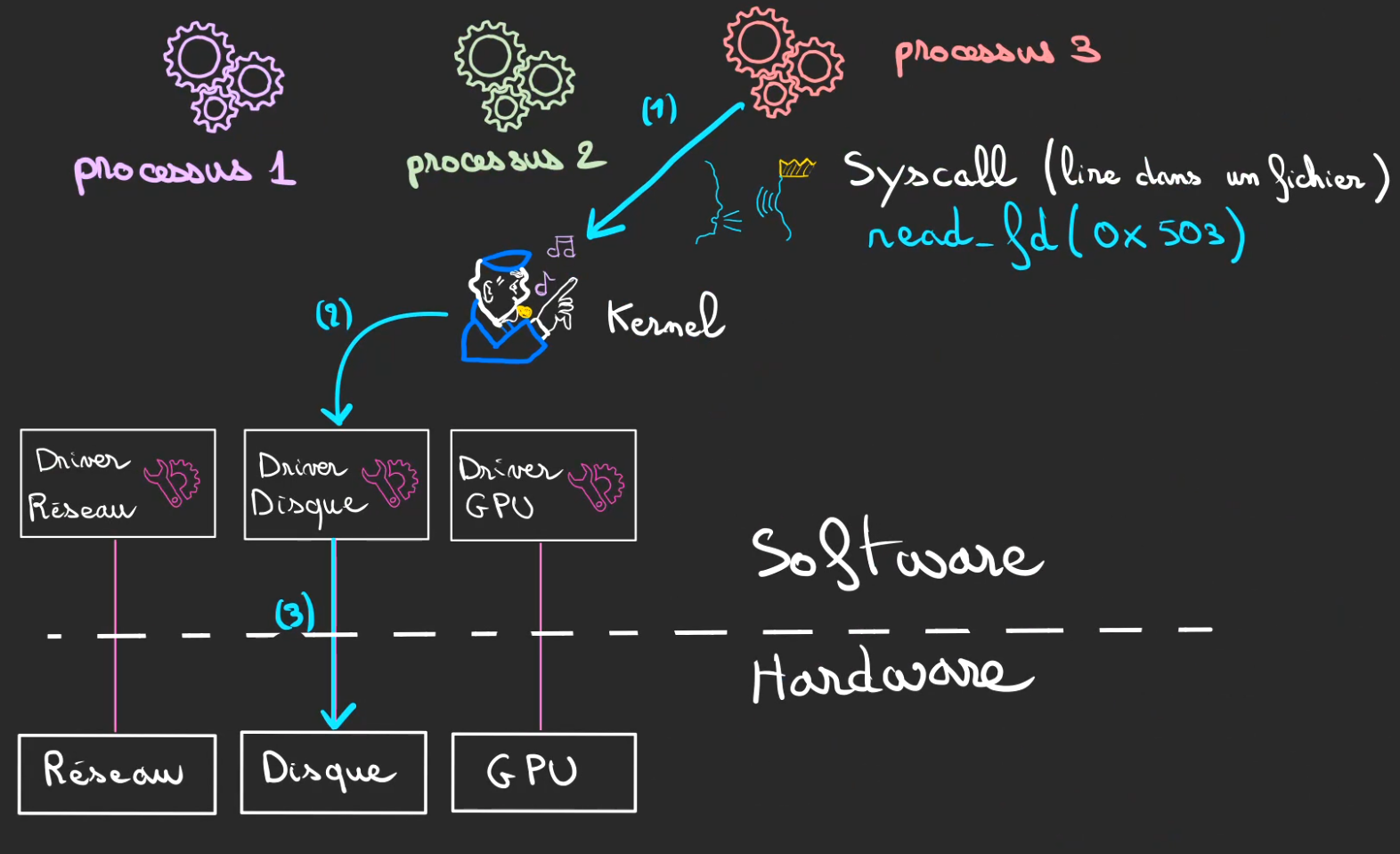
Lorsque qu'un processus désire réaliser une manipulation qui nécessite autre chose que de la RAM, ce processus va réaliser une doléance au Kernel, cette demande est appelée un Syscall.
Le syscall que nous allons utiliser se nomme read. Son boulot est demander la lecture d'une ressource un fichier par exemple qui serait sur le disque dur.
Mais de la même manière que le processus ne savait pas parler "Disque Dur", le Kernel ne sait pas non plus.
Heureusement, le Driver lui parle à la fois Kernel et Disque Dur, se sera donc notre interprète dans la transaction.
Pour les besoins du dessin je simplifie tout, mais il y a bien plus de chose à dire ^^
Détaillons ce qu'il se passe lors de la lecture de ce fichier.

Le processus vient définir qu'il a besoin en mettant l'information dans un registre (ici pour l'exemple R2 ), le nombre est ce qu'on appelle un file descriptor, c'est un identifiant qui est connu du Kernel et qu'il associe à une ressource, ici un fichier déjà ouvert par un précédent syscall open.
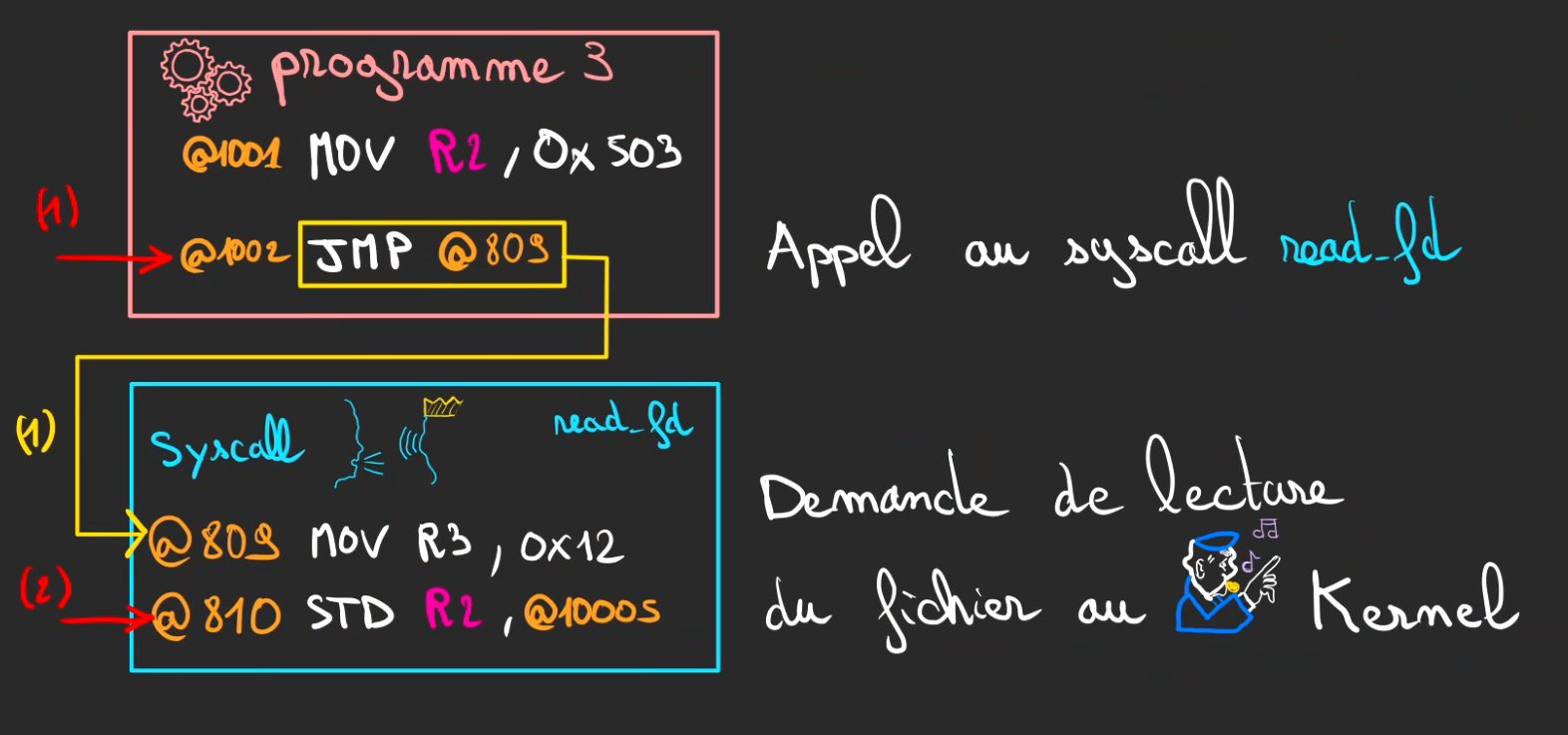
Un JMP est une instruction appelée un Jump, celui-ci vient déplacer le curseur d'exécution à l'adresse définie ici @809 qui correspond au début de notre syscall imaginaire et simplifié read_fd.
Le syscall fait des trucs, dont stocker de la donnée à l'adresse @10005.
C'est alors que des mécanismes un peu complexes et que je n'ai pas totalement saisis vont aller réveiller le Kernel qui piquait une sieste en attendant qu'il se passe quelque chose d'intéressant.
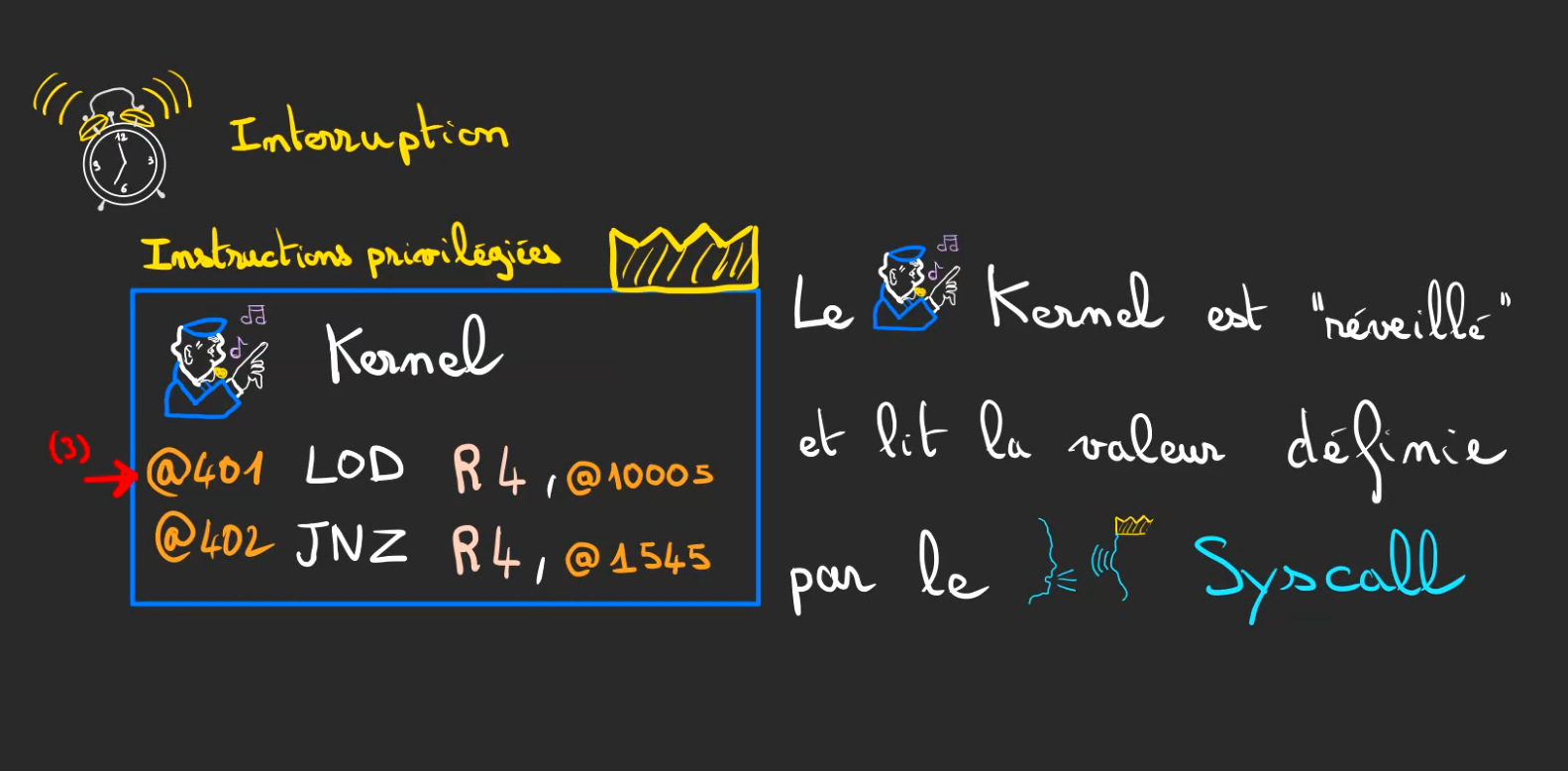
Cette magie noire se nomme une interruption.
Les instructions qui vont suivre sont appelées privilégiées car elle ne peuvent être exécuté que dans un mode spécifique du CPU, mode qui ne peut être atteint que par le Kernel et ses modules dont les drivers.
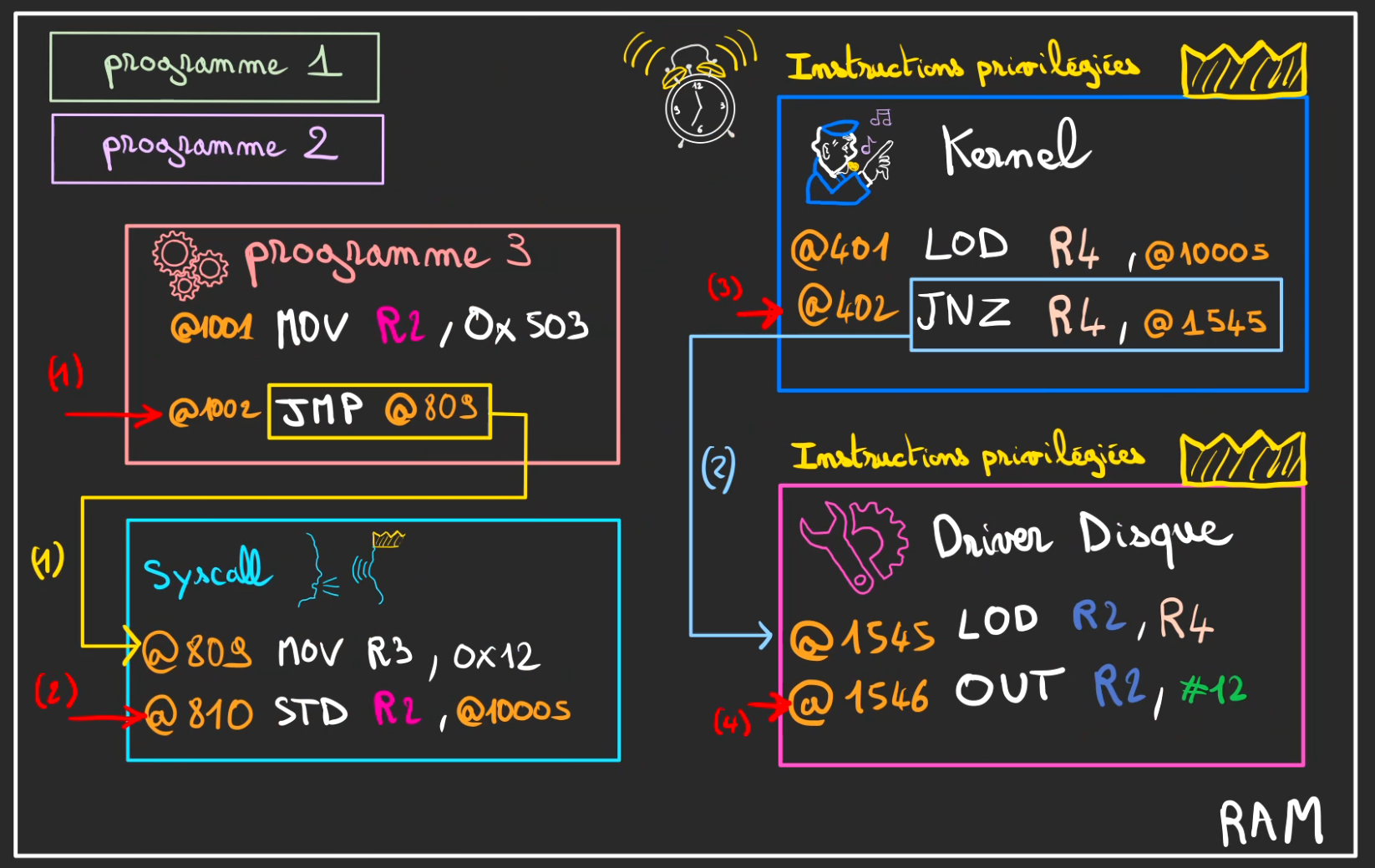
Il va alors faire ce que le syscall lui demande, lire le fichier, mais comme il ne sait toujours pas parler Disque dur, il fait appel au Driver qui lui sait.

Finalement le Disque dur est lu, au travers de l'opération
OUT R2, #12
Le trajet de retour vers le processus est une autre histoire, peut-être un jour dans un autre article ^^"
Petit récapitulatif de ce qui s'est déroulé.
Conclusion
Ainsi s'achève la première partie de notre épopée dans la Virtualisation, vous avez l'intuition de ce qui se passe dans un ordinateur physique.
Dans la seconde partie on commencera à esquisser le fonctionnement de la virtualisation elle même.
Merci de votre lecture ♥️
Ce travail est sous licence CC BY-NC-SA 4.0.